The Cluster Completeness Correction Calculator (C-4): A Neural-Network framework and pilot application to the LEGUS Survey of NGC 628
Pith reviewed 2026-05-10 19:53 UTC · model grok-4.3
The pith
Neural networks trained on injected artificial clusters learn the selection function for detecting star clusters in galaxy images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
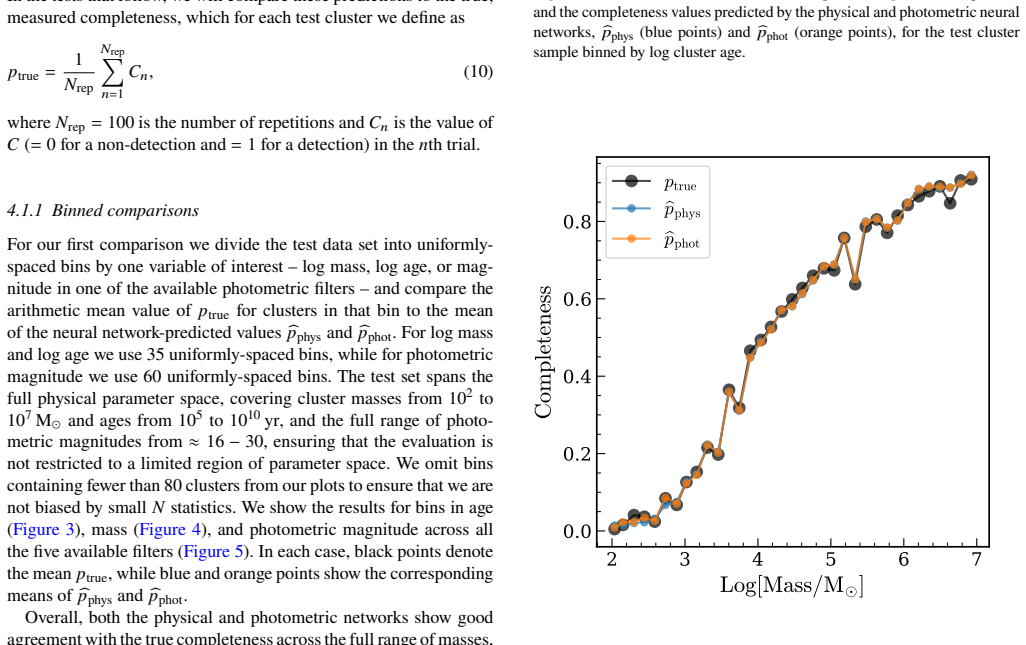
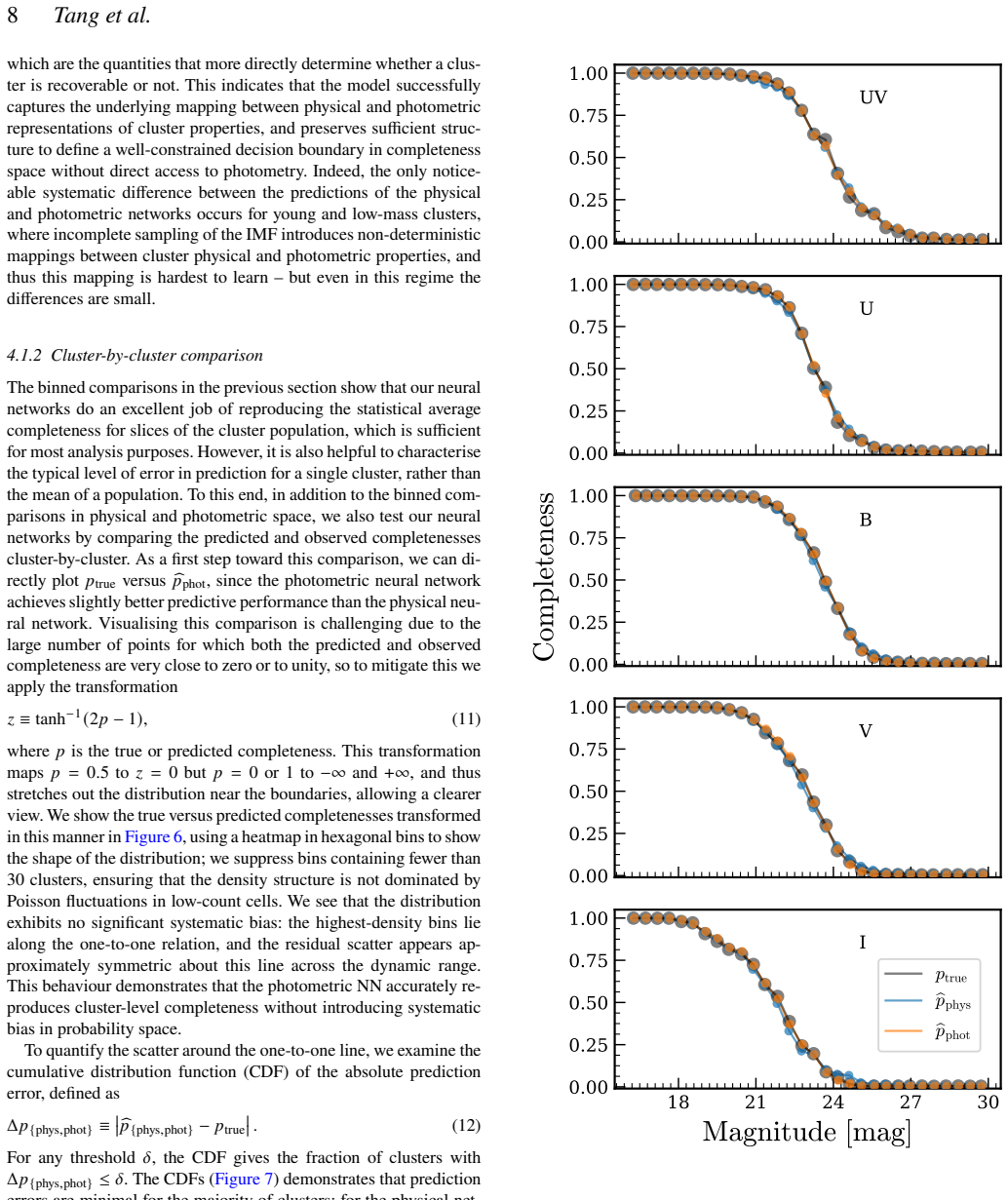
By training multilayer perceptron networks on the detection outcomes of artificial clusters injected into observed images and processed identically to real data, the method learns a highly accurate selection operator that captures strongly non-separable dependencies on physical parameters, allowing direct completeness corrections that extend demographic analyses by roughly an order of magnitude in mass and age while eliminating biases in the distributions.
What carries the argument
Multilayer perceptron neural networks that map cluster physical parameters (mass, age, extinction) to a continuous detection probability after the clusters have been injected into real images and passed through the catalogue construction pipeline.
If this is right
- Completeness corrections can be applied directly to existing cluster catalogues to recover intrinsic populations.
- Observed mass and age distributions no longer show artificial flattening at the low end.
- Demographic analyses become feasible over an order of magnitude wider range in mass and age.
- The differentiable completeness functions can be inserted into forward-modeling or Bayesian inference frameworks.
Where Pith is reading between the lines
- The same injection-plus-network approach could be used to model selection functions for other resolved populations such as individual stars or H II regions.
- Embedding the learned completeness operator inside hierarchical population models would allow joint inference of formation rates and disruption timescales.
- The framework scales to large surveys by retraining on new fields or instruments without changing the core procedure.
Load-bearing premise
Artificial clusters added to the images reproduce the detection and filtering behavior of real clusters, and the trained networks generalize to actual data without significant overfitting.
What would settle it
A quantitative match between the neural network's predicted recovery fraction and the actual fraction recovered when a large new set of artificial clusters is injected and run through the pipeline as an independent test.
Figures







read the original abstract
Integrated-light star cluster catalogues in external galaxies are subject to complex, often poorly-characterised selection effects that can bias inferred cluster demographics and introduce significant uncertainties, limiting the physical parameter space accessible to analysis. To mitigate this problem, here we introduce the Cluster Completeness Correction Calculator (C-4): a new software tool to quantify and predict these effects in both physical and photometric parameter spaces. C-4 adds artificial star clusters to observed galaxy images, processes these images through the same detection and filtering steps used to construct the original cluster catalogue, and then trains multilayer perceptron neural networks to learn the resulting selection function. The trained neural networks provide continuous, differentiable completeness functions that can be used for direct completeness corrections or incorporated into forward models. We present a pilot application of C-4 to NGC~628, demonstrating that the learned selection operator is highly accurate and successfully captures the strongly non-separable dependence of completeness on mass, age, and extinction. Applying the completeness correction to NGC 628 extends the range of cluster demographic analyses by roughly an order of magnitude in both mass and age, and removes artificial flattening in the observed cluster mass and age distributions. These results establish neural-network-based completeness modelling as a powerful and general approach for recovering intrinsic cluster populations, and provide a scalable framework for modelling high-dimensional selection functions in resolved stellar population studies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Cluster Completeness Correction Calculator (C-4), a framework that injects artificial star clusters into observed galaxy images, processes them through the same detection and filtering pipeline as the real catalog, and trains multilayer perceptron neural networks to learn a continuous, differentiable completeness function in physical and photometric parameter space. In a pilot application to the LEGUS survey of NGC 628, the authors claim that the trained networks achieve high accuracy, capture strongly non-separable dependencies on mass, age, and extinction, and that applying the correction extends the accessible range of cluster demographic analyses by roughly an order of magnitude while removing artificial flattening in the observed mass and age distributions.
Significance. If the core assumption holds, C-4 offers a scalable, general method for modeling high-dimensional selection functions in resolved stellar populations, directly addressing a long-standing limitation in extragalactic cluster studies. The provision of a trained, differentiable completeness operator that can be used in forward modeling or direct corrections is a concrete advance over traditional binned or parametric approaches.
major comments (3)
- [Methods and Results] The central claim that the learned selection operator is 'highly accurate' and successfully captures non-separable dependencies rests on the untested fidelity of the artificial-cluster injection procedure to real detection, photometry, and filtering decisions. No independent ground-truth comparison (e.g., against real clusters with known properties or against an alternative completeness estimator) is presented; all reported accuracy metrics derive from train/test splits within the synthetic population.
- [Application to NGC 628] The reported order-of-magnitude extension in mass and age range for NGC 628, and the removal of artificial flattening, are direct consequences of the completeness function derived from the synthetic injections. Without a quantitative assessment of how mismatches in morphology, crowding, background structure, or PSF convolution between synthetic and real clusters propagate into the learned function, the demographic corrections remain provisional.
- [Neural Network Training] The manuscript does not report the specific network architecture details, hyperparameter choices, loss function, or regularization strategy used for the multilayer perceptrons, nor does it include ablation tests showing that the non-separable behavior is learned rather than imposed by the training distribution.
minor comments (2)
- [Figures] Figure captions should explicitly state the range of injected parameters (mass, age, extinction) and the number of synthetic clusters used for training and testing.
- [Discussion] The abstract states that the networks 'provide continuous, differentiable completeness functions'; the main text should include an explicit statement of how these functions are evaluated or interpolated for use in downstream demographic modeling.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments, which highlight important limitations in the current presentation of the C-4 framework. We respond point-by-point to the major comments below, indicating where we will revise the manuscript to address the concerns raised.
read point-by-point responses
-
Referee: [Methods and Results] The central claim that the learned selection operator is 'highly accurate' and successfully captures non-separable dependencies rests on the untested fidelity of the artificial-cluster injection procedure to real detection, photometry, and filtering decisions. No independent ground-truth comparison (e.g., against real clusters with known properties or against an alternative completeness estimator) is presented; all reported accuracy metrics derive from train/test splits within the synthetic population.
Authors: We agree that all reported accuracy metrics are internal to the synthetic population and that no independent validation against real clusters with known properties is provided. This is an inherent limitation of the pilot study, as true physical parameters for the undetected or marginally detected real clusters are not independently known. The method's design relies on applying the identical detection and filtering pipeline to injected clusters, which provides a self-consistent estimate of the selection function. In the revised manuscript we will add an explicit discussion of this assumption and its caveats, including potential differences in morphology and background, while tempering the language around 'highly accurate' to reflect the synthetic nature of the validation. revision: partial
-
Referee: [Application to NGC 628] The reported order-of-magnitude extension in mass and age range for NGC 628, and the removal of artificial flattening, are direct consequences of the completeness function derived from the synthetic injections. Without a quantitative assessment of how mismatches in morphology, crowding, background structure, or PSF convolution between synthetic and real clusters propagate into the learned function, the demographic corrections remain provisional.
Authors: The referee is correct that the reported extensions and corrections are provisional in the absence of a quantitative propagation of injection mismatches. We will revise the application section to include sensitivity tests that vary key injection parameters (e.g., cluster morphology, PSF convolution, and local background levels) and report the resulting variation in the derived completeness function and demographic corrections. This will provide a quantitative bound on the robustness of the NGC 628 results. revision: yes
-
Referee: [Neural Network Training] The manuscript does not report the specific network architecture details, hyperparameter choices, loss function, or regularization strategy used for the multilayer perceptrons, nor does it include ablation tests showing that the non-separable behavior is learned rather than imposed by the training distribution.
Authors: We will add a dedicated subsection in the Methods describing the multilayer perceptron architecture (number of layers, neurons per layer, activation functions), the hyperparameter search procedure, the loss function (binary cross-entropy), and the regularization techniques employed (dropout and early stopping). We will also include ablation experiments that systematically remove or mask input features (mass, age, extinction, local background) and demonstrate that the non-separable dependencies emerge from the training data rather than being artifacts of the sampling distribution. revision: yes
- Independent ground-truth comparison against real clusters with known properties
- Complete quantitative assessment of all possible mismatches between synthetic and real cluster injections without new observational data
Circularity Check
No significant circularity; forward simulation and external pipeline provide independent basis
full rationale
The paper's core method injects artificial clusters into real observed images, runs them through the identical LEGUS detection and filtering pipeline, and trains MLPs on the resulting binary detection labels to learn a continuous completeness function. This learned operator is then applied to the real catalog. No step reduces by construction to its own inputs: the training data derive from external images and a fixed external pipeline rather than from the target cluster demographics or from parameters fitted to the final corrected distributions. No self-citations, uniqueness theorems, or ansatzes are invoked as load-bearing premises. The derivation chain therefore remains self-contained against external benchmarks (the LEGUS images and pipeline) and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
free parameters (1)
- multilayer perceptron architecture and training parameters
axioms (1)
- domain assumption Artificial clusters added to real galaxy images undergo identical detection, photometry, and filtering steps as real clusters.
Reference graph
Works this paper leans on
-
[1]
Adamo A., et al., 2017, The Astrophysical Journal, 841, 131 Arora R., Krumholz M. R., Federrath C., 2021, MNRAS, 508, 3290 Bertin E., Arnouts S., 1996, A&AS, 117, 393 Boulares A., Cox D. P., 1990, ApJ, 365, 544 Calzetti D., et al., 2015, AJ, 149, 51 Cerviño M., Luridiana V., 2004, A&A, 413, 145 Cerviño M., Valls-Gabaud D., 2003, MNRAS, 338, 481 ChabrierG....
-
[2]
Pedregosa F., et al., 2011, Journal of Machine Learning Research, 12, 2825 Rumelhart D. E., Hinton G. E., Williams R. J., 1986, Nature, 323, 533 Ryon J. E., et al., 2017, ApJ, 841, 92 Tang J., Grasha K., Krumholz M. R., 2023, arXiv e-prints, p. arXiv:2301.05912 Tang J., Grasha K., Krumholz M. R., 2024, MNRAS, 532, 4583 Vaswani A., Shazeer N., Parmar N., U...
work page internal anchor Pith review doi:10.48550/arxiv.1706.03762 2011
-
[3]
Beyond this point, doubling the training set yields marginal improvement in validation lossΔCE≲0.001, while substantially increasing computational cost. Although the validation loss begins to plateau at𝑁≈5×104, the curves continue to decrease slightly up to𝑁=2.5×105, while the improvement beyond this point is minimal. We therefore adopt a sample size of𝑁=...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.