Sustainable Transfer Learning for Adaptive Robot Skills
Pith reviewed 2026-05-10 18:11 UTC · model grok-4.3
The pith
Fine-tuning transferred policies improves success and cuts training steps for robot peg-in-hole tasks across platforms.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
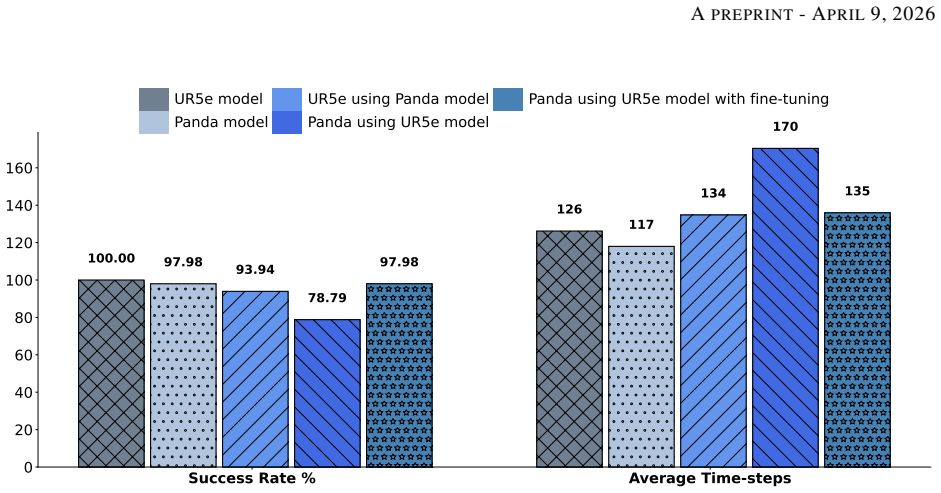
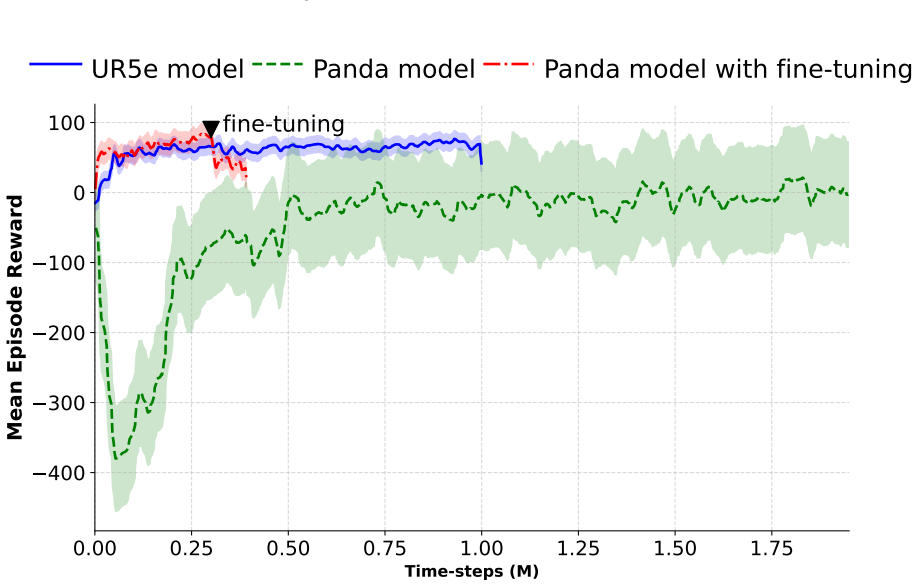
Policy transfer with adaptation techniques improves sample efficiency and generalization, reducing the need for extensive retraining: zero-shot transfer yields lower success rates and longer execution times, while fine-tuning the transferred policy significantly raises success rates and shortens both task time and required training steps compared with training from scratch.
What carries the argument
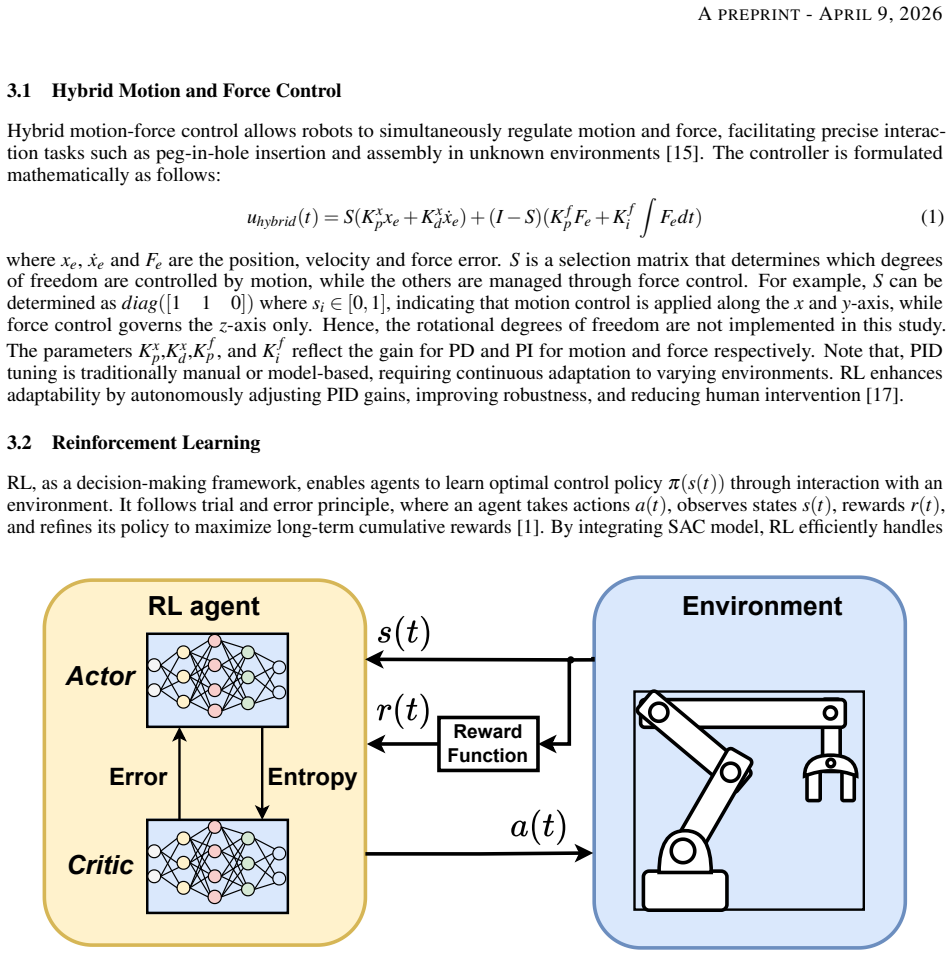
Policy transfer in reinforcement learning, tested via zero-shot application, fine-tuning, and full retraining on a peg-in-hole task across two distinct robotic platforms.
If this is right
- Fine-tuning reduces the number of training time-steps needed to reach usable performance.
- Zero-shot transfer produces lower success rates and longer task execution times than either adaptation or retraining.
- Transfer with adaptation improves generalization across different robotic platforms.
- Overall sample efficiency rises because less new data collection and computation is required.
- Sustainable robotic learning becomes feasible by minimizing repeated full retraining cycles.
Where Pith is reading between the lines
- The same transfer pattern could shorten learning cycles for other contact-rich manipulation skills if their state spaces overlap sufficiently with the peg-in-hole case.
- Real-world sensor noise or small mechanical differences might narrow the gap between fine-tuning and from-scratch training, requiring additional domain-randomization steps.
- Combining the observed fine-tuning approach with simulation pre-training could further lower the total real-robot steps needed before deployment.
Load-bearing premise
The two robotic platforms and the peg-in-hole task are representative enough that the transfer benefits will appear for other tasks, robots, or real-world hardware and environment differences.
What would settle it
An experiment on a third robot or different insertion task in which fine-tuning the transferred policy requires as many or more training steps as training from scratch, or produces no gain in success rate, would falsify the claimed sample-efficiency advantage.
Figures

read the original abstract
Learning robot skills from scratch is often time-consuming, while reusing data promotes sustainability and improves sample efficiency. This study investigates policy transfer across different robotic platforms, focusing on peg-in-hole task using reinforcement learning (RL). Policy training is carried out on two different robots. Their policies are transferred and evaluated for zero-shot, fine-tuning, and training from scratch. Results indicate that zero-shot transfer leads to lower success rates and relatively longer task execution times, while fine-tuning significantly improves performance with fewer training time-steps. These findings highlight that policy transfer with adaptation techniques improves sample efficiency and generalization, reducing the need for extensive retraining and supporting sustainable robotic learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript empirically studies policy transfer in reinforcement learning for a peg-in-hole insertion task between two robotic platforms. It compares zero-shot transfer of a trained policy, fine-tuning after transfer, and training from scratch, reporting that zero-shot yields lower success rates and longer execution times while fine-tuning achieves higher performance with fewer training steps. The central claim is that such transfer-plus-adaptation improves sample efficiency and generalization, thereby supporting more sustainable robot skill learning.
Significance. If the empirical findings are reproduced with full experimental controls and shown to generalize beyond the single task, the work would usefully illustrate how policy adaptation can reduce retraining costs in contact-rich manipulation. The paper does not supply machine-checked proofs, reproducible code artifacts, or parameter-free derivations, so its contribution rests entirely on the strength of the reported experiments.
major comments (2)
- [Abstract] Abstract and Results section: the abstract states comparative outcomes (lower success rates for zero-shot, improved performance with fewer time-steps for fine-tuning) but supplies no details on training hyperparameters, success metrics (e.g., insertion tolerance or force thresholds), number of trials, statistical tests, or robot specifications (DOF, sensors, dynamics). Without these, the data cannot be verified to support the stated claims.
- [Results] Results / Discussion: the generalization claim (policy transfer with adaptation 'improves sample efficiency and generalization') rests on a single contact-rich task (peg-in-hole) executed on two specific platforms. No cross-task experiments, environment variations, or hardware perturbations are described that would test whether the observed reduction in training steps arises from transferable features rather than task- or platform-specific regularities.
minor comments (1)
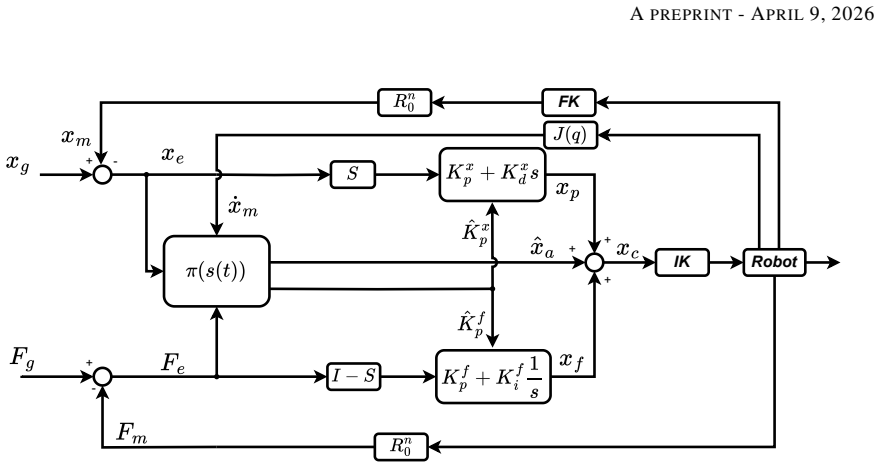
- [Methods] The manuscript would benefit from an explicit statement of the RL algorithm, state/action space definitions, and reward function used for the peg-in-hole task, ideally in a dedicated Methods subsection.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major comment below and indicate the revisions we plan to make.
read point-by-point responses
-
Referee: [Abstract] Abstract and Results section: the abstract states comparative outcomes (lower success rates for zero-shot, improved performance with fewer time-steps for fine-tuning) but supplies no details on training hyperparameters, success metrics (e.g., insertion tolerance or force thresholds), number of trials, statistical tests, or robot specifications (DOF, sensors, dynamics). Without these, the data cannot be verified to support the stated claims.
Authors: We agree that additional details are necessary for reproducibility and verification. We will revise the abstract to incorporate key information on the robot hardware (DOF, sensors), success metrics including insertion tolerance and force thresholds, the number of trials conducted, and relevant training hyperparameters. Furthermore, we will include statistical tests in the Results section to support the comparative outcomes reported. revision: yes
-
Referee: [Results] Results / Discussion: the generalization claim (policy transfer with adaptation 'improves sample efficiency and generalization') rests on a single contact-rich task (peg-in-hole) executed on two specific platforms. No cross-task experiments, environment variations, or hardware perturbations are described that would test whether the observed reduction in training steps arises from transferable features rather than task- or platform-specific regularities.
Authors: We acknowledge the limitation that our evaluation is based on a single task across two platforms. The peg-in-hole task serves as a representative contact-rich manipulation scenario, and the observed improvements in sample efficiency support our claims within this context. We will revise the Discussion to more clearly state the scope of our generalization claims, highlight this as a limitation, and discuss potential extensions to other tasks based on existing literature. This will prevent overstatement while maintaining the contribution of the work. revision: partial
- Conducting additional experiments on multiple tasks or with hardware perturbations to further substantiate the generalization claims.
Circularity Check
No circularity: purely empirical RL transfer results with no derivations or self-referential predictions
full rationale
The paper reports direct experimental measurements of success rates, task times, and training steps for zero-shot transfer, fine-tuning, and from-scratch training on a peg-in-hole task across two robotic platforms. No equations, fitted parameters presented as predictions, ansatzes, or uniqueness theorems appear in the provided text. Claims rest on observed data rather than any reduction to inputs by construction. Self-citations are absent from the abstract and described results, and the central comparison is externally falsifiable via replication on the stated hardware and task.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Policies learned via RL on one robot platform can be meaningfully transferred and adapted to a second platform for the same task structure.
Reference graph
Works this paper leans on
-
[1]
R. S. Sutton and A. G. Barto (2018).Reinforcement Learning: An Introduction. A Bradford Book, Cambridge, MA, USA
work page 2018
-
[2]
Open x-embodiment: Robotic learning datasets and RT-X models: Open x-embodiment collaboration 0,
A. O’Neill et al. (2024). “Open x-embodiment: Robotic learning datasets and RT-X models: Open x-embodiment collaboration 0,” inIEEE International Conference on Robotics and Automation (ICRA)
work page 2024
-
[3]
Octo: An Open-Source Generalist Robot Policy,
O. Mees et al. (2024). “Octo: An Open-Source Generalist Robot Policy,” inFirst Workshop on Vision-Language Models for Navigation and Manipulation at ICRA
work page 2024
-
[4]
Polybot: Training One Policy Across Robots While Embracing Variability,
J. H. Yang, D. Sadigh, and C. Finn (2023). “Polybot: Training One Policy Across Robots While Embracing Variability,” in7th Annual Conference on Robot Learning (CoRL)
work page 2023
-
[5]
Hardware conditioned policies for multi-robot transfer learning,
T. Chen, A. Murali, and A. Gupta (2018). “Hardware conditioned policies for multi-robot transfer learning,” in Advances in Neural Information Processing Systems (NeurIPS), 31
work page 2018
-
[6]
Learning modular neural network policies for multi-task and multi-robot transfer,
C. Devin et al. (2017). “Learning modular neural network policies for multi-task and multi-robot transfer,” in IEEE International Conference on Robotics and Automation (ICRA)
work page 2017
-
[7]
S. Reed et al. (2022). “A generalist agent,” inTransactions on Machine Learning Research
work page 2022
-
[8]
RoboNet: Large-Scale Multi-Robot Learning,
S. Dasari et al. (2020). “RoboNet: Large-Scale Multi-Robot Learning,” inConference on Robot Learning, PMLR, pp.885-897
work page 2020
-
[9]
Bayesian meta-learning for few-shot policy adaptation across robotic platforms,
A. Ghadirzadeh et al. (2021). “Bayesian meta-learning for few-shot policy adaptation across robotic platforms,” in IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)
work page 2021
-
[10]
Cross-domain adaptive transfer reinforcement learning based on state-action correspondence,
H. You et al. (2022). “Cross-domain adaptive transfer reinforcement learning based on state-action correspondence,” inUncertainty in Artificial Intelligence (UAI)
work page 2022
-
[11]
Robocat: A self-improving generalist agent for robotic manipulation,
K. Bousmalis et al. (2022). “Robocat: A self-improving generalist agent for robotic manipulation,” inTransactions on Machine Learning Research
work page 2022
-
[12]
Learning to control self-assembling morphologies: A study of generalization via modularity,
D. Pathak et al. (2019). “Learning to control self-assembling morphologies: A study of generalization via modularity,” inAdvances in Neural Information Processing Systems, 32
work page 2019
-
[13]
One policy to control them all: Shared modular policies for agent-agnostic control,
W. Huang et al. (2020). “One policy to control them all: Shared modular policies for agent-agnostic control,” in International Conference on Machine Learning, PMLR
work page 2020
-
[14]
Learn from Robot: Transferring Skills for Diverse Manipulation via Cycle Generative Networks,
Q. Yang et al. (2023). “Learn from Robot: Transferring Skills for Diverse Manipulation via Cycle Generative Networks,” inIEEE 19th International Conference on Automation Science and Engineering (CASE)
work page 2023
-
[15]
Hybrid motion/force control: a review,
V . Ortenzi et al. (2017). “Hybrid motion/force control: a review,” inAdvanced Robotics, 31(19-20), pp.1102-1113
work page 2017
-
[16]
O. A. Somefun et al. (2021). “The dilemma of PID tuning,” inAnnual Reviews in Control, 52, pp.65-74
work page 2021
-
[17]
C. C. Beltran-Hernandez et al. (2020). “Variable compliance control for robotic peg-in-hole assembly: A deep- reinforcement-learning approach,” inApplied Sciences, 10(19), p.6923
work page 2020
-
[18]
Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor,
T. Haarnoja et al. (2018). “Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor,” inInternational Conference on Machine Learning, PMLR
work page 2018
-
[19]
Stable-baselines3: Reliable reinforcement learning implementations,
A. Raffin et al. (2021). “Stable-baselines3: Reliable reinforcement learning implementations,” inJournal of Machine Learning Research, 22(268), pp.1-8
work page 2021
-
[20]
MuJoCo: A physics engine for model-based control,
E. Todorov, T. Erez, and Y . Tassa (2012). “MuJoCo: A physics engine for model-based control,” inIEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)
work page 2012
-
[21]
MuJoCo Menagerie: A collection of high-quality simulation models for MuJoCo,
M. M. Contributors (2021). “MuJoCo Menagerie: A collection of high-quality simulation models for MuJoCo,” [Online]. Available:http://github.com/deepmind/mujoco_menagerie. 7
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.