EDGE-Shield: Efficient Denoising-staGE Shield for Violative Content Filtering via Scalable Reference-Based Matching
Pith reviewed 2026-05-13 17:48 UTC · model grok-4.3
The pith
EDGE-Shield filters violative content in text-to-image models by matching reference embeddings on transformed early-stage latents instead of waiting for finished images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
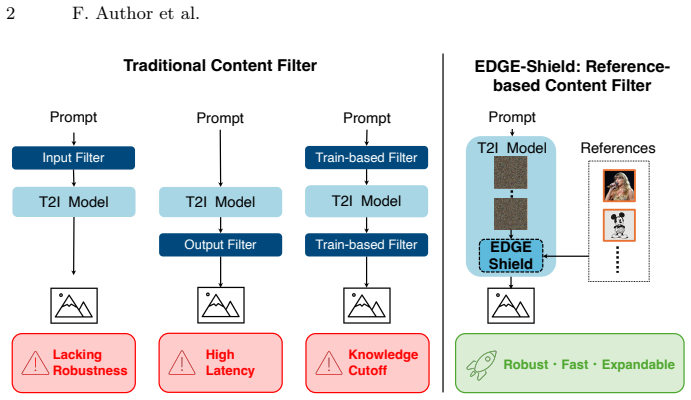
The paper presents EDGE-Shield as a denoising-stage content filter that applies embedding-based reference matching to x-pred transformed noisy latents. The x-pred step converts each intermediate noisy representation into an estimate of the clean latent that would appear at a later denoising step. Experiments on Z-Image-Turbo and Qwen-Image show this yields an approximate 79 percent reduction in processing time for the first model and 50 percent for the second while preserving filtering accuracy.
What carries the argument
The x-pred transformation, which converts a model's noisy intermediate latent into a pseudo-estimated clean latent from a later denoising stage, paired with embedding-based reference matching performed at early steps.
If this is right
- Filtering can occur without completing image generation, so violative outputs are blocked before they are produced.
- The method scales to large numbers of reference images because embedding comparisons replace slower pixel-level or feature-level checks.
- Accuracy holds across different generator architectures, so the same filter can protect multiple models.
- Protection remains current as new copyrighted works appear, since references can be added without retraining.
Where Pith is reading between the lines
- The approach could be extended to video or audio generators by applying the same early-stage transformation and matching logic.
- Integration into live generation APIs might allow real-time policy enforcement without user-visible slowdown.
- If early detection proves stable, similar latent-space checks could be tested for other safety properties beyond copyright, such as prohibited visual styles.
Load-bearing premise
Matching embeddings on the x-pred transformed noisy latent at early denoising stages can detect violative content reliably without needing the completed image or producing too many false positives.
What would settle it
A direct comparison on a held-out set of violative and non-violative prompts showing that early-stage x-pred matching either misses a substantial fraction of violations or produces materially higher false-positive rates than waiting for the finished image.
Figures








read the original abstract
The advent of Text-to-Image generative models poses significant risks of copyright violation and deepfake generation. Since the rapid proliferation of new copyrighted works and private individuals constantly emerges, reference-based training-free content filters are essential for providing up-to-date protection without the constraints of a fixed knowledge cutoff. However, existing reference-based approaches often lack scalability when handling numerous references and require waiting for finishing image generation. To solve these problems, we propose EDGE-Shield, a scalable content filter during the denoising process that maintains practical latency while effectively blocking violative content. We leverage embedding-based matching for efficient reference comparison. Additionally, we introduce an \textit{$x$}-pred transformation that converts the model's noisy intermediate latent into the pseudo-estimated clean latent at the later stage, enhancing classification accuracy of violative content at earlier denoising stages. We conduct experiments of violative content filtering against two generative models including Z-Image-Turbo and Qwen-Image. EDGE-Shield significantly outperforms traditional reference-based methods in terms of latency; it achieves an approximate $79\%$ reduction in processing time for Z-Image-Turbo and approximate $50\%$ reduction for Qwen-Image, maintaining the filtering accuracy across different model architectures.
Editorial analysis
A structured set of objections, weighed in public.
Circularity Check
No significant circularity in derivation chain
full rationale
The paper describes an empirical engineering method for early-stage violative content filtering in diffusion models using embedding-based matching and an x-pred transformation on noisy latents. No equations, derivations, or first-principles claims are presented that reduce the reported latency reductions (79% for Z-Image-Turbo, 50% for Qwen-Image) or accuracy maintenance to fitted parameters, self-definitions, or self-citation chains by construction. The x-pred step is introduced as a practical heuristic to improve early-stage classification without any mathematical equivalence to the target performance metrics, and performance is validated experimentally across model architectures rather than derived from inputs. The contribution remains self-contained as an applied adaptation of reference-based matching.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we introduce an x-pred transformation that converts the model's noisy intermediate latent into the pseudo-estimated clean latent at the later stage... xθ(zt, t) = zt + (1−t)vθ(zt, t)
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
EDGE-Shield achieves an approximate 79% reduction in processing time for Z-Image-Turbo... ROC-AUC of approximately 0.85
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
In: Computing Research Repository (CoRR) (2025)
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., Ge, W., Guo, Z., Huang, Q., Huang, J., Huang, F., Hui, B., Jiang, S., Li, Z., Li, M., Li, M., Li, K., Lin, Z., Lin, J., Liu, X., Liu, J., Liu, C., Liu, Y., Liu, D., Liu, S., Lu, D., Luo, R., Lv, C., Men, R., Meng, L., Ren, X., Ren, X., Song, S., Sun, Y., Tang, ...
work page 2025
-
[2]
Biswas, S.D., Roy, A., Roy, K.: CURE: Concept unlearning via orthogonal rep- resentation editing in diffusion models. In: Adv. Neural Inform. Process. Syst. (NeurIPS) (2025)
work page 2025
-
[3]
In: Proceedings of the 32nd USENIX Conference on Security Symposium (USENIX) (2023)
Carlini, N., Hayes, J., Nasr, M., Jagielski, M., Sehwag, V., Tramèr, F., Balle, B., Ippolito, D., Wallace, E.: Extracting training data from diffusion models. In: Proceedings of the 32nd USENIX Conference on Security Symposium (USENIX) (2023)
work page 2023
-
[4]
In: Computing Research Repository (CoRR) (2024)
Chi, J., Karn, U., Zhan, H., Smith, E., Rando, J., Zhang, Y., Plawiak, K., Coudert, Z.D., Upasani, K., Pasupuleti, M.: Llama guard 3 vision: Safeguarding human-ai image understanding conversations. In: Computing Research Repository (CoRR) (2024)
work page 2024
-
[5]
Cywiński, B., Deja, K.: SAeuron: Interpretable concept unlearning in diffusion models with sparse autoencoders. In: Int. Conf. Mach. Learn. (ICML) (2025)
work page 2025
-
[6]
Gaintseva, T., Oncescu, A.M., Ma, C., Liu, Z., Benning, M., Slabaugh, G., Deng, J., Elezi, I.: CASteer: Cross-attention steering for controllable concept erasure. In: Int. Conf. Learn. Represent. (ICLR) (2026)
work page 2026
-
[7]
In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) (2024)
Gandikota, R., Orgad, H., Belinkov, Y., Materzyńska, J., Bau, D.: Unified concept editing in diffusion models. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) (2024)
work page 2024
-
[8]
Gao, D., Lu, S., Walters, S., Zhou, W., Chu, J., Zhang, J., Zhang, B., Jia, M., Zhao, J., Fan, Z., et al.: Eraseanything: Enabling concept erasure in rectified flow transformers. In: Int. Conf. Mach. Learn. (ICML) (2024)
work page 2024
-
[9]
Helff, L., Friedrich, F., Brack, M., Kersting, K., Schramowski, P.: Llavaguard: An open VLM-based framework for safeguarding vision datasets and models. In: Int. Conf. Mach. Learn. (ICML) (2025)
work page 2025
-
[10]
In: Computing Research Repository (CoRR) (2023)
Inan, H., Upasani, K., Chi, J., Rungta, R., Iyer, K., Mao, Y., Tontchev, M., Hu, Q., Fuller, B., Testuggine, D., Khabsa, M.: Llama guard: Llm-based input-output safeguard for human-ai conversations. In: Computing Research Repository (CoRR) (2023)
work page 2023
-
[11]
In: Computing Research Repository (CoRR) (2025)
Kim, D., Ghadiyaram, D.: Concept steerers: Leveraging k-sparse autoencoders for test-time controllable generations. In: Computing Research Repository (CoRR) (2025)
work page 2025
-
[12]
Kim, M., Kim, D., Yusuf, A., Ermon, S., Park, M.: Training-free safe denoisers for safe use of diffusion models. In: Adv. Neural Inform. Process. Syst. (NeurIPS) (2025)
work page 2025
-
[13]
Kotar, K., Tian, S., Yu, H.X., Yamins, D.L.K., Wu, J.: Are these the same apple? comparing images based on object intrinsics. In: Proceedings of the 37th Interna- tional Conference on Neural Information Processing Systems (ICONIP) (2023)
work page 2023
-
[14]
In: Symposium on Operating Systems Principles (SOSP) (2023)
Kwon, W., Li, Z., Zhuang, S., Sheng, Y., Zheng, L., Yu, C.H., Gonzalez, J., Zhang, H., Stoica, I.: Efficient memory management for large language model serving with pagedattention. In: Symposium on Operating Systems Principles (SOSP) (2023)
work page 2023
-
[15]
In: Computing Research Repository (CoRR) (2025) 16 F
Labs,B.F.,Batifol,S.,Blattmann,A.,Boesel,F.,Consul,S.,Diagne,C.,Dockhorn, T., English, J., English, Z., Esser, P., Kulal, S., Lacey, K., Levi, Y., Li, C., Lorenz, D., Müller, J., Podell, D., Rombach, R., Saini, H., Sauer, A., Smith, L.: Flux.1 kontext: Flow matching for in-context image generation and editing in latent space. In: Computing Research Reposi...
work page 2025
-
[16]
Li, L., Shi, Z., Hu, X., Dong, B., Qin, Y., Liu, X., Sheng, L., Shao, J.: T2isafety: Benchmark for assessing fairness, toxicity, and privacy in image generation. In: IEEE Conf. Comput. Vis. Pattern Recog. (CVPR) (2025)
work page 2025
-
[17]
In: Computing Research Repository (CoRR) (2026)
Li, M., Zhang, Y., Long, D., Chen, K., Song, S., Bai, S., Yang, Z., Xie, P., Yang, A., Liu, D., Zhou, J., Lin, J.: Qwen3-vl-embedding and qwen3-vl-reranker: A unified framework for state-of-the-art multimodal retrieval and ranking. In: Computing Research Repository (CoRR) (2026)
work page 2026
-
[18]
In: Com- puting Research Repository (CoRR) (2026)
Li, T., He, K.: Back to basics: Let denoising generative models denoise. In: Com- puting Research Repository (CoRR) (2026)
work page 2026
-
[19]
In: Computing Research Repository (CoRR) (2024)
Liu, H., Li, C., Li, Y., Li, B., Zhang, Y., Shen, S., Lee, Y.J.: Llava-next: Improved reasoning, ocr, and world knowledge. In: Computing Research Repository (CoRR) (2024)
work page 2024
-
[20]
Liu,H.,Li,C.,Wu,Q.,Lee,Y.J.:Visualinstructiontuning.In:Adv.NeuralInform. Process. Syst. (NeurIPS) (2023)
work page 2023
-
[21]
In: Computing Research Repository (CoRR) (2026)
Liu, M., Zhang, S., Long, C.: Wukong framework for not safe for work detection in text-to-image systems. In: Computing Research Repository (CoRR) (2026)
work page 2026
-
[22]
Liu, R., Khakzar, A., Gu, J., Chen, Q., Torr, P., Pizzati, F.: Latent guard: A safety framework for text-to-image generation. In: Eur. Conf. Comput. Vis. (ECCV) (2024)
work page 2024
-
[23]
Liu, S., Shi, Z., Lyu, L., Jin, Y., Faltings, B.: Copyjudge: Automated copyright infringement identification and mitigation in text-to-image diffusion models. In: ACM Int. Conf. Multimedia (ACMMM) (2025)
work page 2025
-
[24]
Lu, S., Wang, Z., Li, L., Liu, Y., Kong, A.W.K.: Mace: Mass concept erasure in diffusion models. In: IEEE Conf. Comput. Vis. Pattern Recog. (CVPR) (2024)
work page 2024
-
[25]
In: Computing Research Repository (CoRR) (2024)
Ma, R., Zhou, Q., Jin, Y., Zhou, D., Xiao, B., Li, X., Qu, Y., Singh, A., Keutzer, K., Hu, J., Xie, X., Dong, Z., Zhang, S., Zhou, S.: A dataset and benchmark for copy- right infringement unlearning from text-to-image diffusion models. In: Computing Research Repository (CoRR) (2024)
work page 2024
-
[26]
In: Association for the Advancement of Artificial Intelligence (AAAI) (2023)
Markov, T., Zhang, C., Agarwal, S., Eloundou Nekoul, F., Lee, T., Adler, S., Jiang, A., Weng, L.: A holistic approach to undesired content detection in the real world. In: Association for the Advancement of Artificial Intelligence (AAAI) (2023)
work page 2023
-
[27]
Moon, S., Lee, M., Park, S., Kim, D.: Holistic unlearning benchmark: A multi- facetedevaluationfortext-to-imagediffusionmodelunlearning.In:Int.Conf.Com- put. Vis. (ICCV) (2025)
work page 2025
-
[28]
In: Computing Research Repository (CoRR) (2024)
OpenAI, :, Hurst, A., Lerer, A., Goucher, A.P., Perelman, A., Ramesh, A., Clark, A., Ostrow, A., Welihinda, A., Hayes, A., Radford, A., Mądry, A., Baker- Whitcomb,A.,Beutel,A.,Borzunov,A.,Carney,A.,Chow,A.,Kirillov,A.,Nichol, A., Paino, A., Renzin, A., Passos, A.T., Kirillov, A., Christakis, A., Conneau, A., Kamali, A., Jabri, A., Moyer, A., Tam, A., Croo...
work page 2024
-
[29]
Pizzi, E., Roy, S.D., Ravindra, S.N., Goyal, P., Douze, M.: A self-supervised de- scriptor for image copy detection. In: IEEE Conf. Comput. Vis. Pattern Recog. 18 F. Author et al. (CVPR) (2022)
work page 2022
-
[30]
Podell, D., English, Z., Lacey, K., Blattmann, A., Dockhorn, T., Müller, J., Penna, J., Rombach, R.: SDXL: Improving latent diffusion models for high-resolution im- age synthesis. In: Int. Conf. Learn. Represent. (ICLR) (2024)
work page 2024
-
[31]
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., Sutskever, I.: Learning transfer- able visual models from natural language supervision. In: Int. Conf. Mach. Learn. (ICML) (2021)
work page 2021
-
[32]
In: Computing Research Repository (CoRR) (2022)
Ramesh, A., Dhariwal, P., Nichol, A., Chu, C., Chen, M.: Hierarchical text- conditional image generation with clip latents. In: Computing Research Repository (CoRR) (2022)
work page 2022
-
[33]
In: NeurIPS ML Safety Workshop (2022)
Rando, J., Paleka, D., Lindner, D., Heim, L., Tramer, F.: Red-teaming the stable diffusion safety filter. In: NeurIPS ML Safety Workshop (2022)
work page 2022
-
[34]
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: IEEE Conf. Comput. Vis. Pattern Recog. (CVPR) (2022)
work page 2022
-
[35]
Schramowski, P., Brack, M., Deiseroth, B., Kersting, K.: Safe latent diffusion: Mitigatinginappropriatedegenerationindiffusionmodels.In:IEEEConf.Comput. Vis. Pattern Recog. (CVPR) (2023)
work page 2023
-
[36]
Shi, Z., Yan, J., Tang, X., Lyu, L., Faltings, B.: Rlcp: A reinforcement learning- based copyright protection method for text-to-image diffusion model. In: Int. Conf. Multimedia and Expo (ICME) (2025)
work page 2025
-
[37]
Song, Y., Liu, X., Shou, M.Z.: Diffsim: Taming diffusion models for evaluating visual similarity. In: Int. Conf. Comput. Vis. (ICCV) (2025)
work page 2025
-
[38]
In: Computing Research Repository (CoRR) (2025)
Team, I., Cai, H., Cao, S., Du, R., Gao, P., Hoi, S., Hou, Z., Huang, S., Jiang, D., Jin, X., Li, L., Li, Z., Li, Z.Y., Liu, D., Liu, D., Shi, J., Wu, Q., Yu, F., Zhang, C., Zhang, S., Zhou, S.: Z-image: An efficient image generation foundation model with single-stream diffusion transformer. In: Computing Research Repository (CoRR) (2025)
work page 2025
-
[39]
In: Computing Research Repository (CoRR) (2025)
Tschannen, M., Gritsenko, A., Wang, X., Naeem, M.F., Alabdulmohsin, I., Parthasarathy, N., Evans, T., Beyer, L., Xia, Y., Mustafa, B., Hénaff, O., Harm- sen, J., Steiner, A., Zhai, X.: Siglip 2: Multilingual vision-language encoders with improved semantic understanding, localization, and dense features. In: Computing Research Repository (CoRR) (2025)
work page 2025
-
[40]
In: Computing Research Repository (CoRR) (2025)
Wang, W., Gao, Z., Gu, L., Pu, H., Cui, L., Wei, X., Liu, Z., Jing, L., Ye, S., Shao, J., Wang, Z., Chen, Z., Zhang, H., Yang, G., Wang, H., Wei, Q., Yin, J., Li, W., Cui, E., Chen, G., Ding, Z., Tian, C., Wu, Z., Xie, J., Li, Z., Yang, B., Duan, Y., Wang, X., Hou, Z., Hao, H., Zhang, T., Li, S., Zhao, X., Duan, H., Deng, N., Fu, B., He, Y., Wang, Y., He,...
work page 2025
-
[41]
Wang, W., Sun, Y., Tan, Z., Yang, Y.: Image copy detection for diffusion models. In: Adv. Neural Inform. Process. Syst. (NeurIPS) (2024)
work page 2024
-
[42]
In: Computing Research Repository (CoRR) (2025)
Wu, C., Li, J., Zhou, J., Lin, J., Gao, K., Yan, K., ming Yin, S., Bai, S., Xu, X., Chen, Y., Chen, Y., Tang, Z., Zhang, Z., Wang, Z., Yang, A., Yu, B., Cheng, C., Liu, D., Li, D., Zhang, H., Meng, H., Wei, H., Ni, J., Chen, K., Cao, K., Peng, L., Abbreviated paper title 19 Qu, L., Wu, M., Wang, P., Yu, S., Wen, T., Feng, W., Xu, X., Wang, Y., Zhang, Y., ...
work page 2025
-
[43]
In: Computing Research Repository (CoRR) (2025)
Yang, F., Huang, Y., Zhu, J., Shi, L., Pu, G., Dong, J.S., Wang, K.: Seeing it before it happens: In-generation NSFW detection for diffusion-based text-to-image models. In: Computing Research Repository (CoRR) (2025)
work page 2025
-
[44]
Yang, Y., Gao, R., Yang, X., Zhong, J., Xu, Q.: Guardt2i: Defending text-to-image models from adversarial prompts. In: Adv. Neural Inform. Process. Syst. (NeurIPS) (2024)
work page 2024
-
[45]
Yoon, J., Yu, S., Patil, V., Yao, H., Bansal, M.: Safree: Training-free and adaptive guard for safe text-to-image and video generation. In: Int. Conf. Learn. Represent. (ICLR) (2025)
work page 2025
-
[46]
Zhai, X., Mustafa, B., Kolesnikov, A., Beyer, L.: Sigmoid loss for language image pre-training. In: Int. Conf. Comput. Vis. (ICCV) (2023)
work page 2023
-
[47]
Zhang, R., Isola, P., Efros, A.A., Shechtman, E., Wang, O.: The unreasonable effectiveness of deep features as a perceptual metric. In: IEEE Conf. Comput. Vis. Pattern Recog. (CVPR) (2018) A Additional Results A.1 Application to noise-based generative models Noise-based Models.In accordance with Eq. 1 in the main draft, noise-based models employ a linear ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.