Spoiler Alert: Narrative Forecasting as a Metric for Tension in LLM Storytelling
Pith reviewed 2026-05-10 16:46 UTC · model grok-4.3
The pith
The 100-Endings metric uses LLM ending prediction mismatches to measure and improve narrative tension.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The 100-Endings metric walks a story sentence by sentence; at each point an LLM predicts the ending 100 times from the text so far, and tension is the rate of mismatches with the ground truth ending. The resulting curve also yields an inflection rate that counts direction reversals as a proxy for twists. Unlike rubric-based judges, this metric ranks New Yorker stories above LLM-generated ones. A generation pipeline using story templates, idea formulation, and narrative scaffolding raises the tension score without harming EQ-Bench performance.
What carries the argument
The 100-Endings metric: at each sentence, run 100 ending predictions from the prefix and count mismatches with the true ending.
If this is right
- The metric distinguishes high-tension literary stories from typical LLM outputs where rubrics do not.
- Incorporating structural constraints during generation increases measured tension.
- The sentence-level mismatch curve provides additional measures like inflection rate for analyzing narrative structure.
- Improvements in tension can be achieved without sacrificing performance on existing creative writing benchmarks.
Where Pith is reading between the lines
- Using the same model family for prediction and generation may introduce bias into the tension scores.
- The forecasting method could extend to measuring unpredictability in other narrative forms such as scripts or interactive stories.
- Correlating the metric with direct human judgments of suspense would test its validity as a tension proxy.
Load-bearing premise
That the rate of ending-prediction mismatches by an LLM predictor faithfully captures the narratological concept of tension, rather than reflecting predictor biases or surface-level features.
What would settle it
Run a reader study where participants rate the tension or suspense in matched stories and compare those ratings to the 100-Endings scores; absence of positive correlation would falsify the metric's claim.
Figures









read the original abstract
LLMs have so far failed both to generate consistently compelling stories and to recognize this failure--on the leading creative-writing benchmark (EQ-Bench), LLM judges rank zero-shot AI stories above New Yorker short stories, a gold standard for literary fiction. We argue that existing rubrics overlook a key dimension of compelling human stories: narrative tension. We introduce the 100-Endings metric, which walks through a story sentence by sentence: at each position, a model predicts how the story will end 100 times given only the text so far, and we measure tension as how often predictions fail to match the ground truth. Beyond the mismatch rate, the sentence-level curve yields complementary statistics, such as inflection rate, a geometric measure of how frequently the curve reverses direction, tracking twists and revelations. Unlike rubric-based judges, 100-Endings correctly ranks New Yorker stories far above LLM outputs. Grounded in narratological principles, we design a story-generation pipeline using structural constraints, including analysis of story templates, idea formulation, and narrative scaffolding. Our pipeline significantly increases narrative tension as measured by the 100-Endings metric, while maintaining performance on the EQ-Bench leaderboard.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the 100-Endings metric, which quantifies narrative tension by sampling 100 ending predictions from an LLM at each sentence of a story and measuring the mismatch rate with the ground-truth continuation; it also derives complementary statistics such as inflection rate. The authors argue that this metric, unlike rubric-based judges on EQ-Bench, correctly ranks New Yorker short stories above zero-shot LLM outputs. They further present a story-generation pipeline incorporating template analysis, idea formulation, and narrative scaffolding that raises 100-Endings tension scores while preserving EQ-Bench performance.
Significance. If the 100-Endings mismatch rate isolates structural suspense rather than predictor alignment, the metric offers a falsifiable, sentence-level alternative to subjective rubrics for creative-writing evaluation and could guide more effective LLM story generation. The pipeline's ability to improve the new metric without EQ-Bench regression is a practical strength, and the provision of inflection-rate statistics adds analytical depth. The work is grounded in narratological ideas but its impact hinges on rigorous validation against human tension judgments and controls for distributional confounds.
major comments (2)
- [Abstract and §3] Abstract and §3 (metric definition): the central claim that mismatch rate 'faithfully captures' narratological tension is load-bearing yet rests on the untested assumption that predictor failures are driven by suspense structure rather than training-distribution overlap. Because the 100-Endings predictor and the story generator are both LLMs, pipeline outputs may simply be more in-distribution, producing lower mismatch rates (apparently higher tension) even without structural change; an ablation with a held-out predictor family or correlation against human suspense ratings is required to support the ranking result.
- [§5] §5 (experiments): the reported ranking advantage of New Yorker stories and the pipeline's tension gains lack reported statistical tests, confidence intervals, or controls for story length, lexical diversity, and genre. Without these, it is unclear whether the 100-Endings advantage is robust or an artifact of surface features that also affect EQ-Bench.
minor comments (2)
- [§3] The sentence-level curve and inflection-rate definition would benefit from an explicit equation or pseudocode in §3 to allow exact reproduction.
- [§3] Clarify the exact LLM used for the 100-Endings predictor (model name, temperature, prompt template) so that the metric can be re-implemented without ambiguity.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which highlights key areas for strengthening the validation and statistical presentation of the 100-Endings metric. We address each major comment below and will incorporate revisions to improve rigor without altering the core claims.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (metric definition): the central claim that mismatch rate 'faithfully captures' narratological tension is load-bearing yet rests on the untested assumption that predictor failures are driven by suspense structure rather than training-distribution overlap. Because the 100-Endings predictor and the story generator are both LLMs, pipeline outputs may simply be more in-distribution, producing lower mismatch rates (apparently higher tension) even without structural change; an ablation with a held-out predictor family or correlation against human suspense ratings is required to support the ranking result.
Authors: We acknowledge that the metric's interpretation assumes mismatches primarily reflect structural suspense rather than distributional overlap between the predictor and generated text. The consistent outperformance of New Yorker stories over zero-shot LLM outputs across experiments provides supporting evidence aligned with narratological expectations, but we agree this does not fully isolate the cause. In the revised manuscript, we will add a new analysis correlating 100-Endings scores with human-annotated tension ratings on a held-out sample of 20 stories (balanced between human and LLM sources). This directly tests alignment with perceived suspense. A full ablation using a disjoint model family is computationally intensive and beyond the current scope, but we will explicitly discuss the limitation of shared model families and its implications for future work. revision: partial
-
Referee: [§5] §5 (experiments): the reported ranking advantage of New Yorker stories and the pipeline's tension gains lack reported statistical tests, confidence intervals, or controls for story length, lexical diversity, and genre. Without these, it is unclear whether the 100-Endings advantage is robust or an artifact of surface features that also affect EQ-Bench.
Authors: We agree that additional statistical controls and reporting are necessary to establish robustness. The revised manuscript will include bootstrap-derived 95% confidence intervals for all reported mean 100-Endings mismatch rates and inflection rates. We will also add linear regression models that control for story length (sentence count) and lexical diversity (type-token ratio), testing whether group differences remain significant after these covariates. Genre is held constant as all stories are short fiction, which we will state explicitly along with a discussion of potential remaining confounds. These additions will clarify that the observed advantages are not reducible to the listed surface features. revision: yes
Circularity Check
100-Endings metric defined from observable mismatches; no reduction to inputs by construction
full rationale
The 100-Endings metric is introduced directly as the rate at which an LLM predictor's 100 sampled endings fail to match the ground-truth continuation, yielding an observable mismatch frequency and inflection statistics. This construction does not reduce to fitted parameters, self-referential quantities, or author-specific ansatzes; the ranking of New Yorker stories above LLM outputs and the pipeline's reported tension increase are presented as empirical results measured against this independent definition. No load-bearing self-citations, uniqueness theorems, or renamings of known results appear in the derivation chain. The central claims remain self-contained against external benchmarks such as EQ-Bench, consistent with a minor or absent circularity finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Narrative tension is captured by the frequency with which an LLM fails to predict the actual story ending from preceding text.
invented entities (1)
-
100-Endings metric
no independent evidence
Reference graph
Works this paper leans on
-
[1]
doi: 10.48550/arxiv.2312.06281. Samuel J Paech. Eq-bench creative writing benchmark v3. https://github.com/EQ-bench/ creative-writing-bench, 2025. Arjun Panickssery, Samuel R. Bowman, and Shi Feng. LLM evaluators recognize and favor their own generations.arXiv preprint, 2024. Chau Minh Pham, Jenna Russell, Dzung Pham, and Mohit Iyyer. Frankentext: Stitchi...
-
[2]
doi: 10.18653/v1/2025.acl-long.1577
Association for Computational Linguistics. doi: 10.18653/v1/2025.acl-long.1577. URL https://aclanthology.org/2025.acl-long.1577/. Yufei Tian, Bodhisattwa Prasad Majumder, and Yulia Tsvetkov. Are large language models capable of generating human-level narratives? InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, 2024...
-
[3]
Association for Computational Linguistics. doi: 10.18653/v1/2024.naacl-long.95. URL https://aclanthology.org/2024.naacl-long.95/. Lei Wang, Jianxun Lian, Yi Huang, Yanqi Dai, Haoxuan Li, Xu Chen, Xing Xie, and Ji-Rong Wen. CharacterBox: Evaluating the role-playing capabilities of LLMs in text-based virtual worlds. In Proceedings of the 2025 Annual Confere...
-
[4]
, ˆe(i) 100 conditioned on the prefix (s1,
Predict100 independent ending predictions ˆe(i) 1 , . . . , ˆe(i) 100 conditioned on the prefix (s1, . . . ,s i), using a generation modelG
-
[5]
Judgeeach prediction against the true remainder (si+1, . . . ,s N) using a judge model J , which returns a binary verdict j(i) k ∈ {0, 1} indicating whether ˆe(i) k captures the “general direction” of the true continuation. 3.Aggregateinto a position-levelno-rate: no-rate(i) =1− 1 100 100 ∑ k=1 j(i) k (4) 17 Preprint. Under review. A no-rate of 0.85 means...
-
[6]
Minimum context: Position i is skipped if the preceding sentence si−1 contains fewer than 10 words (MIN_SENT_WORDS = 10). This excludes positions following very short sentences (e.g., single-line dialogue tags) that provide minimal narrative context
-
[7]
predictable because all readers would agree
Token percentage window: We compute the fraction of story tokens revealed at each position using the tokenizer of the generation model. Only positions where 10%–99% of tokens have been revealed are retained. The lower bound excludes positions with insufficient context; the upper bound excludes trivial positions near the final sentence. Stories exceeding 5...
-
[8]
Mean no-rate.The primary metric. At each position i, the no-rate is the fraction of 100 predictions the judge rejects: no-rate(i) =1− 1 100 100 ∑ k=1 j(i) k (6) The story-level mean no-rate averages across all retained positions: no-rate= 1 |P | ∑ i∈P no-rate(i),P={i: 10%≤pct(i)≤99%}(7)
-
[9]
Late-stage no-rate.The mean no-rate restricted to positions where ≥80% of the story has been revealed. This measures whether the story remains unpredictable as it approaches its ending, or whether the conclusion becomes obvious once most of the narrative has been read
-
[10]
The story-level metric is the mean of these drops across all peaks
Post-spike convergence.For each local peak in the no-rate curve (a position where no-rate exceeds both neighbors), we compute the percentage drop from the peak to the minimum within the next 10 positions. The story-level metric is the mean of these drops across all peaks. More negative values indicate that tension peaks resolve more sharply—the story answ...
-
[11]
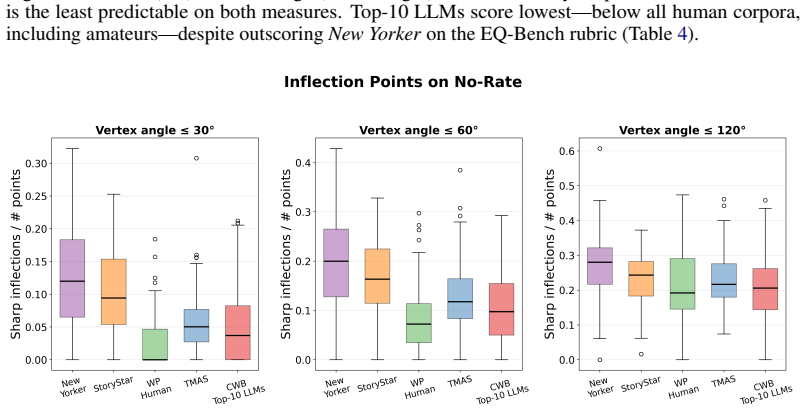
Inflection rate.The fraction of positions at which the smoothed no-rate curve sharply reverses direction, as described in Section 3. Before computing vertex angles, both axes are rescaled to [0, 1] (using each story’s own range) to fix a 1:1 aspect ratio. We report at three thresholds: α∈ {30, 60, 120}. Group-level reporting.For a group of n stories, we r...
-
[12]
Step 0 — Warmup: Extract a structural beat sheet from a reference story (either a famous title or a full New Yorker story text). 22 Preprint. Under review
-
[13]
When warmup is absent, generates beats from scratch
Step 1 — Beat Adaptation: Adapt the warmup beat sheet to the target story idea. When warmup is absent, generates beats from scratch
-
[14]
Step 2 — Story Writing: Write the final story from the adapted beats, or directly from the idea in vanilla mode. All API calls use the OpenRouter endpoint. Reasoning/thinking is disabled for all calls. Stories shorter than 200 characters are automatically discarded and regenerated. D.2 Shared Hyperparameters Table 8 lists the hyperparameters shared across...
work page 2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.