JTON: A Token-Efficient JSON Superset with Zen Grid Tabular Encoding for Large Language Models
Pith reviewed 2026-05-10 20:06 UTC · model grok-4.3
The pith
JTON with Zen Grid encoding reduces token counts for tabular data in LLMs by 28.5% on average while maintaining comprehension accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
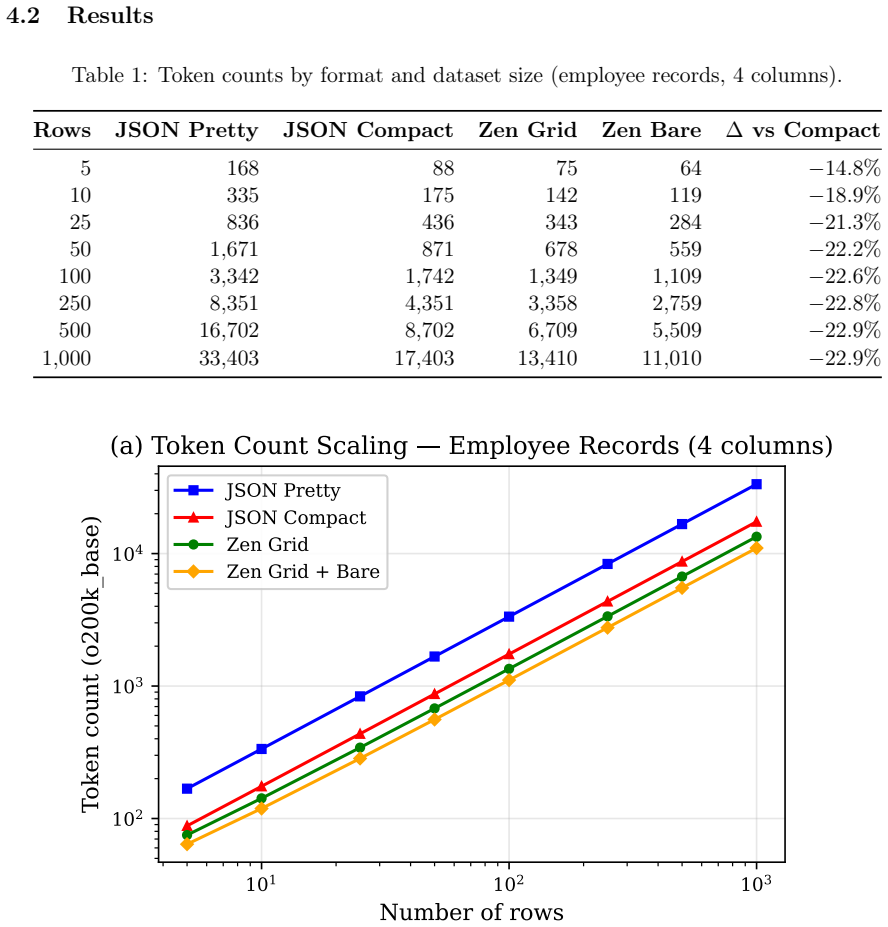
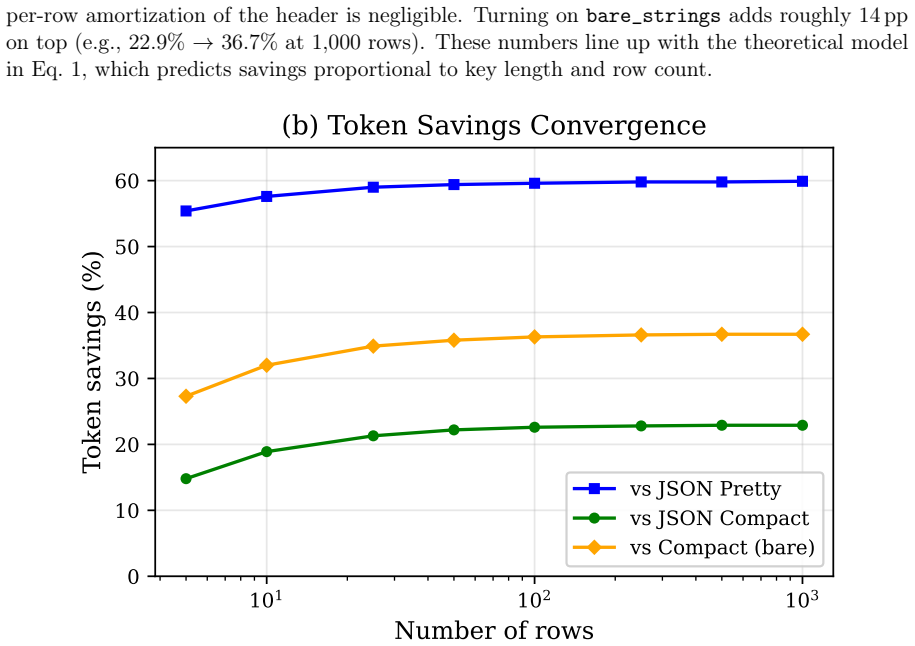
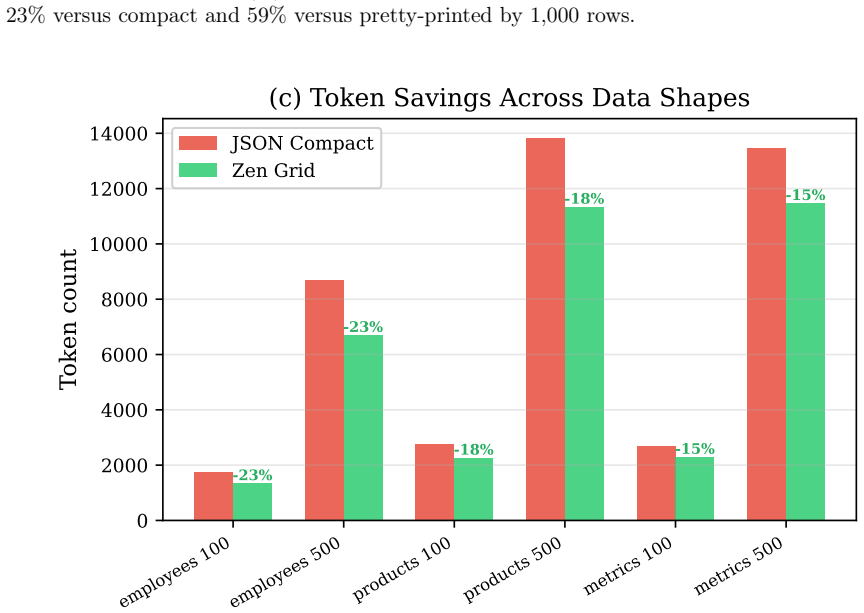
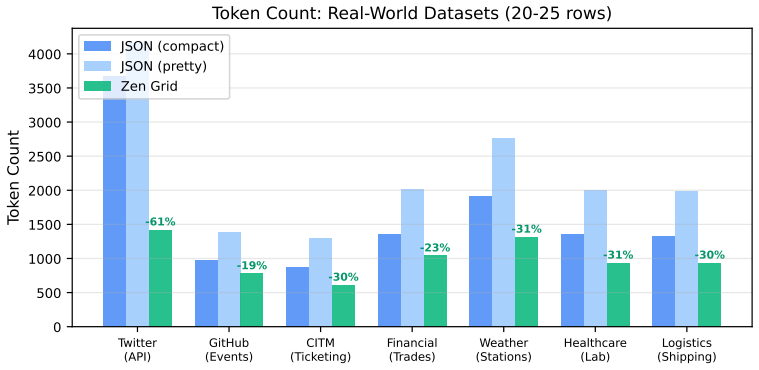
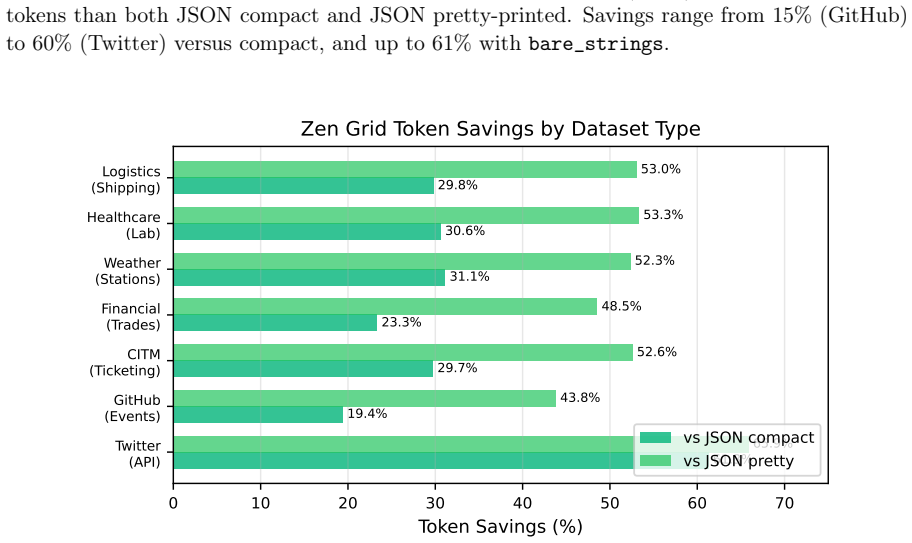
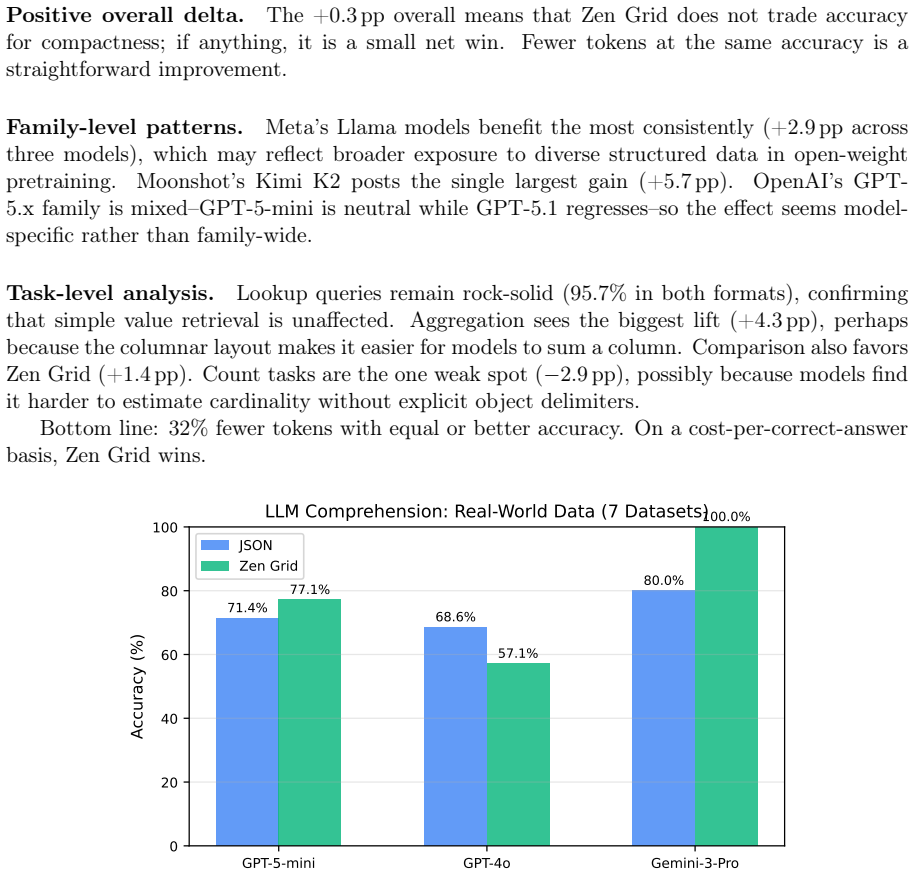
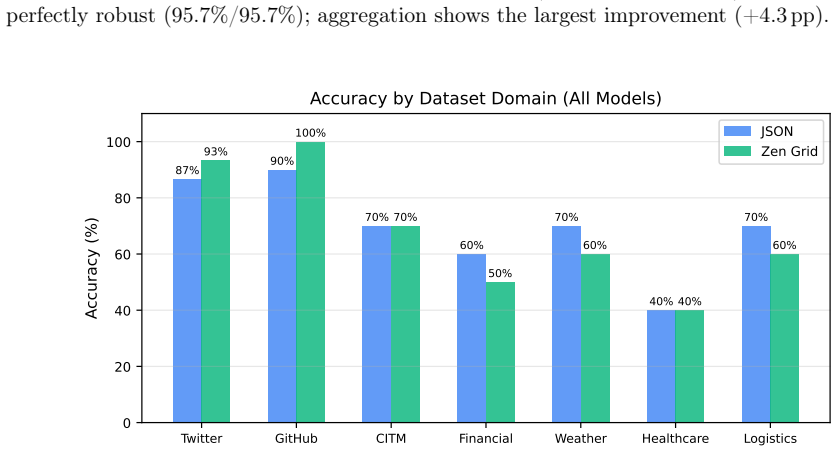
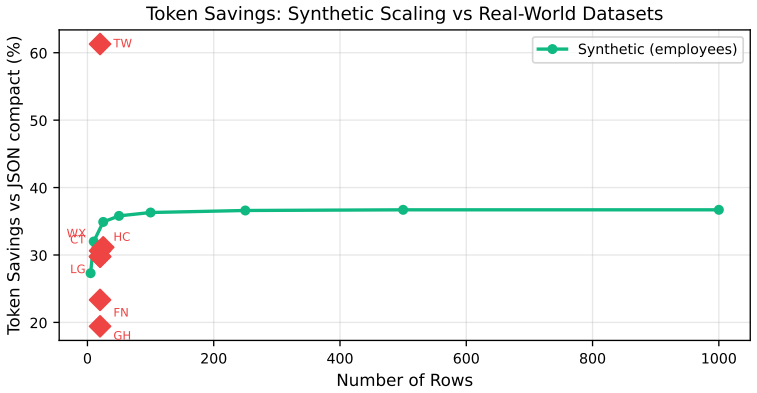
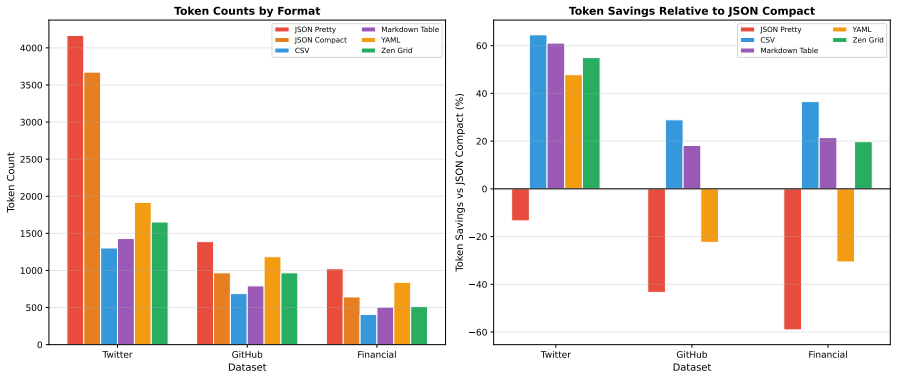
JTON introduces Zen Grid tabular encoding, which places column headers in one row and encodes row values using semicolon delimiters, achieving 15-60% token reduction compared to compact JSON across seven real-world domains with an average of 28.5%. LLM comprehension tests on 10 models show a net 0.3 percentage point accuracy improvement, and generation tests on 12 models confirm 100% syntactic validity in few-shot and zero-shot scenarios.
What carries the argument
Zen Grid: a tabular encoding mechanism that isolates column headers in a single row and delimits cell values with semicolons within a JSON-compatible structure.
If this is right
- Token usage for tabular arrays drops by 15 to 60 percent compared to standard JSON.
- LLMs achieve comparable or slightly higher accuracy on data comprehension tasks.
- Models can generate valid JTON data reliably without special training.
- Optimized parsers can process the format faster than standard JSON libraries.
- Structured data can fit into more LLM prompts due to reduced token overhead.
Where Pith is reading between the lines
- Zen Grid could be adapted to other data serialization formats beyond JSON to achieve similar efficiencies.
- With lower token counts, LLMs might handle larger tables or more complex nested structures in a single context window.
- Future work might test the format on emerging LLM architectures or in production APIs for cost savings.
- The public test suite and implementation allow independent verification and extension to new domains.
Load-bearing premise
The seven real-world domains and the particular LLMs tested are representative enough that the observed token savings and accuracy results will hold in other common use cases.
What would settle it
Testing on an eighth domain or additional LLMs where token reduction falls below 10% or where accuracy decreases by more than 1 percentage point compared to JSON.
Figures
read the original abstract
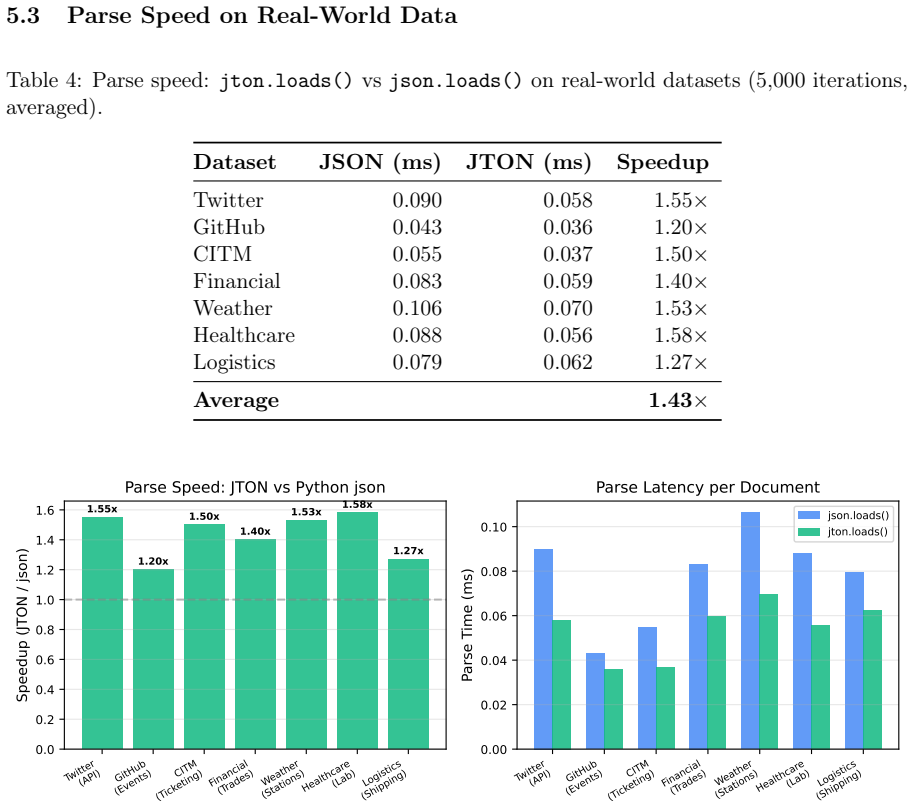
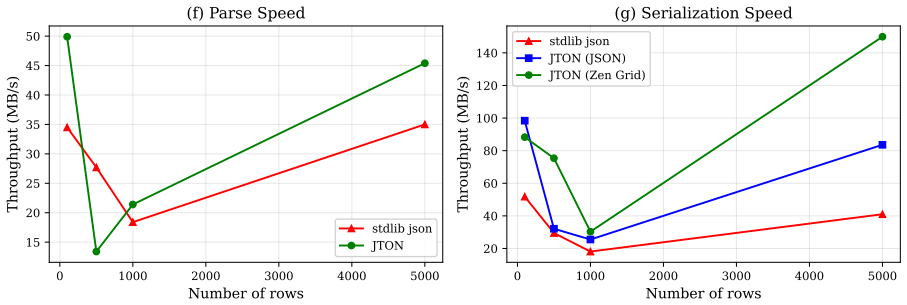
When LLMs process structured data, the serialization format directly affects cost and context utilization. Standard JSON wastes tokens repeating key names in every row of a tabular array--overhead that scales linearly with row count. This paper presents JTON (JSON Tabular Object Notation), a strict JSON superset whose main idea, Zen Grid, factors column headers into a single row and encodes values with semicolons, preserving JSON's type system while cutting redundancy. Across seven real-world domains, Zen Grid reduces token counts by 15-60% versus JSON compact (28.5% average; 32% with bare_strings). Comprehension tests on 10 LLMs show a net +0.3 pp accuracy gain over JSON: four models improve, three hold steady, and three dip slightly. Generation tests on 12 LLMs yield 100% syntactic validity in both few-shot and zero-shot settings. A Rust/PyO3 reference implementation adds SIMD-accelerated parsing at 1.4x the speed of Python's json module. Code, a 683-vector test suite, and all experimental data are publicly available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces JTON, a strict JSON superset featuring Zen Grid tabular encoding that factors column headers into a single row and uses semicolon-separated values to reduce redundancy while preserving JSON's type system. It reports 15-60% token reductions (28.5% average) versus compact JSON across seven real-world domains, a net +0.3 pp accuracy gain in comprehension tests on 10 LLMs (with mixed per-model outcomes), 100% syntactic validity in generation tests on 12 LLMs, and a SIMD-accelerated Rust/PyO3 implementation that parses 1.4x faster than Python's json module. All code, a 683-vector test suite, and experimental data are released publicly.
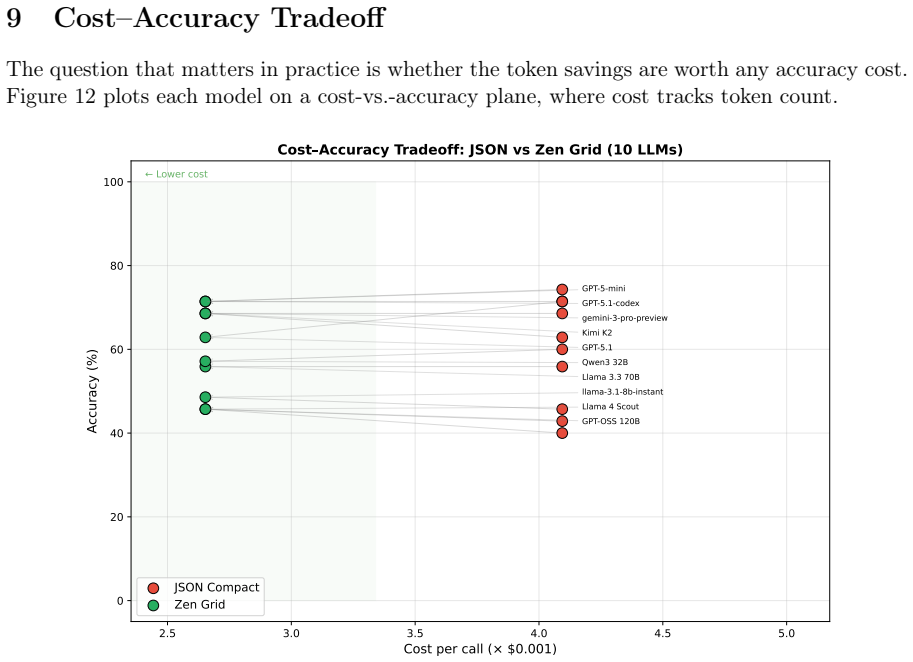
Significance. If the empirical claims hold under scrutiny, the work offers a practical, backward-compatible format that could lower token costs for tabular data in LLM pipelines without introducing accuracy penalties, supported by the open reference implementation and test suite as reproducibility strengths.
major comments (1)
- [Abstract] Abstract: The central claim of a net +0.3 pp accuracy gain (with four models improving, three steady, three dipping) lacks per-model scores, test-item counts, variance estimates, confidence intervals, or significance tests. This makes it impossible to determine whether the small aggregate figure reflects a reliable property of Zen Grid or statistical noise, directly undermining the 'no downside' component of the contribution.
minor comments (1)
- The abstract and results sections would benefit from explicit statements of the exact tokenization model (e.g., which tokenizer) used for the reported counts, as token savings can vary across implementations.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract's presentation of results. We address the concern point by point below and commit to revisions that improve transparency without altering the core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim of a net +0.3 pp accuracy gain (with four models improving, three steady, three dipping) lacks per-model scores, test-item counts, variance estimates, confidence intervals, or significance tests. This makes it impossible to determine whether the small aggregate figure reflects a reliable property of Zen Grid or statistical noise, directly undermining the 'no downside' component of the contribution.
Authors: We agree that the abstract, as a concise summary, does not embed the full statistical apparatus. The manuscript already reports the mixed per-model outcomes explicitly and draws from the 683-vector test suite described in Section 3. Per-model accuracy scores, item counts per domain, and variance estimates appear in the results section (Table 2 and accompanying text). However, formal confidence intervals and significance tests (e.g., paired t-tests or McNemar) were not computed in the submitted version. We will revise the abstract to add a brief qualifier referencing the detailed results and will incorporate the requested statistical tests in the revised manuscript to allow readers to assess whether the net +0.3 pp gain is distinguishable from noise. revision: yes
Circularity Check
No circularity: claims rest on direct empirical measurements
full rationale
The paper introduces JTON/Zen Grid as a JSON superset for tabular data and validates it via token-count reductions measured on seven real-world domains plus direct LLM comprehension and generation tests across 10-12 models. No equations, fitted parameters, or derivations are presented that could reduce to their own inputs. No self-citations, uniqueness theorems, or ansatzes are invoked to support the core claims. All reported outcomes (token savings, accuracy deltas, 100% validity, parsing speed) are obtained from external benchmarks and implementations rather than by construction from the format definition itself. The derivation chain is therefore self-contained and non-circular.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Preservation of JSON type system and syntactic validity in the superset format
invented entities (1)
-
Zen Grid
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Zen Grid factors column headers into a single row and encodes values with semicolons, preserving JSON’s type system while cutting redundancy. Across seven real-world domains, Zen Grid reduces token counts by 15–60% versus JSON compact (28.5% average; 32% with bare_strings).
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat recovery theorems unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Comprehension tests on 10 LLMs show a net +0.3 pp accuracy gain over JSON... Generation tests on 12 LLMs yield 100% syntactic validity
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Notation Matters: A Benchmark Study of Token-Optimized Formats in Agentic AI Systems
TRON cuts tokens up to 27% with accuracy within 14pp of JSON on agentic benchmarks while TOON reaches 18% savings but triggers multi-turn parsing failures and parallel-call collapse on most models.
Reference graph
Works this paper leans on
-
[1]
Oren Ben-Kiki, Clark Evans, and Ingy döt Net
doi: 10.1145/3192366.3192369. Oren Ben-Kiki, Clark Evans, and Ingy döt Net. YAML ain’t markup language (YAML) version 1.2.https://yaml.org/spec/1.2.2/,
- [2]
-
[3]
doi: 10.14778/3352063.3352077. OpenAI. tiktoken: Fast BPE tokeniser for use with OpenAI’s models.https://github.com/ openai/tiktoken,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.