A Predictive View on Streaming Hidden Markov Models
Pith reviewed 2026-05-10 16:59 UTC · model grok-4.3
The pith
Streaming HMMs admit an exact recursive beam-search algorithm via the renormalized top-S posterior-weighted mixture.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
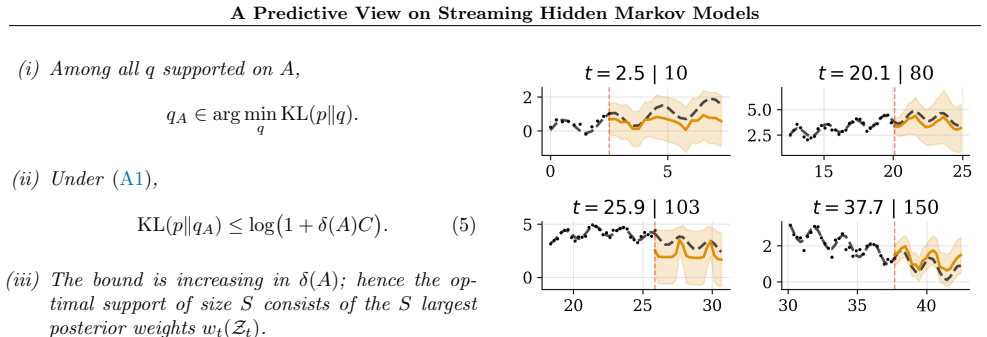
Under a fixed transition prior and online-learned regime-specific predictors, the forward-KL optimal mixture supported on S paths is exactly the renormalized top-S posterior-weighted mixture; this object then serves as the predictive distribution for the next observation and recurses with closed-form updates.
What carries the argument
The renormalised top-S posterior-weighted mixture, which solves the constrained forward-KL projection onto S-path predictive mixtures and yields the beam-search truncation rule.
Load-bearing premise
The method assumes access to regime-specific predictive models that can be learned online and that projecting the posterior predictive onto the top-S paths under forward KL gives a useful approximation.
What would settle it
On a held-out sequence, if the predictive log-likelihood of the S-mixture is materially worse than that of a full posterior or a much larger beam, or if prequential performance falls below Online EM and SMC under identical compute, the approximation quality is refuted.
Figures


read the original abstract
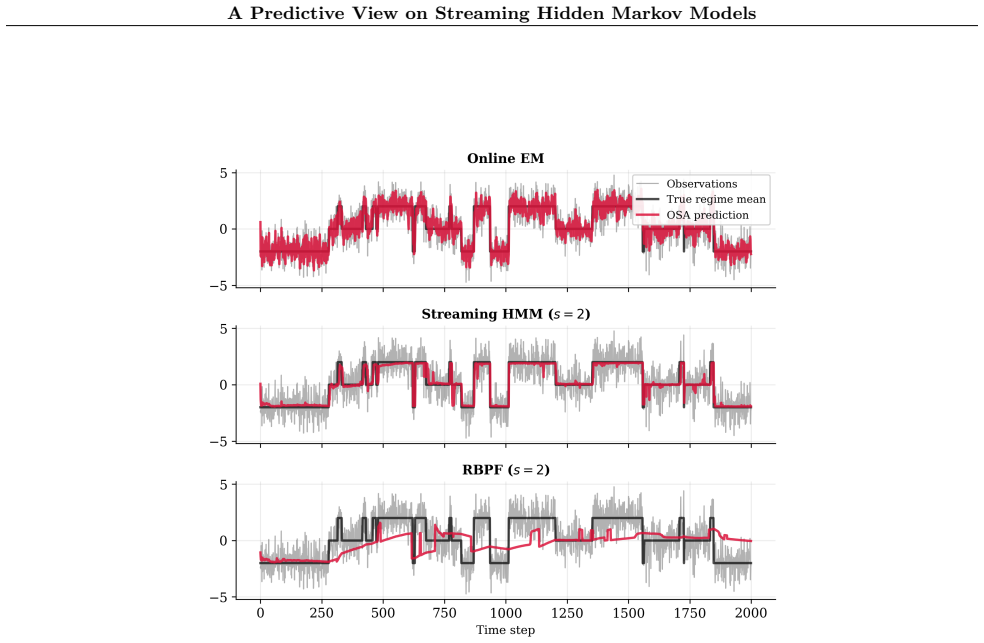
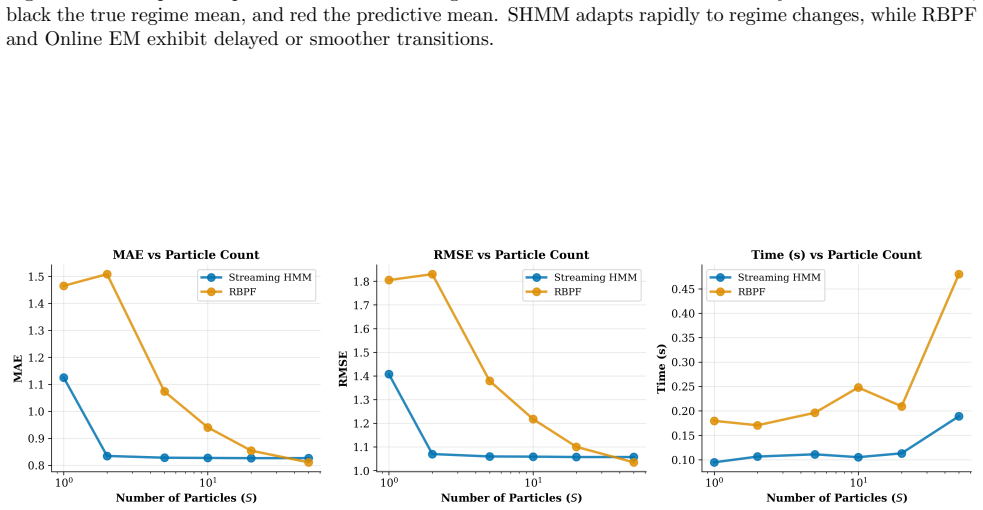
We develop a predictive-first optimisation framework for streaming hidden Markov models. Unlike classical approaches that prioritise full posterior recovery under a fully specified generative model, we assume access to regime-specific predictive models whose parameters are learned online while maintaining a fixed transition prior over regimes. Our objective is to sequentially identify latent regimes while maintaining accurate step-ahead predictive distributions. Because the number of possible regime paths grows exponentially, exact filtering is infeasible. We therefore formulate streaming inference as a constrained projection problem in predictive-distribution space: under a fixed hypothesis budget, we approximate the full posterior predictive by the forward-KL optimal mixture supported on $S$ paths. The solution is the renormalised top-$S$ posterior-weighted mixture, providing a principled derivation of beam search for HMMs. The resulting algorithm is fully recursive and deterministic, performing beam-style truncation with closed-form predictive updates and requiring neither EM nor sampling. Empirical comparisons against Online EM and Sequential Monte Carlo under matched computational budgets demonstrate competitive prequential performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops a predictive-first optimization framework for streaming hidden Markov models. It assumes access to regime-specific predictive models learned online while maintaining a fixed transition prior over regimes. Streaming inference is formulated as a constrained forward-KL projection problem in predictive-distribution space: under a fixed hypothesis budget S, the full posterior predictive is approximated by the forward-KL optimal mixture supported on S paths. The authors claim this projection is solved exactly by the renormalized top-S posterior-weighted mixture, yielding a recursive, deterministic beam-search algorithm with closed-form predictive updates that requires neither EM nor sampling. Matched-budget empirical comparisons to Online EM and Sequential Monte Carlo are reported to show competitive prequential performance.
Significance. If the central derivation is correct, the work supplies a principled predictive justification for beam search in HMMs, with the advantages of being fully recursive, deterministic, and free of sampling or EM. This could be useful in streaming applications where exact filtering is intractable due to exponential path growth. The closed-form updates and matched-budget empirical results are potential strengths if the experiments are robust and the projection claim holds under the stated assumptions.
major comments (2)
- [Abstract] Abstract: the assertion that 'the solution is the renormalised top-S posterior-weighted mixture' for the forward-KL projection lacks general justification and is load-bearing for the central claim. The full posterior predictive is the mixture p(y) = ∑_paths π_path ⋅ p(y|path). Minimizing KL(p||q) for q supported on S paths depends on overlaps, variances, and supports of the component predictives p(y|path); the argmax over support and weights is not guaranteed to coincide with selecting the S largest π_path and renormalizing. The manuscript must either provide the explicit derivation showing when/why this holds or qualify the claim (e.g., under disjoint supports or specific predictive families).
- [Abstract] Empirical evaluation (referenced in Abstract): the claim of 'competitive prequential performance' under matched budgets is unverifiable from the provided information. No datasets, exact metrics (e.g., log predictive density), number of runs, error bars, or exclusion criteria are described, undermining assessment of whether the results support the method's practical viability.
minor comments (2)
- The manuscript would benefit from an explicit statement of all assumptions (e.g., on the form of the regime predictives and the fixed transition prior) in a dedicated section or paragraph.
- Notation for path posteriors π_path, the projection objective, and the resulting algorithm should be introduced with clear definitions and a small illustrative example early in the text.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive feedback. We address each major comment point by point below, indicating the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that 'the solution is the renormalised top-S posterior-weighted mixture' for the forward-KL projection lacks general justification and is load-bearing for the central claim. The full posterior predictive is the mixture p(y) = ∑_paths π_path ⋅ p(y|path). Minimizing KL(p||q) for q supported on S paths depends on overlaps, variances, and supports of the component predictives p(y|path); the argmax over support and weights is not guaranteed to coincide with selecting the S largest π_path and renormalizing. The manuscript must either provide the explicit derivation showing when/why this holds or qualify the claim (e.g., under disjoint supports or specific predictive families).
Authors: We agree that the claim requires explicit justification and qualification, as the optimality of the renormalized top-S selection for the forward-KL projection does not hold unconditionally due to potential overlaps in the component predictives. We will revise the manuscript to include a dedicated derivation subsection that states the precise conditions (including disjoint supports) under which the top-S posterior-weighted mixture is exactly optimal, and otherwise present it as the natural solution under the model's fixed transition prior. The abstract will be updated to qualify the statement accordingly. revision: yes
-
Referee: [Abstract] Empirical evaluation (referenced in Abstract): the claim of 'competitive prequential performance' under matched budgets is unverifiable from the provided information. No datasets, exact metrics (e.g., log predictive density), number of runs, error bars, or exclusion criteria are described, undermining assessment of whether the results support the method's practical viability.
Authors: The abstract is kept concise by design, but the full manuscript (Section 5) specifies the datasets, prequential log predictive density metric, number of runs with error bars, and path exclusion criteria. To address the concern directly, we will expand the abstract with a brief summary of the experimental setup and quantitative indicators of the matched-budget comparisons. revision: yes
Circularity Check
No circularity: projection-to-beam derivation remains self-contained
full rationale
The paper formulates streaming HMM inference as a forward-KL projection onto an S-path mixture in predictive space and states that its solution is the renormalized top-S posterior-weighted mixture. This is presented as the outcome of the constrained optimization rather than an input that is redefined or fitted and then relabeled as a prediction. No self-citations, uniqueness theorems, or ansatzes from prior author work are invoked to justify the central step. The recursive, deterministic algorithm with closed-form updates follows directly from the stated projection without reducing to the choice of S or the fixed transition prior by construction. The derivation chain therefore contains independent content and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
free parameters (2)
- S (beam width / hypothesis budget)
- transition prior parameters
axioms (2)
- domain assumption Regime-specific predictive models are available and can be learned online
- domain assumption A fixed transition prior over regimes is maintained
Reference graph
Works this paper leans on
-
[1]
Christopher M Bishop and Nasser M Nasrabadi.Pat- tern recognition and machine learning, volume 4
URLhttps://proceedings.mlr.press/ v235/altamirano24a.html. Christopher M Bishop and Nasser M Nasrabadi.Pat- tern recognition and machine learning, volume 4. Springer, 2006. Olivier Capp´ e. Online em algorithm for hidden markov models.Journal of Computational and Graphical Statistics, 20(3):728–749, 2011. Carlos M. Carvalho, Michael S. Johannes, Hedibert ...
work page 2006
-
[2]
doi: 10.1214/10-STS325. URLhttps://doi. org/10.1214/10-STS325. Gerardo Duran-Martin, Matias Altamirano, Alex Shestopaloff, Leandro S´ anchez-Betancourt, Jeremias Knoblauch, Matt Jones, Francois-Xavier Briol, and Kevin Patrick Murphy. Outlier-robust kalman filtering through generalised Bayes. In Rus- lan Salakhutdinov, Zico Kolter, Katherine Heller, Adrian...
-
[3]
Gerardo Duran-Martin, Leandro S´ anchez-Betancourt, ´Alvaro Cartea, and Kevin Murphy
URLhttps://proceedings.mlr.press/ v235/duran-martin24a.html. Gerardo Duran-Martin, Leandro S´ anchez-Betancourt, ´Alvaro Cartea, and Kevin Murphy. Martingale pos- terior neural networks for fast sequential decision making.arXiv preprint arXiv:2506.11898, 2025a. Gerardo Duran-Martin, Leandro S´ anchez-Betancourt, Alex Shestopaloff, and Kevin Patrick Murphy...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.