Dual-Loop Control in DCVerse: Advancing Reliable Deployment of AI in Data Centers via Digital Twins
Pith reviewed 2026-05-10 17:37 UTC · model grok-4.3
The pith
A dual-loop control framework with digital twins safely deploys reinforcement learning in data centers for energy savings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
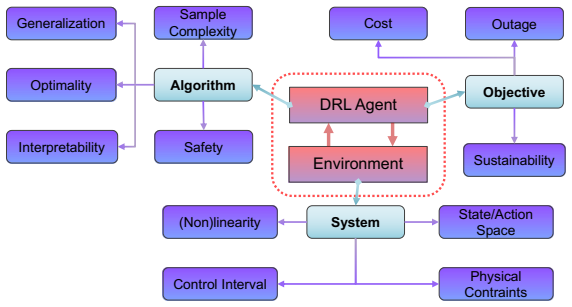
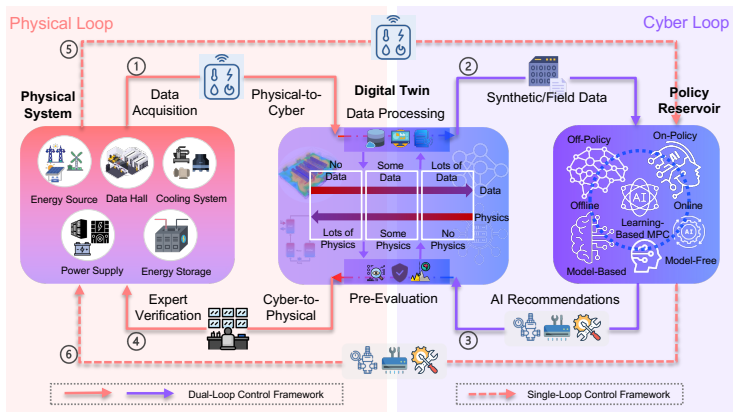
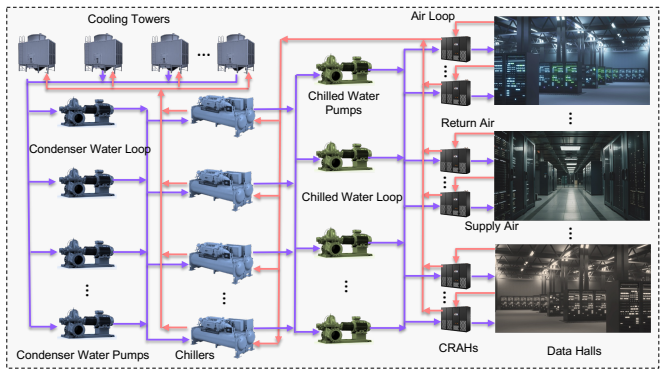
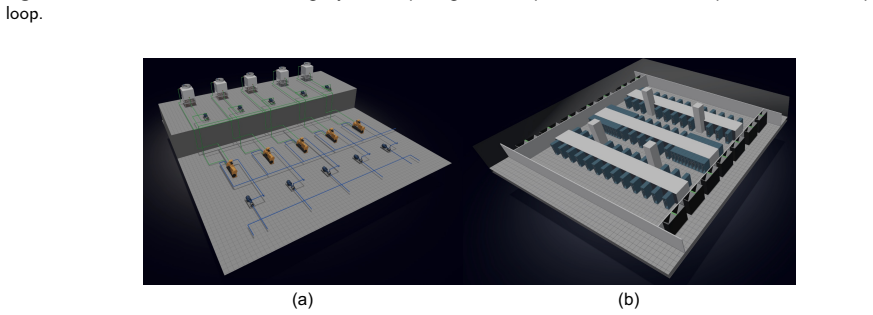
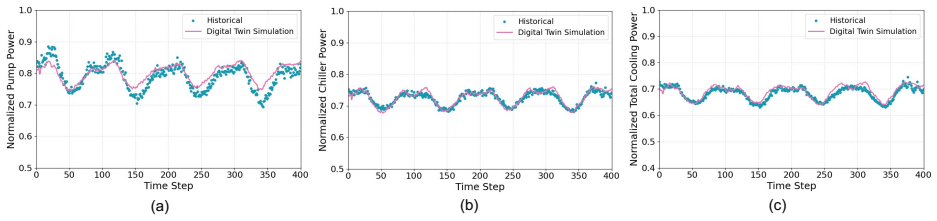
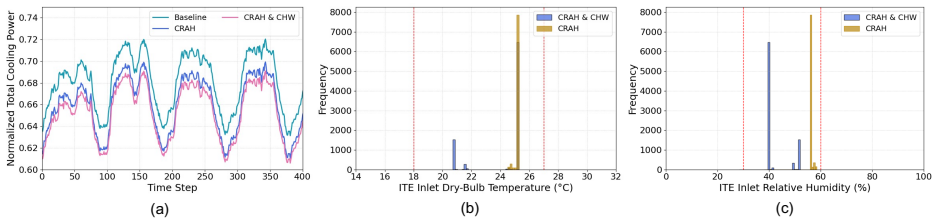
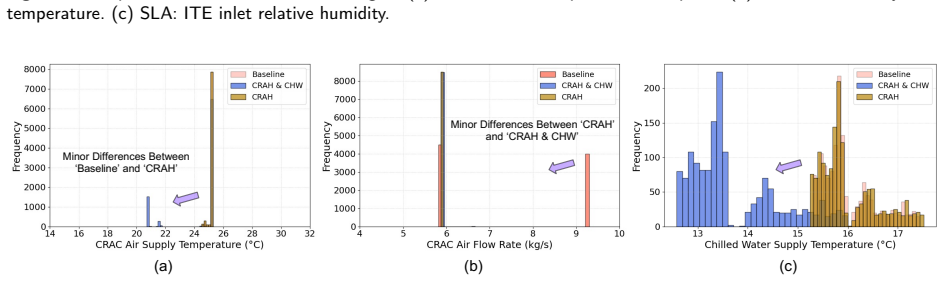
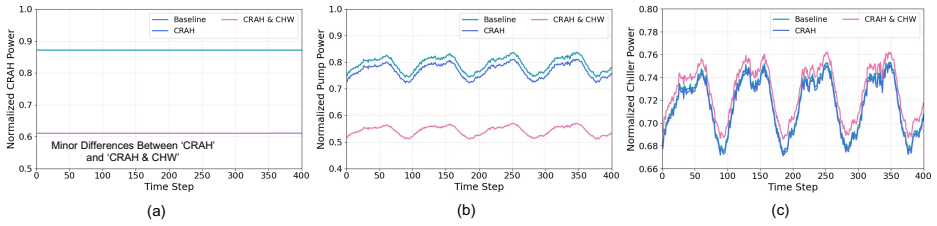
The Dual-Loop Control Framework (DLCF) consists of the physical system, a digital twin, and a policy reservoir of diverse DRL agents that interact via a dual-loop mechanism of data acquisition, assimilation, training, pre-evaluation, and expert verification. Theoretical analysis indicates improvements in sample efficiency, generalization, safety, and optimality. Implementation in the DCVerse platform on a real-world data center cooling system achieved up to 4.09% energy savings over conventional strategies without violating SLA requirements, while enhancing interpretability.
What carries the argument
The dual-loop mechanism linking the physical data center, its digital twin for simulation and pre-evaluation, and a reservoir of DRL policies for selection and verification.
If this is right
- Real-time policy training and pre-evaluation reduces the risk of unsafe actions in the physical system.
- The policy reservoir allows for diverse strategies that can be chosen based on current conditions.
- Expert verification step increases trust in the deployed AI policies.
- The framework provides a basis for extending AI control to more complex, holistic data center optimizations.
Where Pith is reading between the lines
- Extending the dual-loop approach to other AI-controlled infrastructure could mitigate deployment risks in high-stakes domains like autonomous systems or medical devices.
- If digital twins can be made more accurate over time through assimilation, the framework might enable continuous online optimization with minimal human oversight.
- Combining this with multi-agent systems could handle interactions between different subsystems like cooling and power management.
Load-bearing premise
The digital twin provides a sufficiently accurate model of the real data center dynamics for policies to transfer effectively without performance loss or safety issues.
What would settle it
Running the trained policy from the DCVerse platform on the physical data center cooling system for an extended period and measuring whether energy consumption decreases by around 4% while keeping all SLA metrics within required bounds.
Figures
read the original abstract
The growing scale and complexity of modern data centers present major challenges in balancing energy efficiency with outage risk. Although Deep Reinforcement Learning (DRL) shows strong potential for intelligent control, its deployment in mission-critical systems is limited by data scarcity and the lack of real-time pre-evaluation mechanisms. This paper introduces the Dual-Loop Control Framework (DLCF), a digital twin-based architecture designed to overcome these challenges. The framework comprises three core entities: the physical system, a digital twin, and a policy reservoir of diverse DRL agents. These components interact through a dual-loop mechanism involving real-time data acquisition, data assimilation, DRL policy training, pre-evaluation, and expert verification. Theoretical analysis shows how DLCF can improve sample efficiency, generalization, safety, and optimality. Leveraging DLCF, we implemented the DCVerse platform and validated it through case studies on a real-world data center cooling system. The evaluation shows that our approach achieves up to 4.09% energy savings over conventional control strategies without violating SLA requirements. Additionally, the framework improves policy interpretability and supports more trustworthy DRL deployment. This work provides a foundation for reliable AI-based control in data centers and points toward future extensions for holistic, system-wide optimization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Dual-Loop Control Framework (DLCF), a digital-twin architecture with a physical system, digital twin, and policy reservoir of DRL agents. It claims that the dual-loop mechanism (real-time data acquisition, assimilation, training, pre-evaluation, and expert verification) yields theoretical gains in sample efficiency, generalization, safety, and optimality, and reports empirical validation via the DCVerse platform on a real data-center cooling system that achieves up to 4.09% energy savings over conventional strategies without SLA violations.
Significance. If the digital-twin fidelity and sim-to-real transfer can be quantitatively established, the DLCF would provide a concrete mechanism for safer DRL deployment in mission-critical infrastructure, directly addressing data scarcity and the absence of pre-evaluation. The explicit construction of a policy reservoir and dual-loop interaction is a strength that could be extended to other control domains.
major comments (2)
- [Abstract] Abstract: the headline claim of 4.09% energy savings without SLA violations is presented as the outcome of DLCF pre-evaluation inside the digital twin, yet the abstract supplies no error metrics (RMSE on temperature, power, or flow), no calibration procedure against real sensor data, and no sim-to-real gap quantification or ablation showing that twin-predicted rewards match physical outcomes.
- [Abstract] Abstract and framework description: the central attribution of savings and safety to the dual-loop pre-evaluation rests on the unstated assumption that the digital twin is sufficiently faithful; without reported fidelity metrics or transfer experiments, the savings cannot be confidently distinguished from direct tuning or other uncontrolled factors.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for greater transparency on digital-twin fidelity in the abstract. We address each comment below and have revised the manuscript to strengthen the presentation of supporting evidence from the case studies.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claim of 4.09% energy savings without SLA violations is presented as the outcome of DLCF pre-evaluation inside the digital twin, yet the abstract supplies no error metrics (RMSE on temperature, power, or flow), no calibration procedure against real sensor data, and no sim-to-real gap quantification or ablation showing that twin-predicted rewards match physical outcomes.
Authors: We agree that the abstract, as a concise summary, omits explicit fidelity metrics that appear in the experimental sections. The full manuscript reports calibration against real sensor data and sim-to-real transfer results in the DCVerse case studies, including comparisons of twin-predicted versus observed outcomes. In revision we will add a single sentence to the abstract summarizing these fidelity aspects and directing readers to the relevant sections, thereby clarifying that the reported savings derive from policies pre-evaluated in the calibrated twin rather than from uncontrolled factors. revision: yes
-
Referee: [Abstract] Abstract and framework description: the central attribution of savings and safety to the dual-loop pre-evaluation rests on the unstated assumption that the digital twin is sufficiently faithful; without reported fidelity metrics or transfer experiments, the savings cannot be confidently distinguished from direct tuning or other uncontrolled factors.
Authors: The manuscript grounds the attribution in both the theoretical analysis of the dual-loop mechanism and the empirical results obtained on the physical data-center system after twin-based pre-evaluation. Detailed fidelity metrics and transfer experiments are already present in the body of the paper. To make this explicit at the abstract level, we will insert a brief clause referencing the calibration and transfer performance documented in the case studies, ensuring readers can immediately distinguish the contribution of the dual-loop pre-evaluation. revision: yes
Circularity Check
No significant circularity in derivation chain
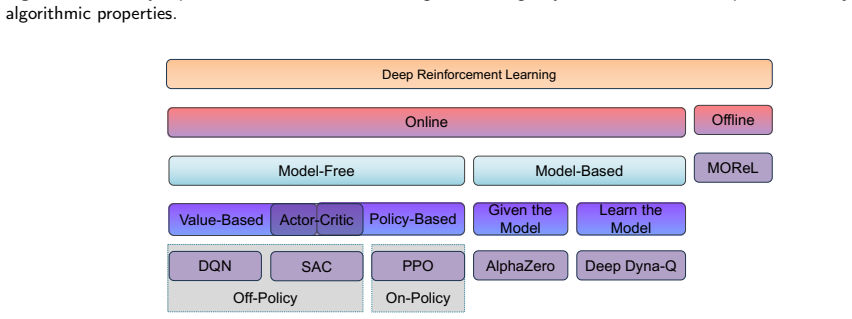
full rationale
The paper's chain proceeds from problem statement to introduction of the DLCF architecture (physical system + digital twin + policy reservoir), dual-loop interaction mechanisms, theoretical analysis of improvements in sample efficiency/generalization/safety/optimality, platform implementation, and empirical validation via real-world case studies reporting 4.09% energy savings. No equations or steps reduce by construction to inputs; no fitted parameters are relabeled as predictions; no load-bearing self-citations or uniqueness theorems imported from prior author work appear in the abstract or framework description. The reported results are tied to external case studies on a physical cooling system rather than internal self-referential constructions, rendering the derivation self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The digital twin accurately simulates the physical data center dynamics for the purpose of policy pre-evaluation and training.
invented entities (2)
-
Dual-Loop Control Framework (DLCF)
no independent evidence
-
Policy reservoir
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Ai power: Expanding data center capacity to meet growing demand.McKinsey & Company, October 2024
McKinsey & Company. Ai power: Expanding data center capacity to meet growing demand.McKinsey & Company, October 2024
work page 2024
-
[2]
Electricity 2024 analysis and forecast to 2026, 2024
International Energy Agency. Electricity 2024 analysis and forecast to 2026, 2024. Available: https://iea.blob.core.windows.net/assets/18f3ed24-4b26-4c83-a3d2-8a1be51c8cc8/Electricity2024-Analysisandforecastto2026.pdf
work page 2024
-
[3]
Krishna Kant. Data center evolution: A tutorial on state of the art, issues, and challenges.Computer Networks, 53(17):2939–2965, 2009
work page 2009
-
[4]
2024 global data center survey
Uptime Institute. 2024 global data center survey. Technical report, Uptime Institute, 2024
work page 2024
-
[5]
Uptime’s 13th Annual Global Data Center Survey Shows Widening Range of Challenges, 2023
Uptime Institute. Uptime’s 13th Annual Global Data Center Survey Shows Widening Range of Challenges, 2023. Available: https://uptimeinstitute.com/about-ui/press-releases/uptimes-13th-annual-global-data-center-survey-shows-widening-range-of-challenges
work page 2023
-
[6]
Victor Avelar, Patrick Donovan, Paul Lin, and Wendy Torell. The ai disruption: Challenges and guidance for data center design.Artificial Intelligence in Medicine, 138, 2023
work page 2023
-
[7]
Qingxia Zhang, Zihao Meng, Xianwen Hong, Yuhao Zhan, Jia Liu, Jiabao Dong, Tian Bai, Junyu Niu, and M Jamal Deen. A survey on data center cooling systems: Technology, power consumption modeling and control strategy optimization.Journal of Systems Architecture, 119:102253, 2021
work page 2021
-
[8]
HussainKahil,ShivaSharma,PetriVälisuo,andMohammedElmusrati.Reinforcementlearningfordatacenterenergyefficiencyoptimization: A systematic literature review and research roadmap.Applied Energy, 389:125734, 2025
work page 2025
-
[9]
QingangZhang,WeiZeng,QinjieLin,Chin-BoonChng,Chee-KongChui,andPoh-SengLee.Deepreinforcementlearningtowardsreal-world dynamic thermal management of data centers.Applied Energy, 333:120561, 2023
work page 2023
-
[10]
Duc Van Le, Rongrong Wang, Yingbo Liu, Rui Tan, Yew-Wah Wong, and Yonggang Wen. Deep reinforcement learning for tropical air free-cooled data center control.ACM Transactions on Sensor Networks (TOSN), 17(3):1–28, 2021
work page 2021
-
[11]
Transformingcoolingoptimizationforgreendatacenterviadeepreinforcement learning
YuanlongLi,YonggangWen,DachengTao,andKyleGuan. Transformingcoolingoptimizationforgreendatacenterviadeepreinforcement learning. IEEE transactions on cybernetics, 50(5):2002–2013, 2019
work page 2002
-
[12]
Optimizing energy efficiency for data center via parameterized deep reinforcement learning
Yongyi Ran, Han Hu, Yonggang Wen, and Xin Zhou. Optimizing energy efficiency for data center via parameterized deep reinforcement learning. IEEE Transactions on Services Computing, 16(2):1310–1323, 2022
work page 2022
-
[13]
Intelligent Dynamic Thermal Control Using Deep Learning and Reinforcement Learning
Zhang Qingang. Intelligent Dynamic Thermal Control Using Deep Learning and Reinforcement Learning. PhD thesis, National University of Singapore (Singapore), 2023
work page 2023
-
[14]
Safecool:safeandenergy-efficientcoolingmanagementin datacenterswithmodel-basedreinforcementlearning
JianxiongWan,YanduoDuan,XiangGui,ChuyiLiu,LeixiaoLi,andZhiqiangMa. Safecool:safeandenergy-efficientcoolingmanagementin datacenterswithmodel-basedreinforcementlearning. IEEETransactionsonEmergingTopicsinComputationalIntelligence ,7(6):1621–1635, 2023
work page 2023
-
[15]
Efficientcompute-intensivejoballocationindatacentersviadeepreinforcementlearning
DeliangYi,XinZhou,YonggangWen,andRuiTan. Efficientcompute-intensivejoballocationindatacentersviadeepreinforcementlearning. IEEE Transactions on Parallel and Distributed Systems, 31(6):1474–1485, 2020
work page 2020
-
[16]
ArezooGhasemiandAminKeshavarzi.Energy-efficientvirtualmachineplacementinheterogeneousclouddatacenters:aclustering-enhanced multi-objective, multi-reward reinforcement learning approach.Cluster Computing, 27(10):14149–14166, 2024
work page 2024
-
[17]
Arezoo Ghasemi, Abolfazl Toroghi Haghighat, and Amin Keshavarzi. Enhancing virtual machine placement efficiency in cloud data centers: a hybrid approach using multi-objective reinforcement learning and clustering strategies.Computing, 106(9):2897–2922, 2024. 24
work page 2024
-
[18]
Joint it-facility optimization for green data centers via deep reinforcement learning
Xin Zhou, Ruihang Wang, Yonggang Wen, and Rui Tan. Joint it-facility optimization for green data centers via deep reinforcement learning. IEEE Network, 35(6):255–262, 2021
work page 2021
-
[19]
Jacobien HF Oosterhoff and Job N Doornberg. Artificial intelligence in orthopaedics: false hope or not? a narrative review along the line of gartner’s hype cycle.EFORT open reviews, 5(10):593–603, 2020
work page 2020
-
[20]
MuhammadHaiqalBinMahbod,ChinBoonChng,PohSengLee,andCheeKongChui. Energysavingevaluationofanenergyefficientdata center using a model-free reinforcement learning approach.Applied Energy, 322:119392, 2022
work page 2022
-
[21]
Qingang Zhang, Muhammad Haiqal Bin Mahbod, Chin-Boon Chng, Poh-Seng Lee, and Chee-Kong Chui. Residual physics and post-posed shielding for safe deep reinforcement learning method.IEEE transactions on cybernetics, 54(2):865–876, 2022
work page 2022
-
[22]
Qingang Zhang, Chin-Boon Chng, Kaiqi Chen, Poh-Seng Lee, and Chee-Kong Chui. Drl-s: Toward safe real-world learning of dynamic thermal management in data center.Expert Systems with Applications, 214:119146, 2023
work page 2023
-
[23]
Greendatacentercoolingcontrolviaphysics-guidedsafereinforcement learning
RuihangWang,ZhiweiCao,XinZhou,YonggangWen,andRuiTan. Greendatacentercoolingcontrolviaphysics-guidedsafereinforcement learning. ACM Transactions on Cyber-Physical Systems, 8(2):1–26, 2024
work page 2024
-
[24]
Towardmodel-assistedsafereinforcementlearningfordatacentercoolingcontrol: A lyapunov-based approach
ZhiweiCao,RuihangWang,XinZhou,andYonggangWen. Towardmodel-assistedsafereinforcementlearningfordatacentercoolingcontrol: A lyapunov-based approach. InProceedings of the 14th ACM International Conference on Future Energy Systems, pages 333–346, 2023
work page 2023
-
[25]
Qingang Zhang, Chin-Boon Chng, Chee-Kong Chui, and Poh-Seng Lee. Uncertainty-aware online learning of dynamic thermal control in data center with imperfect pretrained models.Expert Systems with Applications, 249:123767, 2024
work page 2024
-
[26]
Data center cooling using model-predictive control
Nevena Lazic, Craig Boutilier, Tyler Lu, Eehern Wong, Binz Roy, MK Ryu, and Greg Imwalle. Data center cooling using model-predictive control. Advances in Neural Information Processing Systems, 31, 2018
work page 2018
-
[27]
Large-scale data center cooling control via sample-efficient reinforcement learning
Ni Mu, Xiao Hu, Qing-Shan Jia, Xu Zhu, and Xiao He. Large-scale data center cooling control via sample-efficient reinforcement learning. In 2024 IEEE 20th International Conference on Automation Science and Engineering (CASE), pages 2780–2785. IEEE, 2024
work page 2024
-
[28]
Xianyuan Zhan, Xiangyu Zhu, Peng Cheng, Xiao Hu, Ziteng He, Hanfei Geng, Jichao Leng, Huiwen Zheng, Chenhui Liu, Tianshun Hong, et al. Data center cooling system optimization using offline reinforcement learning.arXiv preprint arXiv:2501.15085, 2025
-
[29]
Rafael Figueiredo Prudencio, Marcos ROA Maximo, and Esther Luna Colombini. A survey on offline reinforcement learning: Taxonomy, review, and open problems.IEEE Transactions on Neural Networks and Learning Systems, 2023
work page 2023
-
[30]
The National Academies Press, 2023
National Academies of Sciences, Engineering, and Medicine.Foundational Research Gaps and Future Directions for Digital Twins. The National Academies Press, 2023
work page 2023
-
[31]
Digital twin modeling.Journal of Manufacturing Systems, 64:372–389, 2022
Fei Tao, Bin Xiao, Qinglin Qi, Jiangfeng Cheng, and Ping Ji. Digital twin modeling.Journal of Manufacturing Systems, 64:372–389, 2022
work page 2022
-
[32]
Digital transformation: Lights and shadows
Paolo Faraboschi, Eitan Frachtenberg, Phil Laplante, Dejan Milojicic, and Roberto Saracco. Digital transformation: Lights and shadows. Computer, 56(4):123–130, 2023
work page 2023
-
[33]
QingangZhang,WenjunLong,RuihangWang,ZhiweiCao,ZhaoyangWang,YuejunYan,andYonggangWen. Caper:Dual-levelphysics-data fusion with modular metamodels for reliable generalization in predictive digital twins.Applied Energy, 398:126393, 2025
work page 2025
-
[34]
Lorenzo Schena, Pedro A Marques, Romain Poletti, Samuel Ahizi, Jan Van den Berghe, and Miguel A Mendez. Reinforcement twinning: From digital twins to model-based reinforcement learning.Journal of Computational Science, 82:102421, 2024
work page 2024
-
[35]
Zhengming Zhang, Yongming Huang, Cheng Zhang, Qingbi Zheng, Luxi Yang, and Xiaohu You. Digital twin-enhanced deep reinforcement learning for resource management in networks slicing.IEEE Transactions on Communications, 2024
work page 2024
-
[36]
Nan Cheng, Xiucheng Wang, Zan Li, Zhisheng Yin, Tom Luan, and Xuemin Sherman Shen. Toward enhanced reinforcement learning-based resource management via digital twin: Opportunities, applications, and challenges.IEEE Network, 2024. 25
work page 2024
-
[37]
Kaishu Xia, Christopher Sacco, Max Kirkpatrick, Clint Saidy, Lam Nguyen, Anil Kircaliali, and Ramy Harik. A digital twin to train deep reinforcement learning agent for smart manufacturing plants: Environment, interfaces and intelligence.Journal of Manufacturing Systems, 58:210–230, 2021
work page 2021
-
[38]
Jun Zhou, Mei Yang, Yong Zhan, and Li Xu. Digital twin application for reinforcement learning based optimal scheduling and reliability management enhancement of systems.Solar Energy, 252:29–38, 2023
work page 2023
-
[39]
Yiming Ye, Bin Xu, Hanchen Wang, Jiangfeng Zhang, Benjamin Lawler, and Beshah Ayalew. Deep reinforcement learning-based energy management system enhancement using digital twin for electric vehicles.Energy, 312:133384, 2024
work page 2024
-
[40]
Digital twins for data centers.Computer, 57(10):151–158, 2024
Jyotika Athavale, Cullen Bash, Wesley Brewer, Matthias Maiterth, Dejan Milojicic, Harry Petty, and Soumyendu Sarkar. Digital twins for data centers.Computer, 57(10):151–158, 2024
work page 2024
-
[41]
Onthesamplecomplexityofreinforcementlearning
ShamMachandranathKakade. Onthesamplecomplexityofreinforcementlearning . UniversityofLondon,UniversityCollegeLondon(United Kingdom), 2003
work page 2003
-
[42]
WenSun,NanJiang,AkshayKrishnamurthy,AlekhAgarwal,andJohnLangford. Model-basedrlincontextualdecisionprocesses:Pacbounds and exponential improvements over model-free approaches. InConference on learning theory, pages 2898–2933. PMLR, 2019
work page 2019
-
[43]
Tianhe Yu, Garrett Thomas, Lantao Yu, Stefano Ermon, James Y Zou, Sergey Levine, Chelsea Finn, and Tengyu Ma. Mopo: Model-based offline policy optimization.Advances in Neural Information Processing Systems, 33:14129–14142, 2020
work page 2020
-
[44]
Morel: Model-based offline reinforcement learning
Rahul Kidambi, Aravind Rajeswaran, Praneeth Netrapalli, and Thorsten Joachims. Morel: Model-based offline reinforcement learning. Advances in neural information processing systems, 33:21810–21823, 2020
work page 2020
-
[45]
Red dot analytics help data centres be cool
IMDA. Red dot analytics help data centres be cool. https://www.imda.gov.sg/resources/blog/blog-articles/2025/02/ red-dot-analytics-help-data-centres-be-cool . Accessed: May 14, 2025
work page 2025
-
[46]
Drury B Crawley, Linda K Lawrie, Frederick C Winkelmann, Walter F Buhl, Y Joe Huang, Curtis O Pedersen, Richard K Strand, Richard J Liesen, Daniel E Fisher, Michael J Witte, et al. Energyplus: creating a new-generation building energy simulation program.Energy and buildings, 33(4):319–331, 2001
work page 2001
-
[47]
Jiayi Weng, Huayu Chen, Dong Yan, Kaichao You, Alexis Duburcq, Minghao Zhang, Yi Su, Hang Su, and Jun Zhu. Tianshou: A highly modularized deep reinforcement learning library.Journal of Machine Learning Research, 23(267):1–6, 2022. 26
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.