Normalized Likelihood Criteria for Model Selection in the Stochastic Block Model
Pith reviewed 2026-05-10 15:43 UTC · model grok-4.3
The pith
Normalized maximum complete likelihood and decomposed normalized maximum likelihood estimators are strongly consistent for selecting the number of communities in sparse stochastic block models when average node degree diverges.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
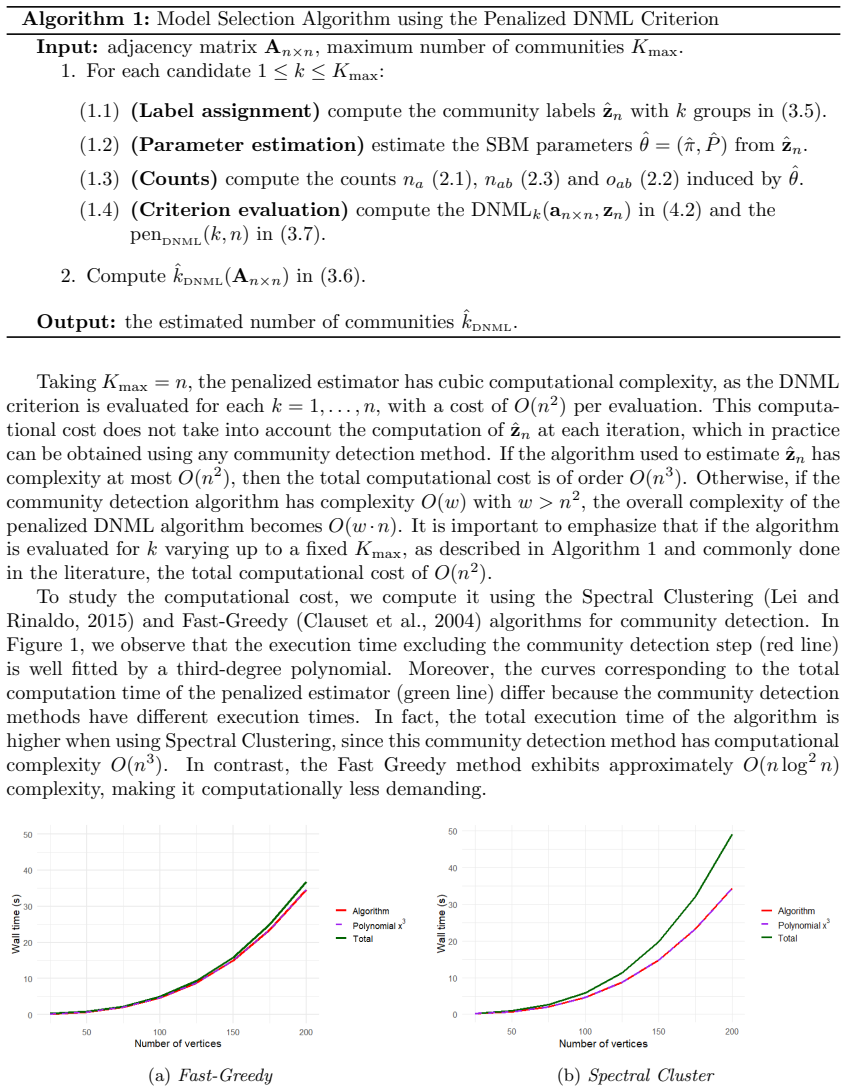
A penalized estimator derived from the Normalized Maximum Likelihood is strongly consistent with a logarithmic penalty term, although its computation is intractable. The Normalized Maximum Complete Likelihood and the Decomposed Normalized Maximum Likelihood admit explicit formulations, with the DNML having cubic computational complexity in the number of nodes. The NMCL- and DNML-based estimators are strongly consistent for sparse networks in which the average node degree diverges with the network size.
What carries the argument
The Normalized Maximum Complete Likelihood (NMCL) and Decomposed Normalized Maximum Likelihood (DNML) criteria, which serve as penalized likelihood functions for selecting the number of communities under the stochastic block model.
If this is right
- The DNML estimator provides a computationally feasible method with cubic complexity that recovers the true number of communities under the stated sparsity condition.
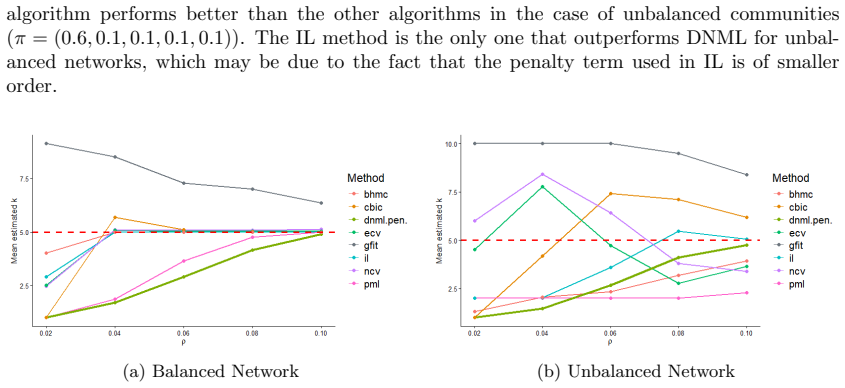
- Both estimators perform competitively with existing methods, especially when community sizes are unbalanced.
- Strong consistency guarantees apply in the asymptotic regime of growing network size and diverging average degree.
- These criteria extend the use of normalized likelihood penalties to the stochastic block model setting for model selection.
Where Pith is reading between the lines
- The cubic complexity of DNML may limit application to extremely large networks, suggesting room for faster approximations that preserve consistency.
- Real-world networks often violate the exact SBM assumption or the degree-divergence condition, so empirical performance may degrade outside the theoretical regime.
- Similar normalized-likelihood penalties could be adapted to other latent-block or community models if their likelihood structures allow analogous decomposition.
Load-bearing premise
The observed network is generated exactly according to a stochastic block model in which the average node degree diverges to infinity with the number of nodes.
What would settle it
Simulate networks from a stochastic block model with fixed average degree that does not grow and verify whether the NMCL or DNML estimator selects an incorrect number of communities with probability bounded away from zero as the network size tends to infinity.
Figures



read the original abstract
Estimating the number of communities is a fundamental problem in network analysis under the stochastic block model (SBM). In this paper, we study penalized estimators for this task based on normalized likelihood criteria. We show that a penalized estimator derived from the Normalized Maximum Likelihood (NML) is strongly consistent with a logarithmic penalty term, although its computation is intractable. To overcome this limitation, we consider the Normalized Maximum Complete Likelihood (NMCL) and the Decomposed Normalized Maximum Likelihood (DNML). The DNML admits an explicit formulation with cubic computational complexity in the number of nodes. We prove that the NMCL- and DNML- based estimators are strongly consistent for sparse networks in which the average node degree diverges with the network size. Empirical results show that the DNML estimator performs competitively with existing methods, particularly in unbalanced networks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops penalized estimators for the number of communities under the stochastic block model using normalized likelihood criteria. It establishes that an NML-based estimator is strongly consistent with a logarithmic penalty (though intractable to compute), then introduces the NMCL and DNML criteria. The DNML admits an explicit closed-form expression with cubic complexity in the number of nodes. The central theoretical result is a proof that both the NMCL- and DNML-based estimators are strongly consistent for sparse SBM networks in which the average node degree diverges to infinity with network size. Numerical experiments indicate that the DNML estimator performs competitively with existing methods, with particular strength in unbalanced community-size regimes.
Significance. If the consistency proofs are correct, the work supplies rigorous asymptotic justification for normalized-likelihood penalties in a sparsity regime that is both theoretically interesting and practically relevant. The explicit, O(n^3) DNML formula is a concrete algorithmic contribution that removes the intractability barrier of full NML while preserving the consistency property. Credit is due for the precise statement of the divergence condition on average degree and for the empirical focus on unbalanced networks, where many competing criteria degrade.
minor comments (4)
- Abstract: the phrase 'cubic computational complexity in the number of nodes' should be clarified to indicate whether the cubic term is strictly O(n^3) or also depends on the maximum number of communities K_max under consideration.
- Section 4 (simulation protocol): the description of the unbalanced-network experiments should report the number of Monte Carlo replications and include standard errors or box-plots for the estimated number of communities, so that variability can be assessed.
- Section 2 (related work): the literature review on penalized likelihood criteria for SBM would benefit from explicit comparison of the logarithmic penalty derived here with the penalties appearing in the BIC-type criteria of Wang & Bickel (2017) and the ICL criterion of Daudin et al. (2008).
- Notation: the distinction between the normalized maximum complete likelihood (NMCL) and the decomposed normalized maximum likelihood (DNML) is introduced without a compact display equation showing how the DNML decomposition differs from the NMCL; adding such an equation would improve readability.
Simulated Author's Rebuttal
We thank the referee for their careful reading of the manuscript and for the positive assessment, including recognition of the consistency results in the sparse regime where average degree diverges and the computational tractability of the DNML criterion. We appreciate the recommendation for minor revision.
Circularity Check
No significant circularity
full rationale
The paper's core contribution consists of asymptotic consistency proofs for NMCL- and DNML-based estimators under the stochastic block model when average node degree diverges to infinity. These are mathematical derivations establishing strong consistency in a specified regime, not data-driven fits, parameter estimations renamed as predictions, or self-referential definitions. The abstract and described claims contain no load-bearing steps that reduce by construction to the paper's own inputs or unverified self-citations; the results are conditional on explicit SBM assumptions and are presented as independent theoretical results.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Data generated exactly from a stochastic block model
- domain assumption Average node degree diverges with network size
Reference graph
Works this paper leans on
-
[1]
(2024) once again to obtain that kY a=1 na n na Γ(na + 1
Using the fact thatn 1 +n 2 +· · ·+n k =n, we apply Lemma 5.1 in Cerqueira et al. (2024) once again to obtain that kY a=1 na n na Γ(na + 1
work page 2024
-
[2]
≤ 1 Γ( 1 2)k−1Γ(n+ 1
-
[3]
Thus, we conclude that supπ∈Πk Pπ(zn) Qk(zn) ≤ Γ( 1 2)Γ(n+ k 2 ) Γ( k 2 )Γ(n+ 1
-
[4]
(A.12) By (A.7), we obtain that log Γ( 1 2)Γ(n+ k 2 ) Γ( k 2 )Γ(n+ 1 2) ! ≤ k−1 2 logn+c ′′ k,(A.13) wherec ′′ k is a constant depending only onk. Combining (A.12) and (A.13) we have, for all zn ∈[k] n, that log supπ∈Πk Pπ(zn) Qk(zn) ≤ k−1 2 logn+c ′′ k (A.14) Using the fact that Q k(zn) is a distribution overz n ∈[k] n, we have that Cz DNML(n, k) = X en ...
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.