SRBench: A Comprehensive Benchmark for Sequential Recommendation with Large Language Models
Pith reviewed 2026-05-16 09:17 UTC · model grok-4.3
The pith
SRBench supplies a multi-dimensional benchmark that fairly compares neural and LLM-based sequential recommendation models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
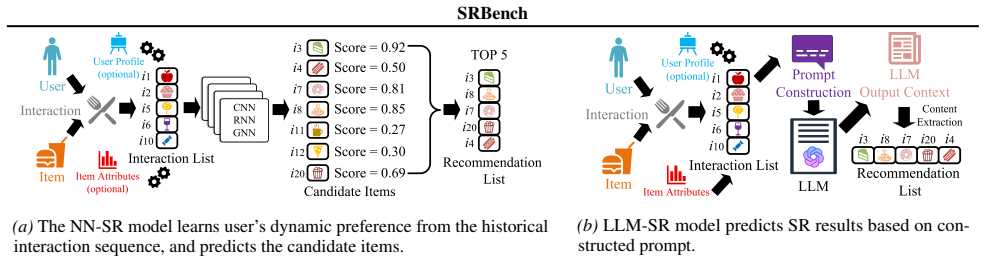
SRBench introduces three coordinated designs: a multi-dimensional evaluation covering accuracy, fairness, stability and efficiency; a unified prompt-engineering input that improves LLM-SR performance and permits head-to-head comparison with neural models; and a prompt-extractor-coupled mechanism that enforces output format via prompts and then applies a numeric-oriented extractor to retrieve answers from free-form LLM text. Evaluations of thirteen mainstream models under this regime yield observations including the tendency of LLM-SR models to over-focus on popularity while under-attending to item quality.
What carries the argument
The prompt-extractor-coupled extraction mechanism, which pairs prompt-enforced output formatting with a numeric-oriented extractor to pull task-specific answers from unstructured LLM responses.
If this is right
- Direct, apples-to-apples comparison of NN-SR and LLM-SR models becomes feasible under identical input and output conditions.
- Evaluations now include fairness, stability, and efficiency, revealing trade-offs that accuracy-only benchmarks miss.
- LLM-SR models are shown to over-weight popularity and under-weight quality, guiding targeted improvements.
- A reproducible extraction pipeline supports consistent results across different LLM back-ends and prompt styles.
Where Pith is reading between the lines
- The same prompt-plus-extractor pattern could be adapted to create comparable benchmarks for non-recommendation LLM tasks that require numeric or ranked outputs.
- If the multi-dimensional scores reorder models differently from accuracy alone, practitioners may need to re-weight metrics for specific deployment constraints.
- Extending the benchmark to additional datasets or newer LLM architectures would test whether the observed popularity bias persists.
Load-bearing premise
The unified prompt input format and prompt-extractor mechanism release LLM capability without introducing new biases or artifacts that favor one model family over another.
What would settle it
Re-running the thirteen-model comparison with an independent answer-parsing method that produces materially different rankings or fairness scores would show the extraction step distorts results.
Figures






read the original abstract
LLM development has aroused great interest in Sequential Recommendation (SR) applications. However, comprehensive evaluation of SR models remains lacking due to the limitations of the existing benchmarks: 1) an overemphasis on accuracy, ignoring other real-world demands (e.g., fairness); 2) existing datasets fail to unleash LLMs' potential, leading to unfair comparison between Neural-Network-based SR (NN-SR) models and LLM-based SR (LLM-SR) models; and 3) no reliable mechanism for extracting task-specific answers from unstructured LLM outputs. To address these limitations, we propose SRBench, a comprehensive SR benchmark with three core designs: 1) a multi-dimensional framework covering accuracy, fairness, stability and efficiency, aligned with practical demands; 2) a unified input paradigm via prompt engineering to boost LLM-SR performance and enable fair comparisons between models; 3) a novel prompt-extractor-coupled extraction mechanism, which captures answers from LLM outputs through prompt-enforced output formatting and a numeric-oriented extractor. We have used SRBench to evaluate 13 mainstream models and discovered some meaningful insights (e.g., LLM-SR models overfocus on item popularity but lack deep understanding of item quality). Concisely, SRBench enables fair and comprehensive assessments for SR models, underpinning future research and practical application.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SRBench, a benchmark for sequential recommendation (SR) models that incorporates large language models (LLMs). It identifies limitations in prior benchmarks—an overemphasis on accuracy, datasets that hinder fair LLM vs. neural-network comparisons, and unreliable extraction from LLM outputs—and addresses them via three designs: a multi-dimensional evaluation framework (accuracy, fairness, stability, efficiency), a unified prompt-engineering input paradigm, and a prompt-extractor-coupled mechanism that enforces output formatting plus a numeric-oriented extractor. The authors evaluate 13 models and report insights such as LLM-SR models overfocusing on item popularity while lacking deep item-quality understanding.
Significance. If the extraction mechanism and unified paradigm prove robust, SRBench could standardize multi-faceted SR evaluation, enabling fairer comparisons across model families and directing attention to practical concerns such as stability and fairness. This would support more reliable progress in LLM-based recommendation research and deployment.
major comments (3)
- [§3.3] §3.3 (prompt-extractor-coupled mechanism): the central fairness claim depends on reliable, unbiased extraction, yet no extraction success rates, failure analysis, or adherence statistics are reported across the 13 models; variable instruction-following could systematically favor aligned models and reintroduce the bias the benchmark aims to eliminate.
- [§4] §4 (evaluation): the reported insights (e.g., LLM-SR popularity focus) lack statistical significance tests, run-to-run variance, or prompt-sensitivity controls, undermining the claim that SRBench enables reproducible and fair assessments.
- [§3.2] §3.2 (unified input paradigm): without ablation results showing performance lift and fairness gains for both NN-SR and LLM-SR families, the assertion that prompt engineering produces unbiased comparisons remains unverified.
minor comments (2)
- [Abstract] Abstract: the phrase 'some meaningful insights' should be replaced by a concrete example to improve clarity.
- [§4] Dataset description: provide explicit statistics (size, sparsity, temporal splits) for all datasets used in §4 to allow replication.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments on SRBench. We address each major comment below and will incorporate revisions to strengthen the manuscript's claims regarding fairness, reproducibility, and the unified paradigm.
read point-by-point responses
-
Referee: [§3.3] §3.3 (prompt-extractor-coupled mechanism): the central fairness claim depends on reliable, unbiased extraction, yet no extraction success rates, failure analysis, or adherence statistics are reported across the 13 models; variable instruction-following could systematically favor aligned models and reintroduce the bias the benchmark aims to eliminate.
Authors: We agree that explicit reporting of extraction success rates, failure analysis, and adherence statistics would better substantiate the fairness claim. The prompt-extractor-coupled mechanism relies on strict prompt-enforced output formatting combined with a numeric-oriented extractor to standardize parsing across models. In the revised manuscript, we will add a dedicated analysis (new table and subsection in §3.3) reporting per-model extraction success rates, categorized failure cases (e.g., format violations vs. content errors), and adherence statistics. This will allow readers to assess whether variable instruction-following introduces systematic bias. revision: yes
-
Referee: [§4] §4 (evaluation): the reported insights (e.g., LLM-SR popularity focus) lack statistical significance tests, run-to-run variance, or prompt-sensitivity controls, undermining the claim that SRBench enables reproducible and fair assessments.
Authors: The insights were derived from the primary evaluation configuration. To improve reproducibility, the revised version will include: (i) multiple runs with different random seeds to report run-to-run variance and standard deviations for key metrics; (ii) statistical significance tests (e.g., paired t-tests) for model comparisons; and (iii) prompt-sensitivity controls by evaluating a subset of models under varied prompt phrasings. These additions will be integrated into §4 and the experimental setup. revision: yes
-
Referee: [§3.2] §3.2 (unified input paradigm): without ablation results showing performance lift and fairness gains for both NN-SR and LLM-SR families, the assertion that prompt engineering produces unbiased comparisons remains unverified.
Authors: The unified input paradigm standardizes data representation to enable direct comparison. While the main results demonstrate competitive LLM-SR performance, we acknowledge the value of explicit ablations. In the revision, we will add ablation studies in §3.2 (and cross-referenced in §4) that evaluate both NN-SR and LLM-SR families with and without the prompt-engineering components, quantifying lifts in accuracy, fairness, stability, and efficiency metrics to verify the gains and fairness benefits. revision: yes
Circularity Check
No circularity in benchmark proposal
full rationale
The paper introduces SRBench as an empirical benchmark with three design elements (multi-dimensional metrics, unified prompt paradigm, and prompt-extractor mechanism) and reports evaluations of 13 existing models. No mathematical derivations, first-principles predictions, fitted parameters repurposed as outputs, or self-referential uniqueness theorems appear in the provided text. Claims rest on the new benchmark's construction and observed empirical results rather than any reduction of outputs to inputs by definition or self-citation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Existing benchmarks overemphasize accuracy, use datasets that disadvantage LLMs, and lack reliable extraction from unstructured outputs
invented entities (1)
-
prompt-extractor-coupled extraction mechanism
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
unified prompt-enhanced input paradigm... prompt-extractor-coupled extraction mechanism
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
multi-dimensional framework covering accuracy, fairness, stability and efficiency
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
URL https://api.semanticscholar. org/CorpusID:277542146. Bao, K., Zhang, J., Zhang, Y ., Wang, W., Feng, F., and He, X. Tallrec: An effective and efficient tuning frame- work to align large language model with recommenda- tion. In Proceedings of the 17th ACM conference on recommender systems, pp. 1007–1014, 2023. Chang, J., Gao, C., Zheng, Y ., Hui, Y ., ...
-
[2]
LoRA: Low-Rank Adaptation of Large Language Models
URL https://api.semanticscholar. org/CorpusID:3424871. Harper, F. M. and Konstan, J. A. The movielens datasets: History and context. Acm transactions on interactive intelligent systems (tiis), 5(4):1–19, 2015. He, X., Liao, L., Zhang, H., Nie, L., Hu, X., and Chua, T.-S. Neural collaborative filtering. In Proceedings of the 26th international conference o...
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[3]
URL https://api.semanticscholar. org/CorpusID:7644747. Jayaseelan, N. Llama 2: The new open source language model. Journal of Machine Learning Research, 24(1): 1–15, 2023. Jendal, T., Corfixen, M., Olesen, M., Dolog, P., Hose, K., Dell’Aglio, D., and Lissandrini, M. The yelp collabora- tive knowledge graph. In Proceedings of the 34th ACM International Con...
work page 2023
-
[4]
arXiv preprint arXiv:2304.10149 , year=
URL https://api.semanticscholar. org/CorpusID:277781085. Kusano, G., Akimoto, K., and Takeoka, K. Revisiting prompt engineering: A comprehensive evaluation for llm-based personalized recommendation. In Proceedings of the Nineteenth ACM Conference on Recommender Systems, pp. 832–841, 2025. Lee, G., Kim, K., and Shin, K. Revisiting lightgcn: Unex- pected in...
-
[5]
Llm-rec: Personalized recommendation via prompting large language models
URL https://api.semanticscholar. org/CorpusID:269741092. Lyu, H., Jiang, S., Zeng, H., Xia, Y ., Wang, Q., Zhang, S., Chen, R., Leung, C., Tang, J., and Luo, J. Llm-rec: Per- sonalized recommendation via prompting large language models. arXiv preprint arXiv:2307.15780, 2023. Ma, T., Cheng, Y ., Zhu, H., and Xiong, H. Large lan- guage models are not stable...
-
[6]
URL https://api.semanticscholar. org/CorpusID:44104089. Silva, ´I., Marinho, L., Said, A., and Willemsen, M. C. Leveraging chatgpt for automated human-centered ex- planations in recommender systems. In Proceedings of the 29th International Conference on Intelligent User Interfaces, pp. 597–608, 2024. Tang, J. and Wang, K. Personalized top-n sequential rec...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.