Revealing the Learning Dynamics of Long-Context Continual Pre-training
Pith reviewed 2026-05-13 20:15 UTC · model grok-4.3
The pith
Industrial-scale long-context continual pre-training requires over 150 billion tokens to reach true saturation instead of deceptive early plateaus.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
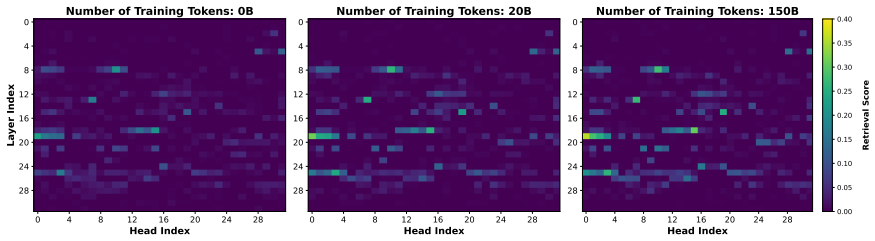
The central claim is that long-context continual pre-training on large models demands far more data than prior small-scale regimes, reaching intrinsic saturation only after more than 150 billion tokens. Traditional downstream benchmarks produce deceptive saturation signals early in training, whereas perplexity tracks continuous improvements and correlates more strongly with actual task performance. Attention patterns, particularly in retrieval heads, provide a mechanistic signal that monitors progress efficiently without requiring full supervised fine-tuning evaluations at every step.
What carries the argument
A hierarchical analysis framework that evaluates training at behavioral (supervised fine-tuning probing), probabilistic (perplexity), and mechanistic (attention patterns) levels, with retrieval heads serving as efficient monitors of long-context adaptation.
If this is right
- Data budgets for long-context adaptation must scale well beyond tens of billions of tokens to achieve full convergence in large models.
- Perplexity offers a more reliable basis for deciding when training has converged than needle-in-a-haystack scores alone.
- Attention scores from retrieval heads can serve as low-resource substitutes for expensive downstream evaluations during training.
- Training should continue past apparent benchmark plateaus to capture further intrinsic gains in long-context capability.
Where Pith is reading between the lines
- Multi-level monitoring could be built into training loops to set data-adaptive stopping criteria and reduce wasted compute on saturated runs.
- The observed scaling pattern may apply to other continual adaptation tasks, implying higher data needs whenever models must acquire new capabilities at scale.
- Data mixture adjustments guided by early retrieval-head signals might accelerate convergence without increasing total token count.
Load-bearing premise
The correlations between perplexity, retrieval head scores, and downstream performance observed here will hold for other model scales, architectures, and data distributions.
What would settle it
A replication run on a different large model where needle-in-a-haystack scores improve in step with perplexity reductions all the way past 150 billion tokens, or where all metrics saturate well before that point.
Figures







read the original abstract
Existing studies on Long-Context Continual Pre-training (LCCP) mainly focus on small-scale models and limited data regimes (tens of billions of tokens). We argue that directly migrating these small-scale settings to industrial-grade models risks insufficient adaptation and premature training termination. Furthermore, current evaluation methods rely heavily on downstream benchmarks (e.g., Needle-in-a-Haystack), which often fail to reflect the intrinsic convergence state and can lead to "deceptive saturation". In this paper, we present the first systematic investigation of LCCP learning dynamics using the industrial-grade Hunyuan-A13B (80B total parameters), tracking its evolution across a 200B-token training trajectory. Specifically, we propose a hierarchical framework to analyze LCCP dynamics across behavioral (supervised fine-tuning probing), probabilistic (perplexity), and mechanistic (attention patterns) levels. Our findings reveal: (1) Necessity of Massive Data Scaling: Training regimes of dozens of billions of tokens are insufficient for industrial-grade LLMs' LCCP (e.g., Hunyuan-A13B reaches saturation after training over 150B tokens). (2) Deceptive Saturation vs. Intrinsic Saturation: Traditional NIAH scores report "fake saturation" early, while our PPL-based analysis reveals continuous intrinsic improvements and correlates more strongly with downstream performance. (3) Mechanistic Monitoring for Training Stability: Retrieval heads act as efficient, low-resource training monitors, as their evolving attention scores reliably track LCCP progress and exhibit high correlation with SFT results. This work provides a comprehensive monitoring framework, evaluation system, and mechanistic interpretation for the LCCP of industrial-grade LLM.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts the first large-scale study of Long-Context Continual Pre-training (LCCP) on the 80B-parameter Hunyuan-A13B model across a 200B-token trajectory. It introduces a three-level analysis framework (SFT probing, perplexity, and attention-head mechanics) and reports that (1) saturation requires >150B tokens, (2) NIAH exhibits deceptive early saturation while PPL tracks continued intrinsic improvement, and (3) retrieval-head attention scores serve as efficient, low-cost monitors that correlate with downstream performance.
Significance. If the empirical patterns generalize, the work supplies concrete guidance for industrial LCCP by showing that conventional NIAH benchmarks can mislead training termination decisions and by demonstrating the utility of PPL and retrieval-head monitoring at scale. The 200B-token run on an 80B model constitutes a substantial empirical contribution that exceeds prior small-scale LCCP studies. The single-trajectory design, however, constrains the strength of the necessity claim for >150B tokens across architectures and data mixtures.
major comments (3)
- Abstract: The headline necessity claim that 'Training regimes of dozens of billions of tokens are insufficient for industrial-grade LLMs' LCCP' rests on a single 200B-token trajectory of Hunyuan-A13B; no replication, ablation across model scales, or alternative data mixtures is reported, rendering the general saturation threshold load-bearing yet unsupported.
- Abstract: No quantitative definition of saturation (e.g., PPL delta threshold, attention-score convergence criterion), error bars, or statistical tests accompany the 150B-token figure or the reported correlations among PPL, retrieval-head scores, and SFT accuracy, so the central empirical patterns cannot be independently verified.
- Results sections: The superiority of PPL-based monitoring over NIAH is asserted via observed correlations, yet the manuscript provides no cross-validation on held-out data distributions or other model families, leaving open the possibility that the 'deceptive saturation' phenomenon is idiosyncratic to the Hunyuan-A13B pre-training mixture.
minor comments (2)
- Abstract: The phrase 'industrial-grade' is used without an explicit size or compute threshold, making it difficult to assess how broadly the 150B-token finding is intended to apply.
- Throughout: Several figure captions and axis labels lack units or precise definitions (e.g., exact retrieval-head attention metric), reducing clarity for readers attempting to reproduce the monitoring protocol.
Simulated Author's Rebuttal
We thank the referee for their insightful comments. We address each major point below and indicate the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [—] Abstract: The headline necessity claim that 'Training regimes of dozens of billions of tokens are insufficient for industrial-grade LLMs' LCCP' rests on a single 200B-token trajectory of Hunyuan-A13B; no replication, ablation across model scales, or alternative data mixtures is reported, rendering the general saturation threshold load-bearing yet unsupported.
Authors: We recognize that the saturation threshold is based on a single trajectory, which limits claims of necessity across all settings. Given the substantial computational cost of LCCP at this scale, replication is not feasible in this work. We will revise the abstract to present the >150B token figure as an observation from our large-scale experiment on Hunyuan-A13B rather than a universal requirement, and we will add a limitations paragraph explicitly noting the single-trajectory constraint. revision: partial
-
Referee: [—] Abstract: No quantitative definition of saturation (e.g., PPL delta threshold, attention-score convergence criterion), error bars, or statistical tests accompany the 150B-token figure or the reported correlations among PPL, retrieval-head scores, and SFT accuracy, so the central empirical patterns cannot be independently verified.
Authors: We agree that a quantitative definition is needed for verifiability. In the revision, we will define saturation explicitly as the training step where the 5-epoch moving average of perplexity decreases by less than 0.01 over 20B tokens. We will report correlation coefficients (e.g., Pearson r) with p-values for PPL vs. SFT accuracy and retrieval-head scores vs. SFT, and include shaded regions representing standard deviation from windowed statistics on the trajectory to provide error estimates. revision: yes
-
Referee: [—] Results sections: The superiority of PPL-based monitoring over NIAH is asserted via observed correlations, yet the manuscript provides no cross-validation on held-out data distributions or other model families, leaving open the possibility that the 'deceptive saturation' phenomenon is idiosyncratic to the Hunyuan-A13B pre-training mixture.
Authors: The analysis is indeed performed on a single model and data mixture. However, the deceptive saturation is evidenced by the divergence between NIAH scores plateauing early while PPL continues to improve and better predicts SFT performance within our trajectory. We will revise the results to emphasize that this is a case study at industrial scale and discuss how the three-level framework could be applied to other settings. No additional cross-validation experiments will be added as they fall outside the current scope. revision: no
- The generalizability of the saturation threshold and monitoring methods to other model architectures and data mixtures due to the single-trajectory experimental design.
Circularity Check
No circularity: empirical measurements from single trajectory are independent
full rationale
The paper reports direct empirical observations from one 200B-token training run of Hunyuan-A13B. Perplexity, retrieval-head attention scores, and SFT accuracy are measured separately at each checkpoint with no equations, fitted parameters, or self-citations that reduce any reported quantity to its inputs by construction. The scaling claim (saturation after >150B tokens) and the comparison of NIAH vs. PPL are presented as observations from this trajectory, not as derivations or predictions forced by prior definitions. No self-definitional loops, ansatzes smuggled via citation, or uniqueness theorems appear in the provided text.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard assumptions in LLM training dynamics hold for large-scale continual pre-training.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Necessity of Massive Data Scaling: ... Hunyuan-A13B reaches saturation after training over 150B tokens. ... PPL-based analysis reveals continuous intrinsic improvements
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Retrieval heads act as efficient, low-resource training monitors, as their evolving attention scores reliably track LCCP progress
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Scaling Laws for Neural Language Models
Scaling laws for neural language models. arXiv preprint arXiv:2001.08361. Marzena Karpinska, Katherine Thai, Kyle Lo, Tanya Goyal, and Mohit Iyyer. 2024. One thousand and one pairs: A novel challenge for long-context lan- guage models. In Proceedings of the 2024 Con- ference on Empirical Methods in Natural Language Processing, pages 17048–17085. Nam Le Ha...
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[2]
In Findings of the Association for Computational Linguistics: NAACL 2025 , pages 1496–1524
On the impacts of contexts on repository- level code generation. In Findings of the Association for Computational Linguistics: NAACL 2025 , pages 1496–1524. Nelson F Liu, Kevin Lin, John Hewitt, Ashwin Paran- jape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. 2024. Lost in the middle: How language models use long contexts. Transactions of the Asso-...
-
[3]
Yijun Y ang, Zeyu Huang, Wenhao Zhu, Zihan Qiu, Fei Y uan, Jeff Z Pan, and Ivan Titov
OpenReview.net. Yijun Y ang, Zeyu Huang, Wenhao Zhu, Zihan Qiu, Fei Y uan, Jeff Z Pan, and Ivan Titov. 2025a. A control- lable examination for long-context language models. arXiv preprint arXiv:2506.02921. Yijun Y ang, Zeyu Huang, Wenhao Zhu, Zihan Qiu, Fei Y uan, Jeff Z. Pan, and Ivan Titov. 2025b. A control- lable examination for long-context language m...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.