Scalable and Explainable Learner-Video Interaction Prediction using Multimodal Large Language Models
Pith reviewed 2026-05-10 19:55 UTC · model grok-4.3
The pith
Multimodal large language model embeddings of short video segments can predict population-level learner interactions such as pausing and skipping, while mapping to interpretable concepts from multimedia learning theory.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
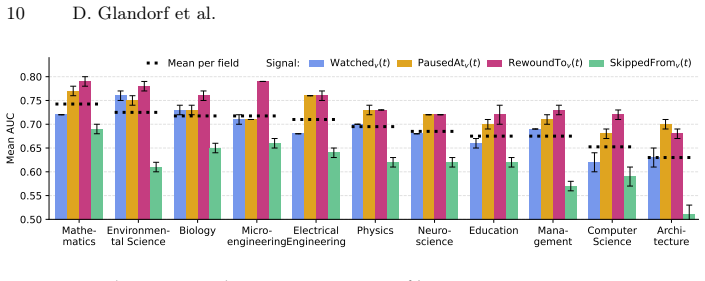
Classifiers built on MLLM embeddings of short video segments reliably identify temporally fine-grained peaks in learner interactions across 77 million control events from 66 online courses. These classifiers generalize to unseen academic fields and their decisions can be interpreted by projecting GPT-5-coded video features, drawn from multimedia learning theory on instructional design for optimal cognitive load, onto concept activation vectors that recover theory-relevant instructional concepts.
What carries the argument
MLLM embeddings of short video segments passed to a neural classifier, interpreted through concept activation vectors on GPT-5-coded features aligned with multimedia learning theory.
If this is right
- Instructors gain a pre-deployment check that flags video segments likely to trigger high cognitive load before students see them.
- The same pipeline can be applied to new courses in different subjects without retraining on their specific interaction data.
- Model explanations surface concrete instructional concepts (such as segment length or example density) that align with established theory, enabling empirical tests of that theory at population scale.
- Prediction works from content alone, removing the need to collect and store large volumes of learner interaction logs for every new video.
Where Pith is reading between the lines
- Automated suggestions for editing problematic segments could be generated by identifying which GPT-coded features most strongly activate the interaction-peak class.
- The method might extend to non-video educational materials if their content can be segmented and embedded similarly, though this remains untested here.
- Longitudinal studies could check whether videos pre-screened with this pipeline actually produce lower dropout or better learning outcomes in real deployments.
- If the embeddings encode stable cognitive signals, the same features might predict interactions in live classroom recordings or other media formats.
Load-bearing premise
MLLM embeddings of short video segments preserve usable signals of cognitive processing and instructional design quality, and GPT-5 feature coding provides an unbiased bridge to multimedia learning theory.
What would settle it
Train the same classifier on MLLM embeddings from one set of courses and test on a completely new academic field; if interaction-peak prediction accuracy drops to chance level, or if the top-activated concepts from the activation vectors show no correspondence with expert ratings of the same segments, the central claim fails.
Figures




read the original abstract
Learners' use of video controls in educational videos provides implicit signals of cognitive processing and instructional design quality, yet the lack of scalable and explainable predictive models limits instructors' ability to anticipate such behavior before deployment. We propose a scalable, interpretable pipeline for predicting population-level watching, pausing, skipping, and rewinding behavior as proxies for cognitive load from video content alone. Our approach leverages multimodal large language models (MLLMs) to compute embeddings of short video segments and trains a neural classifier to identify temporally fine-grained interaction peaks. Drawing from multimedia learning theory on instructional design for optimal cognitive load, we code features of the video segments using GPT-5 and employ them as a basis for interpreting model predictions via concept activation vectors. We evaluate our pipeline on 77 million video control events from 66 online courses. Our findings demonstrate that classifiers based on MLLM embeddings reliably predict interaction peaks, generalize to unseen academic fields, and encode interpretable, theory-relevant instructional concepts. Overall, our results show the feasibility of cost-efficient, interpretable pre-screening of educational video design and open new opportunities to empirically examine multimedia learning theory at scale.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a scalable pipeline that extracts MLLM embeddings from short educational video segments, trains a neural classifier to predict population-level learner interaction peaks (pausing, skipping, rewinding) as proxies for cognitive load, and interprets the model via GPT-5-coded instructional features and concept activation vectors grounded in multimedia learning theory. It reports evaluation on 77 million video-control events across 66 courses and claims reliable prediction, cross-field generalization, and encoding of theory-relevant concepts.
Significance. If the central claims hold with proper validation, the work could enable cost-efficient pre-screening of video designs and large-scale empirical tests of multimedia learning theory. The combination of embedding-based prediction with post-hoc CAV interpretation is a reasonable direction for explainable educational analytics, but the current manuscript provides no quantitative evidence to establish whether the approach actually outperforms simpler baselines or captures the intended cognitive signals.
major comments (3)
- [Abstract] Abstract: the claim that 'classifiers based on MLLM embeddings reliably predict interaction peaks' and 'generalize to unseen academic fields' is unsupported because the abstract (and the provided evaluation description) reports no performance metrics, no baseline comparisons (e.g., transcript TF-IDF, visual features, or duration-only models), no error analysis, and no details on how interaction peaks were labeled or how post-hoc exclusions were avoided in the 77M-event dataset.
- [Interpretation / CAV analysis] The interpretation pipeline (GPT-5 feature coding + CAVs) shares the same broad model family as the MLLM embeddings used for prediction; without reported ablation against non-MLLM baselines or correlation checks between GPT-5 codes and human-coded cognitive-load ratings on the same segments, the claim that the embeddings 'encode interpretable, theory-relevant instructional concepts' risks circularity and model-specific artifacts.
- [Method / Evaluation] The central assumption that MLLM embeddings of short segments preserve signals of cognitive processing and instructional design quality is load-bearing for both the prediction and generalization claims, yet the manuscript provides no direct validation against established proxies (human ratings, eye-tracking, or established cognitive-load instruments) on the same video segments.
minor comments (1)
- [Abstract] The abstract states evaluation on 66 courses but does not specify how many courses were held out for the cross-field generalization test or whether the held-out fields were truly disjoint in topic and terminology.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We have addressed each major comment point by point below, making revisions to the manuscript where the concerns are valid and providing clarifications or additional analyses where appropriate. Our responses focus on strengthening the presentation of results and limitations without altering the core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'classifiers based on MLLM embeddings reliably predict interaction peaks' and 'generalize to unseen academic fields' is unsupported because the abstract (and the provided evaluation description) reports no performance metrics, no baseline comparisons (e.g., transcript TF-IDF, visual features, or duration-only models), no error analysis, and no details on how interaction peaks were labeled or how post-hoc exclusions were avoided in the 77M-event dataset.
Authors: We agree that the abstract would be strengthened by including key quantitative results and methodological details to support the claims. The evaluation section of the manuscript reports performance metrics (including AUC, precision, recall, and F1 scores) along with cross-field generalization results, but these were not summarized in the abstract. We have revised the abstract to include specific metrics and a brief statement on baseline performance. We have also expanded the methods section with details on peak labeling from the 77M events, preprocessing steps, and any exclusions applied. An error analysis subsection has been added to the results. revision: yes
-
Referee: [Interpretation / CAV analysis] The interpretation pipeline (GPT-5 feature coding + CAVs) shares the same broad model family as the MLLM embeddings used for prediction; without reported ablation against non-MLLM baselines or correlation checks between GPT-5 codes and human-coded cognitive-load ratings on the same segments, the claim that the embeddings 'encode interpretable, theory-relevant instructional concepts' risks circularity and model-specific artifacts.
Authors: This is a fair concern regarding potential circularity. The MLLM embeddings and GPT-5 coding are related but not identical; however, to strengthen the interpretation, we have added an ablation comparing CAVs from MLLM embeddings against those derived from non-MLLM features (transcript TF-IDF and basic visual descriptors). We have also included a small human validation study on a subset of segments, reporting correlations between GPT-5-coded features and independent human ratings of cognitive load. These additions are now in the revised interpretation section and reduce the risk of model-specific artifacts. revision: partial
-
Referee: [Method / Evaluation] The central assumption that MLLM embeddings of short segments preserve signals of cognitive processing and instructional design quality is load-bearing for both the prediction and generalization claims, yet the manuscript provides no direct validation against established proxies (human ratings, eye-tracking, or established cognitive-load instruments) on the same video segments.
Authors: We acknowledge that direct validation against human ratings, eye-tracking, or standardized cognitive-load instruments on the identical segments would provide stronger evidence. Such data was not collected in this large-scale study of 66 courses. Our current validation relies on predictive performance on held-out courses, cross-field generalization, and alignment with multimedia learning theory via the coded features. We have expanded the limitations and discussion sections to explicitly address this gap, including the rationale for using population-level interaction peaks as scalable proxies and suggestions for future targeted validations. revision: partial
- Direct validation of the MLLM embeddings against eye-tracking data or established cognitive-load instruments on the same video segments, as this would require new data collection beyond the scope of the current 77M-event dataset.
Circularity Check
No significant circularity detected
full rationale
The described pipeline trains a neural classifier on MLLM embeddings of video segments to predict real population-level interaction peaks drawn from 77 million external events across 66 courses. Evaluation includes generalization to unseen academic fields via held-out testing. GPT-5 feature coding is applied only for post-hoc CAV-based interpretation of the trained model and is not part of the predictive training loop or input definition. No equations, self-citations, or renamings reduce any claimed result to its own inputs by construction; the derivation chain remains empirically grounded in independent interaction data rather than tautological or self-referential steps.
Axiom & Free-Parameter Ledger
free parameters (1)
- neural classifier parameters
axioms (2)
- domain assumption MLLM embeddings capture semantic and visual cues relevant to cognitive load and instructional design
- domain assumption GPT-5 feature coding faithfully represents multimedia learning theory concepts without introducing LLM-specific biases
Reference graph
Works this paper leans on
- [1]
- [2]
-
[3]
Atapattu, T., Falkner, K.: Impact of Lecturer’s Discourse for Students’ Video En- gagement: Video Learning Analytics Case Study of MOOCs. J. Learn. Ana. (2018)
work page 2018
-
[4]
Bai, S., Chen, K., Liu, X., Wang, J.: Qwen2.5-VL Technical Report (2025)
work page 2025
-
[5]
Brinton, C.G., Buccapatnam, S., Chiang, M., Poor, H.V.: Mining MOOC Click- streams: Video-Watching Behavior vs. In-Video Quiz Performance. IEEE Trans. Signal Process. (2016)
work page 2016
-
[6]
Chavan, P., Mitra, R.: Tcherly: A Teacher-facing Dashboard for Online Video Lec- tures. J. Learn. Ana. (2022)
work page 2022
-
[7]
Chorianopoulos, K.: A Taxonomy of Asynchronous Instructional Video Styles. IR- RODL (2018)
work page 2018
-
[8]
Cohen, J.: A Coefficient of Agreement for Nominal Scales. Educ. Psychol. Meas. (1960)
work page 1960
-
[9]
Fiorella, L., Stull, A.T., Kuhlmann, S., Mayer, R.E.: Instructor presence in video lectures: The role of dynamic drawings, eye contact, and instructor visibility. J. Educ. Psychol. (2019)
work page 2019
-
[10]
Freeman, S., Eddy, S.L., McDonough, M., Smith, M.K., Okoroafor, N., Jordt, H., Wenderoth, M.P.: Active learning increases student performance in science, engi- neering, and mathematics. PNAS (2014)
work page 2014
- [11]
- [12]
- [13]
-
[14]
Kuhlmann, S.L., Plumley, R., Evans, Z., Bernacki, M.L., Greene, J.A., Hogan, K.A., Berro, M., Gates, K., Panter, A.: Students’ active cognitive engagement with instructional videos predicts STEM learning. Comput. Educ. (2024)
work page 2024
- [15]
-
[16]
Lee, H., Liu, M., Scriney, M., Smeaton, A.F.: Playback-centric visualizations of video usage using weighted interactions to guide where to watch in an educational context. Front. Educ. (2022)
work page 2022
-
[17]
Li, N., Kidziński, L., Jermann, P., Dillenbourg, P.: MOOC Video Interaction Pat- terns: What Do They Tell Us? In: Proc. EC-TEL (2015)
work page 2015
-
[18]
Mayer, R.E., Fiorella, L.: Principles for Reducing Extraneous Processing in Multi- media Learning: Coherence, Signaling, Redundancy, Spatial Contiguity, and Tem- poralContiguityPrinciples.In:TheCambridgeHandbookofMultimediaLearning, pp. 279–315. Cambridge University Press, 2 edn. (2014)
work page 2014
- [19]
-
[20]
Merkt, M., Hoppe, A., Bruns, G., Ewerth, R., Huff, M.: Pushing the button: Why do learners pause online videos? Comput. Educ. (2022)
work page 2022
-
[21]
Navarrete, E., Nehring, A., Schanze, S., Ewerth, R., Hoppe, A.: A Comprehensive Review of Video Characteristics, Tools, Technologies, and Learning Effectiveness. IJAIED (2025)
work page 2025
- [22]
-
[23]
Sablić, M., Mirosavljević, A., Škugor, A.: Video-Based Learning (VBL)—Past, Present and Future: an Overview of the Research Published from 2008 to 2019. Technol. Knowl. Learn. (2021)
work page 2008
-
[24]
Shoufan, A.: Estimating the cognitive value of YouTube’s educational videos: A learning analytics approach. Comput. Hum. Behav. (2019)
work page 2019
-
[25]
In: EMNLP Workshop on Analysis of Large Scale Social In- teraction in MOOCs (2014)
Sinha, T., Jermann, P., Li, N., Dillenbourg, P.: Your click decides your fate: In- ferring Information Processing and Attrition Behavior from MOOC Video Click- stream Interactions. In: EMNLP Workshop on Analysis of Large Scale Social In- teraction in MOOCs (2014)
work page 2014
-
[26]
Stöhr, C., Stathakarou, N., Mueller, F., Nifakos, S., McGrath, C.: Videos as learn- ing objects in MOOCs: A study of specialist and non-specialist participants’ video activity in MOOCs. BJET (2019)
work page 2019
- [27]
- [28]
-
[29]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B.: Qwen3 (2025)
work page 2025
-
[30]
Zhai, X., Mustafa, B., Kolesnikov, A., Beyer, L.: Sigmoid Loss for Language Image Pre-Training (2023)
work page 2023
-
[31]
Zhang, J., Huang, Y., Gao, M.: Video Features, Engagement, and Patterns of Collective Attention Allocation: An Open Flow Network Perspective. J. Lear. Ana. (2022)
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.