Next-Scale Autoregressive Models for Text-to-Motion Generation
Pith reviewed 2026-05-13 17:24 UTC · model grok-4.3
The pith
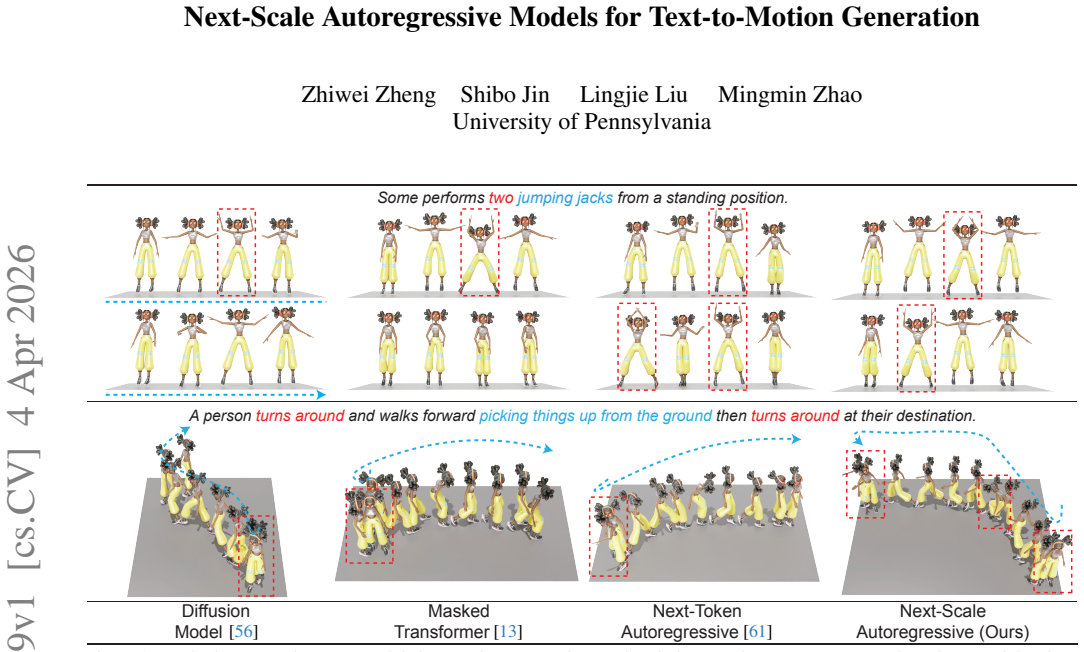
A next-scale autoregressive model generates text-to-motion sequences hierarchically from coarse to fine temporal resolutions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MoScale is a next-scale autoregressive framework that generates motion hierarchically from coarse to fine temporal resolutions. By providing global semantics at the coarsest scale and refining them progressively, MoScale establishes a causal hierarchy better suited for long-range motion structure. To improve robustness under limited text-motion data, it incorporates cross-scale hierarchical refinement for improving per-scale initial predictions and in-scale temporal refinement for selective bidirectional re-prediction.
What carries the argument
The next-scale autoregressive prediction process operating across multiple temporal resolutions, supported by cross-scale refinement of initial predictions and in-scale temporal refinement for bidirectional re-prediction.
If this is right
- The model reaches state-of-the-art performance on text-to-motion benchmarks.
- Training becomes more efficient than standard autoregressive baselines.
- Performance continues to improve as model size increases.
- The same model applies zero-shot to varied motion generation and editing tasks without task-specific retraining.
Where Pith is reading between the lines
- The coarse-to-fine hierarchy may transfer to other sequential data domains such as video synthesis where global context precedes local detail.
- Stronger structural priors could lower the amount of paired text-motion data needed for high-quality results.
- Editing at chosen scales might allow targeted adjustments to attributes such as timing or posture without regenerating entire sequences.
Load-bearing premise
That generating global semantics first at the coarsest scale and refining progressively creates a causal hierarchy that captures long-range motion structure better than standard next-token prediction.
What would settle it
A controlled comparison in which a standard next-token autoregressive model, trained on identical data and scaled to similar capacity, matches or exceeds MoScale on metrics of long-range motion coherence and text alignment.
Figures





read the original abstract
Autoregressive (AR) models offer stable and efficient training, but standard next-token prediction is not well aligned with the temporal structure required for text-conditioned motion generation. We introduce MoScale, a next-scale AR framework that generates motion hierarchically from coarse to fine temporal resolutions. By providing global semantics at the coarsest scale and refining them progressively, MoScale establishes a causal hierarchy better suited for long-range motion structure. To improve robustness under limited text-motion data, we further incorporate cross-scale hierarchical refinement for improving per-scale initial predictions and in-scale temporal refinement for selective bidirectional re-prediction. MoScale achieves SOTA text-to-motion performance with high training efficiency, scales effectively with model size, and generalizes zero-shot to diverse motion generation and editing tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MoScale, a next-scale autoregressive model for text-to-motion generation. It replaces standard next-token prediction with hierarchical generation from coarse to fine temporal scales, supplying global semantics at the coarsest level and refining progressively. Cross-scale hierarchical refinement and in-scale temporal refinement are added to improve robustness under limited data. The paper claims this yields SOTA text-to-motion performance, high training efficiency, effective scaling with model size, and zero-shot generalization to diverse motion generation and editing tasks.
Significance. If the central modeling assumption holds after proper isolation, the work could advance autoregressive sequence modeling for temporally structured data by demonstrating that scale-based causality better captures long-range motion dependencies than token-level prediction. The reported efficiency and zero-shot generalization would be practically valuable for animation and robotics applications.
major comments (2)
- [Abstract] Abstract: the assertion that 'providing global semantics at the coarsest scale and refining progressively' establishes a 'causal hierarchy better suited for long-range motion structure' than standard next-token prediction is load-bearing for all performance claims, yet no ablation is described that holds model capacity, training data, and the auxiliary refinement modules fixed while swapping only the prediction order (scale hierarchy vs. token order).
- [§4] §4 (Experiments): the SOTA, efficiency, and zero-shot generalization statements rest on comparisons whose details (exact baselines, training budgets, error bars, and statistical significance) are not provided in sufficient depth to confirm that gains arise from the claimed hierarchy rather than implementation choices.
minor comments (2)
- [Abstract, §3] Abstract and §3: the precise definitions and implementation of 'cross-scale hierarchical refinement' and 'in-scale temporal refinement' should be stated with pseudocode or a small diagram to avoid ambiguity for readers.
- [§5] §5 (Ablations or scaling): if scaling curves with model size are presented, include a direct comparison against a standard next-token AR baseline of matched capacity to quantify the hierarchy's contribution.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for stronger isolation of the hierarchical prediction mechanism and more rigorous experimental reporting. We will revise the manuscript to incorporate an ablation study isolating the scale hierarchy and to expand the experimental details as requested.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that 'providing global semantics at the coarsest scale and refining progressively' establishes a 'causal hierarchy better suited for long-range motion structure' than standard next-token prediction is load-bearing for all performance claims, yet no ablation is described that holds model capacity, training data, and the auxiliary refinement modules fixed while swapping only the prediction order (scale hierarchy vs. token order).
Authors: We agree that an ablation isolating the contribution of the scale-based prediction order (while holding model capacity, training data, and the cross-scale/in-scale refinement modules fixed) would provide stronger evidence for the central claim. In the revised manuscript we will add this controlled ablation, comparing the full MoScale hierarchy against a standard next-token autoregressive baseline with identical capacity and auxiliary modules. This will directly test whether the causal hierarchy, rather than other factors, drives the reported gains. revision: yes
-
Referee: [§4] §4 (Experiments): the SOTA, efficiency, and zero-shot generalization statements rest on comparisons whose details (exact baselines, training budgets, error bars, and statistical significance) are not provided in sufficient depth to confirm that gains arise from the claimed hierarchy rather than implementation choices.
Authors: We acknowledge that the current experimental section lacks sufficient detail on baselines, compute budgets, variance, and significance testing. In the revision we will expand §4 with: (i) precise specifications and training configurations for every baseline, (ii) training budgets reported in FLOPs or wall-clock epochs, (iii) error bars from at least three independent runs, and (iv) statistical significance tests (e.g., paired t-tests or Wilcoxon tests) for all key metrics. These additions will allow readers to verify that improvements are attributable to the proposed hierarchy. revision: yes
Circularity Check
No circularity: next-scale hierarchy is an explicit architectural proposal, not a fitted or self-defined quantity
full rationale
The paper introduces MoScale as a new next-scale autoregressive architecture that generates motion from coarse to fine scales, with added cross-scale and in-scale refinement modules. This is presented as a modeling choice motivated by alignment with temporal structure, not as a quantity derived from equations or parameters fitted to the target metrics. No self-definitional loops, fitted-input predictions, or load-bearing self-citations appear in the provided abstract or description; the central claim rests on empirical SOTA results and zero-shot generalization rather than reducing to its own inputs by construction. The assumption about causal hierarchy is an unproven modeling hypothesis, not a circular derivation.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.