Meta-Learned Basis Adaptation for Parametric Linear PDEs
Pith reviewed 2026-05-10 17:23 UTC · model grok-4.3
The pith
A meta-learned predictor adapts Gaussian basis functions across parametric linear PDEs to enable accurate one-shot least-squares solutions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
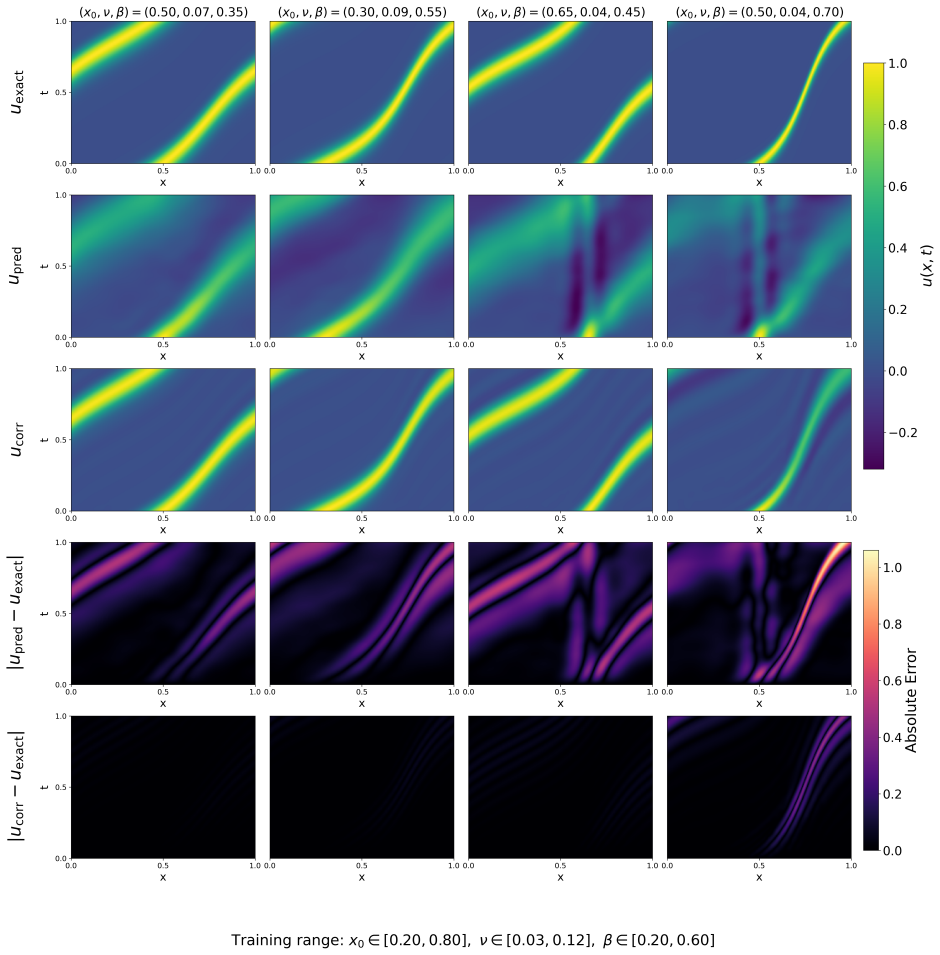
The central claim is that a shallow task-conditioned meta-learner can map PDE parameters to adaptive Gaussian basis centers, widths, and activity patterns; when these bases are transferred to a background-augmented least-squares corrector, the resulting solutions capture meaningful physics and improve accuracy by one or more orders of magnitude over baseline methods for parametric families of linear PDEs.
What carries the argument
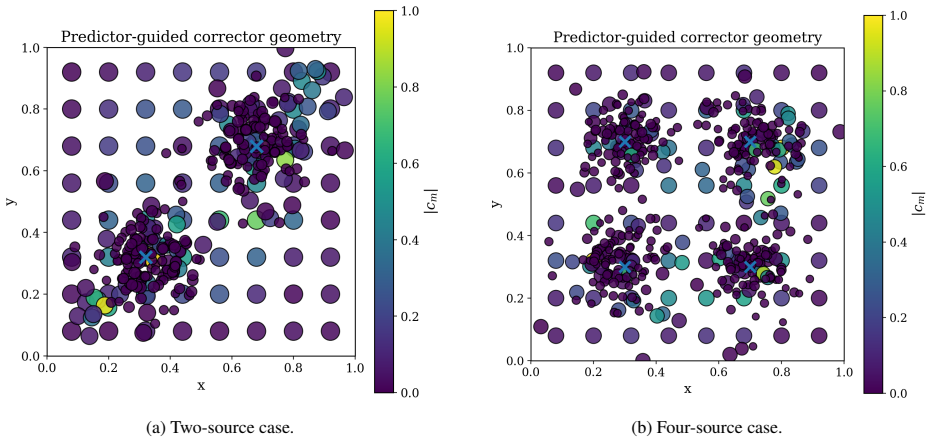
KAPI (Kernel-Adaptive Physics-Informed meta-learner), a shallow task-conditioned model that generates an interpretable, task-adaptive Gaussian basis geometry from PDE parameters via a lightweight meta-network.
If this is right
- The predictor captures meaningful physics through localized and transport-aligned basis placement.
- The corrector further improves accuracy, often by one or more orders of magnitude.
- The method outperforms parametric PINNs, physics-informed DeepONet, and uniform-grid PIELM correctors on the tested families.
- Predictor-guided basis adaptation supplies an interpretable and efficient strategy for parametric PDE solving.
Where Pith is reading between the lines
- If the meta-learner generalizes across wider parameter ranges, new PDE instances could be solved with only the cost of one least-squares step after the initial meta-training.
- The same idea of learning basis placement rules might transfer to other linear approximation schemes that currently rely on fixed grids.
- Direct visualization of the learned activity patterns could show which physical regimes the meta-network treats as distinct.
Load-bearing premise
That the meta-network successfully learns transferable, physics-aligned basis adaptations from the parametric family that meaningfully improve the subsequent one-shot least-squares corrector.
What would settle it
A test on held-out PDE parameters where replacing the meta-predicted bases with uniform or random bases produces equal or better accuracy than the full predictor-corrector pipeline.
Figures


















read the original abstract
We propose a hybrid physics-informed framework for solving families of parametric linear partial differential equations (PDEs) by combining a meta-learned predictor with a least-squares corrector. The predictor, termed \textbf{KAPI} (Kernel-Adaptive Physics-Informed meta-learner), is a shallow task-conditioned model that maps query coordinates and PDE parameters to solution values while internally generating an interpretable, task-adaptive Gaussian basis geometry. A lightweight meta-network maps PDE parameters to basis centers, widths, and activity patterns, thereby learning how the approximation space should adapt across the parametric family. This predictor-generated geometry is transferred to a second-stage corrector, which augments it with a background basis and computes the final solution through a one-shot physics-informed Extreme Learning Machine (PIELM)-style least-squares solve. We evaluate the method on four linear PDE families spanning diffusion, transport, mixed advection--diffusion, and variable-speed transport. Across these cases, the predictor captures meaningful physics through localized and transport-aligned basis placement, while the corrector further improves accuracy, often by one or more orders of magnitude. Comparisons with parametric PINNs, physics-informed DeepONet, and uniform-grid PIELM correctors highlight the value of predictor-guided basis adaptation as an interpretable and efficient strategy for parametric PDE solving.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes KAPI, a hybrid physics-informed framework for parametric linear PDEs that combines a shallow meta-learned predictor (mapping PDE parameters to adaptive Gaussian basis centers, widths, and activity patterns) with a one-shot PIELM-style least-squares corrector that augments the predictor basis with a background basis. The central claim is that the meta-network learns transferable, physics-aligned basis adaptations (localized for diffusion, transport-aligned for advection) across four PDE families, yielding interpretable geometry and accuracy gains of one or more orders of magnitude over parametric PINNs, DeepONet, and uniform-grid PIELM baselines.
Significance. If the meta-learned adaptations prove quantitatively superior and transferable, the approach could offer an efficient, interpretable alternative to full retraining of neural operators for parametric PDE families, with potential advantages in basis interpretability and reduced per-instance solve cost via the one-shot corrector. The hybrid structure and explicit basis adaptation are strengths that distinguish it from black-box meta-learning methods.
major comments (3)
- [Abstract and §4] Abstract and §4 (Experiments): The central claim of accuracy improvements 'often by one or more orders of magnitude' and 'meaningful physics' capture rests on qualitative descriptions of basis placement and visual comparisons, with no reported quantitative metrics (e.g., L2 errors with error bars, tables of exact reductions vs. baselines, or statistical significance across parameter instances). This is load-bearing for the superiority claim.
- [§3 and §4] §3 (Method) and §4: No ablation studies are described that isolate the meta-network's contribution (e.g., comparing meta-learned bases to random initialization, fixed uniform bases, or non-adaptive corrector-only variants while holding the PIELM solve fixed). Without these, it is unclear whether observed gains derive from learned physics alignment or from the hybrid corrector structure itself.
- [§3.2] §3.2 (Meta-network): The assertion that the shallow meta-network learns 'transferable, physics-aligned' adaptations (localized for diffusion, transport-aligned for advection) lacks quantitative validation such as correlation of predicted centers with solution features/fronts, overlap with analytically optimal bases, or transfer metrics across held-out parameters. This directly affects the weakest assumption in the central claim.
minor comments (2)
- [§3] Notation for the meta-network output (centers, widths, activity) should be explicitly defined with equations in §3 to avoid ambiguity when transferred to the corrector.
- [Abstract] The abstract mentions four PDE families but does not specify the exact parameter ranges or number of test instances; adding this detail would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for their insightful comments, which highlight areas where the manuscript can be strengthened with additional quantitative evidence. We provide point-by-point responses below and commit to incorporating the suggested improvements in the revised version.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): The central claim of accuracy improvements 'often by one or more orders of magnitude' and 'meaningful physics' capture rests on qualitative descriptions of basis placement and visual comparisons, with no reported quantitative metrics (e.g., L2 errors with error bars, tables of exact reductions vs. baselines, or statistical significance across parameter instances). This is load-bearing for the superiority claim.
Authors: We agree that the superiority claims would benefit from explicit quantitative support. Although Section 4 includes visual comparisons demonstrating the improvements, we did not include tabulated L2 errors with statistics. In the revision, we will add comprehensive tables reporting mean L2 errors and standard deviations over multiple parameter instances for KAPI and all baselines, along with the observed order-of-magnitude reductions. revision: yes
-
Referee: [§3 and §4] §3 (Method) and §4: No ablation studies are described that isolate the meta-network's contribution (e.g., comparing meta-learned bases to random initialization, fixed uniform bases, or non-adaptive corrector-only variants while holding the PIELM solve fixed). Without these, it is unclear whether observed gains derive from learned physics alignment or from the hybrid corrector structure itself.
Authors: The lack of ablations is a valid concern. We will include new ablation experiments in the revised Section 4. These will compare the full model against variants with fixed uniform bases, randomly sampled bases, and the corrector without the meta-predictor, all using the same PIELM least-squares solver to isolate the effect of the learned adaptive basis. revision: yes
-
Referee: [§3.2] §3.2 (Meta-network): The assertion that the shallow meta-network learns 'transferable, physics-aligned' adaptations (localized for diffusion, transport-aligned for advection) lacks quantitative validation such as correlation of predicted centers with solution features/fronts, overlap with analytically optimal bases, or transfer metrics across held-out parameters. This directly affects the weakest assumption in the central claim.
Authors: We acknowledge the need for more rigorous validation of the physics alignment. The manuscript currently supports this through qualitative visualizations in Section 4 showing basis adaptation consistent with PDE physics. For the revision, we will add quantitative analyses, including correlation coefficients between predicted basis centers and solution gradients or fronts, as well as transfer error metrics on held-out parameter values. Note that analytically optimal bases are not straightforward to define for all cases, but we will provide the suggested correlations and transfer results. revision: partial
Circularity Check
No circularity: sequential meta-predictor and independent least-squares corrector with no self-referential reduction.
full rationale
The paper defines KAPI as a shallow meta-network that outputs task-adaptive Gaussian basis parameters (centers, widths, activity) from PDE parameters and coordinates, trained via a separate loss. These parameters are then passed as fixed input to a distinct one-shot PIELM-style least-squares corrector that augments with a background basis and solves the linear system. Neither stage defines its output in terms of the other by construction, nor renames a fitted quantity as a prediction; the corrector is a standard linear solve whose accuracy gain is measured post hoc. No self-citations are invoked to establish uniqueness of the ansatz or to forbid alternatives, and the method is presented as an algorithmic pipeline rather than a closed derivation. Empirical results on four PDE families are reported separately from the construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Meta-network can map PDE parameters to interpretable, task-adaptive Gaussian basis geometry that transfers to the corrector
invented entities (1)
-
KAPI (Kernel-Adaptive Physics-Informed meta-learner)
no independent evidence
Reference graph
Works this paper leans on
- [1]
-
[2]
Characterizing possible failure modes in physics-informed neural networks
Aditi Krishnapriyan, Amir Gholami, Shandian Zhe, Robert Kirby, and Michael W Mahoney. Characterizing possible failure modes in physics-informed neural networks. In M. Ranzato, A. Beygelzimer, Y . Dauphin, P.S. Liang, and J. Wortman Vaughan, editors,Advances in Neural Information Processing Systems, volume 34, pages 26548–26560. Curran Associates, Inc., 2021
work page 2021
-
[3]
Sifan Wang, Xinling Yu, and Paris Perdikaris. When and why pinns fail to train: A neural tangent kernel perspective.Journal of Computational Physics, 449:110768, 2022
work page 2022
-
[4]
Sifan Wang, Yujun Teng, and Paris Perdikaris. Understanding and mitigating gradient flow pathologies in physics-informed neural networks.SIAM Journal on Scientific Computing, 43(5):A3055–A3081, 2021
work page 2021
-
[5]
Michael Penwarden, Shandian Zhe, Akil Narayan, and Robert M. Kirby. A metalearning approach for physics- informed neural networks (pinns): Application to parameterized pdes.Journal of Computational Physics, 477:111912, 2023
work page 2023
-
[6]
Meta-learning pinn loss functions.Journal of Computational Physics, 458:111121, 2022
Apostolos F Psaros, Kenji Kawaguchi, and George Em Karniadakis. Meta-learning pinn loss functions.Journal of Computational Physics, 458:111121, 2022
work page 2022
-
[7]
Vikas Dwivedi and Balaji Srinivasan. Physics informed extreme learning machine (pielm)–a rapid method for the numerical solution of partial differential equations.Neurocomputing, 391:96–118, 2020
work page 2020
-
[8]
Suchuan Dong and Jielin Yang. On computing the hyperparameter of extreme learning machines: Algorithm and application to computational pdes, and comparison with classical and high-order finite elements.Journal of Computational Physics, 463:111290, 2022
work page 2022
-
[9]
Francesco Calabrò, Gianluca Fabiani, and Constantinos Siettos. Extreme learning machine collocation for the numerical solution of elliptic pdes with sharp gradients.Computer Methods in Applied Mechanics and Engineering, 387:114188, 2021
work page 2021
-
[10]
Ramabathiran and Prabhu Ramachandran
Amuthan A. Ramabathiran and Prabhu Ramachandran. Spinn: Sparse, physics-based, and partially interpretable neural networks for pdes.Journal of Computational Physics, 445:110600, 2021
work page 2021
-
[11]
Curriculum learning-driven pielms for fluid flow simulations
Vikas Dwivedi, Bruno Sixou, and Monica Sigovan. Curriculum learning-driven pielms for fluid flow simulations. Neurocomputing, 650:130924, 2025
work page 2025
-
[12]
Deepxde: A deep learning library for solving differential equations.SIAM Review, 63(1):208–228, 2021
Lu Lu, Xuhui Meng, Zhiping Mao, and George Em Karniadakis. Deepxde: A deep learning library for solving differential equations.SIAM Review, 63(1):208–228, 2021
work page 2021
-
[13]
Kernel-adaptive pi-elms for forward and inverse problems in pdes with sharp gradients, 2025
Vikas Dwivedi, Balaji Srinivasan, Monica Sigovan, and Bruno Sixou. Kernel-adaptive pi-elms for forward and inverse problems in pdes with sharp gradients, 2025
work page 2025
-
[14]
Lu Lu, Pengzhan Jin, Guofei Pang, Zhongqiang Zhang, and George Em Karniadakis. Learning nonlinear operators via deeponet based on the universal approximation theorem of operators.Nature Machine Intelligence, 3(3):218–229, Mar 2021
work page 2021
-
[15]
Springer International Publishing, Cham, 2023
Somdatta Goswami, Aniruddha Bora, Yue Yu, and George Em Karniadakis.Physics-Informed Deep Neural Operator Networks, pages 219–254. Springer International Publishing, Cham, 2023
work page 2023
-
[16]
Fourier neural operator for parametric partial differential equations, 2021
Zongyi Li, Nikola Kovachki, Kamyar Azizzadenesheli, Burigede Liu, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar. Fourier neural operator for parametric partial differential equations, 2021
work page 2021
-
[17]
Vikas Dwivedi, Enrico Schiassi, Bruno Sixou, and Monica Sigovan. Gated x-tfc: Soft domain decomposition for forward and inverse problems in sharp-gradient pdes.Neurocomputing, 676:133090, 2026
work page 2026
-
[18]
Randall J LeVeque.Finite difference methods for ordinary and partial differential equations: steady-state and time-dependent problems. SIAM, 2007
work page 2007
-
[19]
Raunak Borker, Charbel Farhat, and Radek Tezaur. A high-order discontinuous galerkin method for unsteady advection–diffusion problems.Journal of Computational Physics, 332:520–537, 2017
work page 2017
-
[20]
Ethan Perez, Florian Strub, Harm de Vries, Vincent Dumoulin, and Aaron Courville. Film: Visual reasoning with a general conditioning layer.Proceedings of the AAAI Conference on Artificial Intelligence, 32(1), Apr. 2018. 22 Figure 1: Overview of the proposed predictor-corrector framework. The full KAPI predictor is a shallow task- conditioned model that ta...
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.