VideoTIR: Accurate Understanding for Long Videos with Efficient Tool-Integrated Reasoning
Pith reviewed 2026-05-15 00:41 UTC · model grok-4.3
The pith
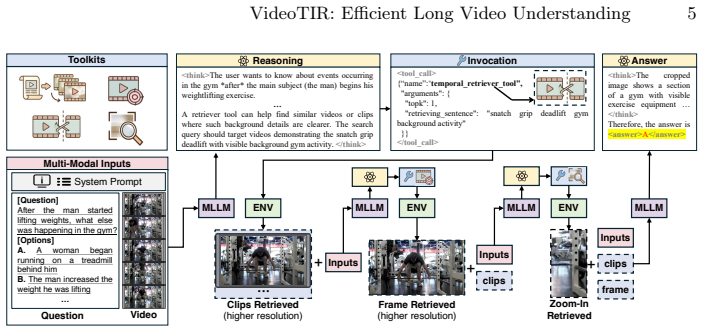
VideoTIR trains multimodal models with reinforcement learning to call tools that isolate key segments in long videos.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
VideoTIR shows that reinforcement learning on sandbox-generated trajectories enables MLLMs to learn reliable tool-calling behavior for retrieving meaningful segments, images, and regions, thereby improving long-video understanding without the extensive high-quality annotation required by previous SFT-based tool-calling systems.
What carries the argument
Toolkit Action Grouped Policy Optimization (TAGPO) combined with sandbox-based trajectory synthesis, which supplies stepwise rewards and reuses failed rollouts to train efficient multi-level tool usage.
If this is right
- Long-video question-answering accuracy improves because the model processes only selected segments instead of full sequences.
- Computational cost drops as redundant visual tokens are avoided through learned tool calls.
- The same RL setup can be applied to other toolkits that parse video at different granularities.
- Models become less dependent on massive supervised datasets for tool-use behavior.
Where Pith is reading between the lines
- The approach may extend to streaming video by reusing the same reward structure for incremental tool decisions.
- Sandbox trajectory generation could be adapted to create training data for tool use in other domains such as document or audio analysis.
- If the learned policies transfer across different MLLM backbones, the method would reduce the need for per-model supervised fine-tuning.
Load-bearing premise
Reinforcement learning on trajectories produced inside a sandbox will yield stable tool-calling policies without the need for large volumes of human-curated fine-grained data.
What would settle it
A direct comparison on the same long-video QA benchmarks where VideoTIR models produce more hallucinations or more redundant tool calls than strong SFT baselines would falsify the central claim.
Figures







read the original abstract
Existing Multimodal Large Language Models (MLLMs) often suffer from hallucinations in long video understanding (LVU), primarily due to the imbalance between textual and visual tokens. Observing that MLLMs handle short visual inputs well, recent LVU works alleviate hallucinations by automatically parsing the vast visual data into manageable segments that can be effectively processed by MLLMs. SFT-based tool-calling methods can serve this purpose, but they typically require vast amounts of fine-grained, high-quality data and suffer from constrained tool-calling trajectories. We propose a novel VideoTIR that leverages Reinforcement Learning (RL) to encourage proper usage of comprehensive multi-level toolkits for efficient long video understanding. VideoTIR explores both Zero-RL and SFT cold-starting to enable MLLMs to retrieve and focus on meaningful video segments/images/regions, enhancing long video understanding both accurately and efficiently. To reduce redundant tool-calling, we propose Toolkit Action Grouped Policy Optimization (TAGPO), which enhances the efficiency of the calling process through stepwise reward assignment and reuse of failed rollouts. Additionally, we develop a sandbox-based trajectory synthesis framework to generate high-quality trajectories data. Extensive experiments on three long-video QA benchmarks demonstrate the effectiveness and efficiency of our method.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes VideoTIR, an RL-based framework (exploring both Zero-RL and SFT cold-start) that trains MLLMs to use multi-level toolkits for long video understanding. It introduces Toolkit Action Grouped Policy Optimization (TAGPO) for stepwise reward assignment and reuse of failed rollouts to reduce redundant calls, plus a sandbox-based trajectory synthesis method to generate training data without relying on vast fine-grained SFT corpora. Experiments on three long-video QA benchmarks are reported to show gains in accuracy and efficiency over prior SFT tool-calling approaches.
Significance. If the central claims hold, the work would offer a data-efficient alternative to SFT for tool-integrated LVU, potentially lowering the barrier to reliable multi-level tool use in MLLMs while addressing token imbalance and hallucinations. The combination of RL with sandbox trajectories and grouped policy optimization could influence scalable video reasoning pipelines.
major comments (3)
- [§3.3] §3.3 (TAGPO): The description of stepwise reward assignment and failed-rollout reuse is given at a high level, but the exact reward formulation (e.g., how efficiency penalties are balanced against accuracy) and the mathematical definition of the grouped policy update are not provided. Without these, it is impossible to verify whether TAGPO avoids the circularity of rewarding tool use that the sandbox already biases toward.
- [§3.4] §3.4 (sandbox trajectory synthesis): The framework is claimed to produce high-quality, diverse trajectories that enable RL to outperform SFT data requirements. However, no quantitative characterization of trajectory diversity (e.g., coverage of video lengths, tool-call distributions, or failure modes) or ablation on sandbox curation choices is reported. This directly bears on the data-efficiency claim and generalization to the three QA benchmarks.
- [§4.2] §4.2 (experimental results): The reported improvements over SFT baselines are presented without disclosing the total number of sandbox-generated trajectories versus the scale of fine-grained SFT data used in comparators. This omission prevents assessment of whether the RL advantage is genuine or an artifact of unequal data budgets.
minor comments (2)
- [§1] The abstract and §1 use “comprehensive multi-level toolkits” without an early enumeration or diagram of the exact tool hierarchy (segment, image, region levels).
- [Figure 2] Figure 2 (method overview) would benefit from explicit arrows showing how TAGPO reuses failed rollouts in the training loop.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and the recommendation for major revision. We address each major comment below and will incorporate the requested details and analyses into the revised manuscript.
read point-by-point responses
-
Referee: [§3.3] §3.3 (TAGPO): The description of stepwise reward assignment and failed-rollout reuse is given at a high level, but the exact reward formulation (e.g., how efficiency penalties are balanced against accuracy) and the mathematical definition of the grouped policy update are not provided. Without these, it is impossible to verify whether TAGPO avoids the circularity of rewarding tool use that the sandbox already biases toward.
Authors: We thank the referee for this observation. In the revised manuscript we will expand §3.3 with the exact reward formulation (accuracy term plus explicit efficiency penalty) and the full mathematical definition of the grouped policy update used by TAGPO. On the circularity concern, the sandbox is used only to synthesize initial trajectories; the subsequent RL stage with TAGPO optimizes the policy to reduce redundant calls, which is reflected in the measured efficiency gains. We will add a short clarifying paragraph on this distinction. revision: yes
-
Referee: [§3.4] §3.4 (sandbox trajectory synthesis): The framework is claimed to produce high-quality, diverse trajectories that enable RL to outperform SFT data requirements. However, no quantitative characterization of trajectory diversity (e.g., coverage of video lengths, tool-call distributions, or failure modes) or ablation on sandbox curation choices is reported. This directly bears on the data-efficiency claim and generalization to the three QA benchmarks.
Authors: We agree that quantitative characterization is needed. In the revision we will add statistics on trajectory diversity (video-length coverage, tool-call distributions, and failure-mode coverage) together with an ablation study on sandbox curation choices and their effect on final performance across the three benchmarks. revision: yes
-
Referee: [§4.2] §4.2 (experimental results): The reported improvements over SFT baselines are presented without disclosing the total number of sandbox-generated trajectories versus the scale of fine-grained SFT data used in comparators. This omission prevents assessment of whether the RL advantage is genuine or an artifact of unequal data budgets.
Authors: We acknowledge the omission. In the revised §4.2 we will report the exact total number of sandbox-generated trajectories used for RL training and provide a direct comparison with the data scale of the SFT baselines, allowing readers to evaluate the data-efficiency claim. revision: yes
Circularity Check
No circularity: method proposal builds on external RL/tool ideas without self-referential reduction
full rationale
The paper proposes VideoTIR as a new RL-driven framework (Zero-RL and SFT cold-start variants) plus TAGPO and sandbox trajectory synthesis for long-video tool calling. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the derivation; the central claims rest on empirical results across three QA benchmarks rather than reducing by construction to the inputs. The approach extends existing MLLM and RL concepts without self-definitional loops or ansatz smuggling.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Authorea Preprints (2025) 2, 10, 12
Ahmed, I., Islam, S., Datta, P.P., Kabir, I., Chowdhury, N.U.R., Haque, A.: Qwen 2.5: A comprehensive review of the leading resource-efficient llm with potentioal to surpass all competitors. Authorea Preprints (2025) 2, 10, 12
work page 2025
-
[2]
Alayrac, J.B., Donahue, J., Luc, P., Miech, A., Barr, I., Hasson, Y., Lenc, K., Mensch, A., Millican, K., Reynolds, M., et al.: Flamingo: a visual language model for few-shot learning. NeurIPS (2022) 4
work page 2022
-
[3]
Chen, B., Yue, Z., Chen, S., Wang, Z., Liu, Y., Li, P., Wang, Y.: Lvagent: Long videounderstandingbymulti-rounddynamicalcollaborationofmllmagents.ArXiv (2025) 5
work page 2025
-
[4]
Chen, Z., Wu, J., Wang, W., Su, W., Chen, G., Xing, S., Zhong, M., Zhang, Q., Zhu, X., Lu, L., et al.: Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. In: CVPR (2024) 2, 12
work page 2024
-
[5]
Clark, C., Zhang, J., Ma, Z., Park, J.S., Salehi, M., Tripathi, R., Lee, S., Ren, Z., Kim, C.D., Yang, Y., Shao, V., Yang, Y., Huang, W., Gao, Z., Anderson, T., Zhang, J., Jain, J., Stoica, G., Han, W., Farhadi, A., Krishna, R.: Molmo2: Open weights and data for vision-language models with video understanding and grounding (2026) 2
work page 2026
-
[6]
Fan, Y., Ma, X., Wu, R., Du, Y., Li, J., Gao, Z., Li, Q.: Videoagent: A memory- augmented multimodal agent for video understanding. In: ECCV (2024) 2
work page 2024
-
[7]
Fan, Y., Ma, X., Wu, R., Du, Y., Li, J., Gao, Z., Li, Q.: Videoagent: A memory- augmented multimodal agent for video understanding. In: ECCV (2024) 5
work page 2024
-
[8]
Feng, K., Gong, K., Li, B., Guo, Z., Wang, Y., Peng, T., Wu, J., Zhang, X., Wang, B., Yue, X.: Video-r1: Reinforcing video reasoning in mllms. ArXiv (2025) 12
work page 2025
-
[9]
Fu, C., Dai, Y., Luo, Y., Li, L., Ren, S., Zhang, R., Wang, Z., Zhou, C., Shen, Y., Zhang, M., et al.: Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis. In: CVPR (2025) 4
work page 2025
-
[10]
GLM, T., Zeng, A., Xu, B., Wang, B., Zhang, C., Yin, D., Zhang, D., Rojas, D., Feng, G., Zhao, H., et al.: Chatglm: A family of large language models from glm-130b to glm-4 all tools. ArXiv (2024) 2, 3
work page 2024
-
[11]
Grauman, K., Westbury, A., Byrne, E., Chavis, Z., Furnari, A., Girdhar, R., Ham- burger, J., Jiang, H., Liu, M., Liu, X., et al.: Ego4d: Around the world in 3,000 hours of egocentric video. In: CVPR (2022) 4
work page 2022
-
[12]
Hu, K., Gao, F., Nie, X., Zhou, P., Tran, S., Neiman, T., Wang, L., Shah, M., Hamid, R., Yin, B., et al.: M-llm based video frame selection for efficient video understanding. In: CVPR (2025) 2
work page 2025
-
[13]
Jeoung, S., Huybrechts, G., Ganesh, B., Galstyan, A., Bodapati, S.: Adaptive video understanding agent: Enhancing efficiency with dynamic frame sampling and feedback-driven reasoning. ArXiv (2024) 5
work page 2024
-
[14]
Kugo, N., Li, X., Li, Z., Gupta, A., Khatua, A., Jain, N., Patel, C., Kyuragi, Y., Ishii, Y., Tanabiki, M., et al.: Videomultiagents: A multi-agent framework for video question answering. ArXiv (2025) 5
work page 2025
-
[15]
Lei, J., Berg, T.L., Bansal, M.: Detecting moments and highlights in videos via natural language queries. NeurIPS (2021) 11 16 Z. Gao et al
work page 2021
-
[16]
Li, K., Wang, Y., He, Y., Li, Y., Wang, Y., Liu, Y., Wang, Z., Xu, J., Chen, G., Luo, P., et al.: Mvbench: A comprehensive multi-modal video understanding benchmark. In: CVPR (2024) 4
work page 2024
-
[17]
Lin, B., Ye, Y., Zhu, B., Cui, J., Ning, M., Jin, P., Yuan, L.: Video-llava: Learning united visual representation by alignment before projection. In: EMNLP (2024) 4
work page 2024
-
[18]
Lin, J., Hua, H., Chen, M., Li, Y., Hsiao, J., Ho, C., Luo, J.: Videoxum: Cross- modal visual and textural summarization of videos. IEEE Trans. Multimed. (2023) 11
work page 2023
-
[19]
Liu, Y., Lin, K.Q., Chen, C.W., Shou, M.Z.: Videomind: A chain-of-lora agent for long video reasoning. ArXiv (2025) 2
work page 2025
-
[20]
Ma,Z.,Gou,C.,Shi,H.,Sun,B.,Li,S.,Rezatofighi,H.,Cai,J.:Drvideo:Document retrieval based long video understanding. In: CVPR (2025) 2
work page 2025
-
[21]
Ma,Z.,Gou,C.,Shi,H.,Sun,B.,Li,S.,Rezatofighi,H.,Cai,J.:Drvideo:Document retrieval based long video understanding. In: CVPR (2025) 5
work page 2025
-
[22]
Maaz, M., Rasheed, H., Khan, S., Khan, F.: Video-chatgpt: Towards detailed video understanding via large vision and language models. In: ACL (2024) 4
work page 2024
-
[23]
Mangalam, K., Akshulakov, R., Malik, J.: Egoschema: A diagnostic benchmark for very long-form video language understanding. NeurIPS (2023) 4
work page 2023
-
[24]
Shinn,N.,Cassano,F.,Gopinath,A.,Narasimhan,K.,Yao,S.:Reflexion:Language agents with verbal reinforcement learning. NeurIPS (2023) 5
work page 2023
-
[25]
Shu, Y., Liu, Z., Zhang, P., Qin, M., Zhou, J., Liang, Z., Huang, T., Zhao, B.: Video-xl: Extra-long vision language model for hour-scale video understanding. In: CVPR (2025) 12
work page 2025
-
[26]
Tong, Z., Song, Y., Wang, J., Wang, L.: Videomae: Masked autoencoders are data- efficient learners for self-supervised video pre-training. NeurIPS (2022) 4
work page 2022
-
[27]
Wang, P., Bai, S., Tan, S., Wang, S., Fan, Z., Bai, J., Chen, K., Liu, X., Wang, J., Ge, W., et al.: Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution. ArXiv (2024) 2, 4, 12
work page 2024
-
[28]
Wang,W.,He,Z.,Hong,W.,Cheng,Y.,Zhang,X.,Qi,J.,Ding,M.,Gu,X.,Huang, S., Xu, B., et al.: Lvbench: An extreme long video understanding benchmark. In: ICCV (2025) 1
work page 2025
-
[29]
Wang, X., Zhang, Y., Zohar, O., Yeung-Levy, S.: Videoagent: Long-form video understanding with large language model as agent. In: ECCV (2024) 2
work page 2024
-
[30]
Wang, Z., Blume, A., Li, S., Liu, G., Cho, J., Tang, Z., Bansal, M., Ji, H.: Paxion: Patching action knowledge in video-language foundation models. NeurIPS (2023) 10
work page 2023
-
[31]
Wang, Z., Chen, B., Yue, Z., Wang, Y., Qiao, Y., Wang, L., Wang, Y.: Videochat- a1: Thinking with long videos by chain-of-shot reasoning. ArXiv (2025) 5, 12
work page 2025
-
[32]
Weng, Y., Han, M., He, H., Chang, X., Zhuang, B.: Longvlm: Efficient long video understanding via large language models. In: ECCV (2024) 2
work page 2024
-
[33]
Wu,B.,Yu,S.,Chen,Z.,Tenenbaum,J.B.,Gan,C.:Star:Abenchmarkforsituated reasoning in real-world videos. ArXiv (2024) 10
work page 2024
-
[34]
Wu, C.Y., Feichtenhofer, C., Fan, H., He, K., Krahenbuhl, P., Girshick, R.: Long- term feature banks for detailed video understanding. In: CVPR (2019) 1
work page 2019
-
[35]
Wu, C.Y., Krahenbuhl, P.: Towards long-form video understanding. In: CVPR (2021) 1, 4
work page 2021
-
[36]
Xiao,J.,Shang,X.,Yao,A.,Chua,T.S.:Next-qa:Nextphaseofquestion-answering to explaining temporal actions. In: CVPR (2021) 4, 11
work page 2021
-
[37]
In: CVPR (2024) 11 VideoTIR: Efficient Long Video Understanding 17
Xiao, J., Yao, A., Li, Y., Chua, T.S.: Can i trust your answer? visually grounded video question answering. In: CVPR (2024) 11 VideoTIR: Efficient Long Video Understanding 17
work page 2024
-
[38]
Xie, Y., Chen, T., Ge, Z., Ni, L.: Video-mtr: Reinforced multi-turn reasoning for long video understanding. ArXiv (2025) 2, 3, 5, 6, 12
work page 2025
-
[39]
Xu, Z., Zhang, J., Wang, Q., Liu, Y.: E-vrag: Enhancing long video understanding with resource-efficient retrieval augmented generation. ArXiv (2025) 5
work page 2025
-
[40]
Xue, Z., Zheng, L., Liu, Q., Li, Y., Zheng, X., Ma, Z., An, B.: Simpletir: End-to- end reinforcement learning for multi-turn tool-integrated reasoning. ArXiv (2025) 11
work page 2025
-
[41]
Xue, Z., Zhang, J., Xie, X., Cai, Y., Liu, Y., Li, X., Tao, D.: Omni-adavideorag: Omni-contextual adaptive retrieval-augmented for efficient long video understand- ing. ArXiv (2025) 5
work page 2025
-
[42]
Yang, Z., Wang, S., Zhang, K., Wu, K., Leng, S., Zhang, Y., Li, B., Qin, C., Lu, S., Li, X., Bing, L.: Longvt: Incentivizing "thinking with long videos" via native tool calling (2025) 2, 5, 6, 12
work page 2025
-
[43]
Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K.R., Cao, Y.: React: Synergizing reasoning and acting in language models. In: ICLR (2022) 5
work page 2022
-
[44]
Yi, K., Gan, C., Li, Y., Kohli, P., Wu, J., Torralba, A., Tenenbaum, J.B.: Clevrer: Collision events for video representation and reasoning. ArXiv (2019) 10
work page 2019
-
[45]
Zhang, H., Li, X., Bing, L.: Video-llama: An instruction-tuned audio-visual lan- guage model for video understanding. ArXiv (2023) 4, 12
work page 2023
-
[46]
Zhang, Y.F., Lu, X., Yin, S., Fu, C., Chen, W., Hu, X., Wen, B., Jiang, K., Liu, C., Zhang, T., et al.: Thyme: Think beyond images. ArXiv (2025) 3
work page 2025
-
[47]
Zheng, Y., Zhang, R., Zhang, J., Ye, Y., Luo, Z., Feng, Z., Ma, Y.: Llamafactory: Unified efficient fine-tuning of 100+ language models. ArXiv (2024) 11
work page 2024
-
[48]
Zheng, Z., Yang, M., Hong, J., Zhao, C., Xu, G., Yang, L., Shen, C., Yu, X.: Deepeyes: Incentivizing" thinking with images" via reinforcement learning. ArXiv (2025) 3, 8
work page 2025
-
[49]
Zhong, Y., Hu, Z.Y., Li, Y., Wang, L.: Rethinking chain-of-thought reasoning for videos. Arxiv (2025) 12
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.