VeriSim: A Configurable Framework for Evaluating Medical AI Under Realistic Patient Noise
Pith reviewed 2026-05-10 16:22 UTC · model grok-4.3
The pith
Medical LLMs lose 15-25% diagnostic accuracy when patient responses include realistic noise like memory gaps and anxiety.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
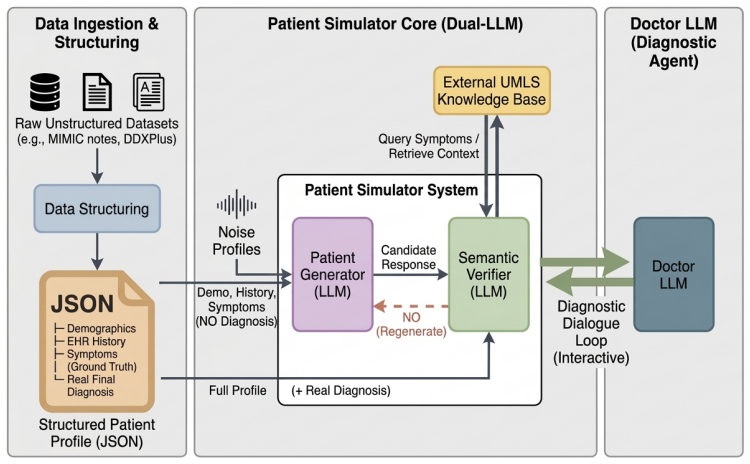
VeriSim is a truth-preserving patient simulation framework that injects controllable, clinically evidence-grounded noise into patient responses while maintaining strict adherence to medical ground truth through a hybrid UMLS-LLM verification mechanism. It operationalizes six noise dimensions derived from peer-reviewed medical communication literature, capturing authentic clinical phenomena such as patient recall limitations, health literacy barriers, and stigma-driven non-disclosure. Experiments across seven open-weight LLMs reveal that all models degrade significantly under realistic patient noise, with diagnostic accuracy dropping 15-25% and conversation length increasing 34-55%.
What carries the argument
The VeriSim framework, which uses six noise dimensions from medical communication literature combined with hybrid UMLS-LLM verification to add realistic patient noise while preserving ground truth.
If this is right
- Diagnostic accuracy of all tested LLMs drops 15-25% when patient noise is added.
- Conversation length grows 34-55% under the same conditions.
- 7B-parameter models degrade about 40% more than 70B+ models.
- Medical fine-tuning on standard data gives only limited protection against communication noise.
- Clinicians rate the simulations as high quality with inter-annotator kappa above 0.80.
Where Pith is reading between the lines
- Current benchmark tests for medical AI may overestimate real-world performance because they lack this form of patient noise.
- Training methods that explicitly include simulated communication barriers could close part of the observed performance gap.
- The open-source release of the framework allows direct comparison of new models or fine-tuning approaches against the same noise conditions.
Load-bearing premise
The six noise dimensions drawn from medical literature plus the hybrid verification step capture real patient communication without creating new distortions.
What would settle it
Running the same LLMs on transcripts from actual doctor-patient visits and measuring whether diagnostic accuracy drops by 15-25% and conversation length rises by 34-55%, matching the simulated results.
Figures

read the original abstract
Medical large language models (LLMs) achieve impressive performance on standardized benchmarks, yet these evaluations fail to capture the complexity of real clinical encounters where patients exhibit memory gaps, limited health literacy, anxiety, and other communication barriers. We introduce VeriSim, a truth-preserving patient simulation framework that injects controllable, clinically evidence-grounded noise into patient responses while maintaining strict adherence to medical ground truth through a hybrid UMLS-LLM verification mechanism. Our framework operationalizes six noise dimensions derived from peer-reviewed medical communication literature, capturing authentic clinical phenomena such as patient recall limitations, health literacy barriers, and stigma-driven non-disclosure. Experiments across seven open-weight LLMs reveal that all models degrade significantly under realistic patient noise, with diagnostic accuracy dropping 15-25% and conversation length increasing 34-55%. Notably, smaller models (7B) show 40% greater degradation than larger models (70B+), while medical fine-tuning on standard corpora provides limited robustness benefits against patient communication noise. Evaluation by board-certified clinicians demonstrates high-quality simulation with strong inter-annotator agreement (kappa > 0.80), while LLM-as-a-Judge serves as a validated auxiliary evaluator achieving comparable reliability for scalable assessment. Our results highlight a critical Sim-to-Real gap in current medical AI. We release VeriSim as an open-source noise-injection framework, establishing a rigorous testbed for evaluating clinical robustness.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces VeriSim, a configurable framework for truth-preserving patient simulation in medical AI evaluation. It derives six noise dimensions from peer-reviewed medical communication literature (e.g., recall limitations, health literacy barriers, stigma-driven non-disclosure), injects them controllably into patient responses, and enforces ground-truth adherence via a hybrid UMLS-LLM verification mechanism. Experiments on seven open-weight LLMs demonstrate significant degradation: diagnostic accuracy drops 15-25% and conversation length increases 34-55% under noise, with 7B models showing 40% greater degradation than 70B+ models; medical fine-tuning offers limited robustness. Board-certified clinician evaluation yields kappa > 0.80, and LLM-as-a-Judge is positioned as a scalable auxiliary metric. The work is released open-source to address the Sim-to-Real gap in medical AI benchmarks.
Significance. If the simulation accurately captures real patient communication behaviors without introducing artifacts, the results would be significant for the field by establishing a rigorous, reproducible testbed that exposes robustness limitations in current medical LLMs beyond standardized benchmarks. The quantitative findings on model-size-dependent degradation, combined with clinician validation and open-source release, could drive more realistic evaluation practices and improvements in clinical AI systems.
major comments (3)
- [Methods (Noise Injection and Verification)] The operationalization of the six noise dimensions and the hybrid UMLS-LLM verification (including prompt construction for noise injection, exact multi-turn consistency rules, and handling of cumulative effects) lacks sufficient detail to confirm that ground truth is strictly preserved and that no simulation artifacts drive the reported 15-25% accuracy drops (Methods section on framework design and verification).
- [Results] The central empirical claims of 15-25% diagnostic accuracy drops and 34-55% conversation length increases across seven LLMs are presented without statistical tests, confidence intervals, error bars, or details on post-hoc analysis choices, undermining assessment of whether the degradation is robust or model-specific (Results section).
- [Evaluation] Clinician validation reports kappa > 0.80 but is described as a single post-generation rating; it does not include per-noise-dimension tests for ground-truth preservation or checks against real clinical encounter data, leaving the truth-preserving claim insufficiently supported for the load-bearing simulation (Evaluation section).
minor comments (2)
- [Abstract and Evaluation] The abstract and text refer to 'LLM-as-a-Judge' as validated but do not report the specific agreement metrics, prompt templates, or comparison protocol with clinician ratings.
- [Experiments] Specific model identifiers, versions, and exact prompting templates for the seven open-weight LLMs should be listed in a table or appendix for full reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which have helped us identify areas for improvement in clarity and rigor. We address each major comment below and outline the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Methods (Noise Injection and Verification)] The operationalization of the six noise dimensions and the hybrid UMLS-LLM verification (including prompt construction for noise injection, exact multi-turn consistency rules, and handling of cumulative effects) lacks sufficient detail to confirm that ground truth is strictly preserved and that no simulation artifacts drive the reported 15-25% accuracy drops (Methods section on framework design and verification).
Authors: We agree that additional methodological transparency is warranted. In the revised manuscript, we will expand the Methods section with explicit prompt templates for each noise dimension, the precise multi-turn consistency rules enforced by the hybrid verifier, and a step-by-step description of how cumulative noise effects are applied while preserving ground-truth medical facts via UMLS entity linking and LLM consistency checks. We will also include pseudocode illustrating the verification pipeline to demonstrate that no simulation artifacts are introduced. revision: yes
-
Referee: [Results] The central empirical claims of 15-25% diagnostic accuracy drops and 34-55% conversation length increases across seven LLMs are presented without statistical tests, confidence intervals, error bars, or details on post-hoc analysis choices, undermining assessment of whether the degradation is robust or model-specific (Results section).
Authors: We concur that statistical support is essential for interpreting the magnitude and reliability of the observed effects. We will revise the Results section to report paired statistical tests (e.g., Wilcoxon signed-rank tests with Bonferroni correction), 95% confidence intervals for all accuracy and length metrics, error bars on figures, and a clear description of the post-hoc analysis pipeline. These additions will allow readers to evaluate whether the 15-25% and 34-55% degradations are statistically robust and model-size dependent. revision: yes
-
Referee: [Evaluation] Clinician validation reports kappa > 0.80 but is described as a single post-generation rating; it does not include per-noise-dimension tests for ground-truth preservation or checks against real clinical encounter data, leaving the truth-preserving claim insufficiently supported for the load-bearing simulation (Evaluation section).
Authors: We will strengthen the Evaluation section by reporting per-noise-dimension inter-annotator agreement (Fleiss' kappa) from the clinician reviews to confirm consistency across the six noise types. However, direct empirical checks against real clinical encounter data are not feasible within this study due to privacy regulations and the absence of matched real-world transcripts; our design instead relies on literature-derived noise dimensions validated through clinician review of simulated outputs. revision: partial
- Direct empirical validation of the simulated patient behaviors against real clinical encounter data, which would require access to protected health information and is outside the ethical and practical scope of the current work.
Circularity Check
No circularity: empirical results from external models and literature-derived dimensions
full rationale
The paper's core contribution is an empirical testbed: six noise dimensions are taken directly from external peer-reviewed medical communication literature, implemented via a hybrid UMLS-LLM verifier whose rules are stated as operational (not fitted or self-defined), and then applied to seven independent open-weight LLMs. Diagnostic accuracy drops, conversation-length increases, and clinician kappa scores are measured outcomes, not quantities that reduce to the framework's own inputs by construction. No equations, fitted parameters renamed as predictions, self-citation chains, or uniqueness theorems appear in the derivation. The simulation is therefore self-contained against external benchmarks and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Six noise dimensions from peer-reviewed medical communication literature accurately represent real patient barriers such as recall limitations and stigma-driven non-disclosure.
- domain assumption Hybrid UMLS-LLM verification mechanism preserves strict adherence to medical ground truth during noise injection.
Reference graph
Works this paper leans on
-
[1]
Alistair Johnson, Lucas Bulgarelli, Tom Pollard, Leo Anthony Celi, Roger Mark, and Steven Horng
Association for Computational Linguistics. Alistair Johnson, Lucas Bulgarelli, Tom Pollard, Leo Anthony Celi, Roger Mark, and Steven Horng. 2023a. MIMIC-IV-ED (version 2.2). Alistair EW Johnson, Lucas Bulgarelli, Lu Shen, Alvin Gayles, Ayad Shammout, Steven Horng, Tom J Pol- lard, Sicheng Hao, Benjamin Moody, Brian Gow, et al. 2023b. MIMIC-IV, a freely ac...
work page 2020
-
[2]
Biomistral: A collection of open-source pretrained large language models for medical domains
Substance use related stigma: What we know and the way forward.Journal of Addictive Behaviors, Therapy & Rehabilitation, 2(2):782. Mark Kutner, Elizabeth Greenberg, Ying Jin, and Chris- tine Paulsen. 2006. The health literacy of America’s adults: Results from the 2003 National Assessment of Adult Literacy. Technical Report NCES 2006-483, National Center f...
-
[3]
Stay in character:Respond naturally as a real pa- tient would
-
[4]
Answer only specific questions asked
Information Asymmetry:Do not volunteer symp- toms unprompted. Answer only specific questions asked
-
[5]
Consistency:Maintain history consistency through- out the conversation
-
[6]
No ”AI” Language:Never reference being an AI, the simulation, or the noise profile. [TASK]Generate the patient’s next response based on the conversation history. Keep it under 50 words. Figure A1: Patient Generator Prompt Template B Noise Parameter Mappings This appendix provides detailed parameter map- pings for each of the six noise pillars. For each pi...
-
[7]
2.Act: • If you have sufficient information, provide yourFINAL DIAGNOSIS
Analyze:Review the history for differential diag- noses. 2.Act: • If you have sufficient information, provide yourFINAL DIAGNOSIS. • If not, ask exactlyONEfocused clarifying question
-
[8]
Style:Be professional, empathetic, and concise. Do not ask multiple questions at once. [FORMAT]For diagnosis, use: Final Diagnosis: [condition] Figure A3: Doctor LLM Prompt Template System Instruction: LLM as a Judge [ROLE]You are an expert clinical evaluator assess- ing the quality of a simulated patient interaction. [EV ALUATION DATA] Ground Truth Sympt...
work page 2006
-
[9]
Justified Denial:When a patient denies or omits a ground-truth symptom, the verifier checks whether this denial is justified by the assigned noise profile. For example, a patient with Level 3 Social-Cultural noise may legiti- mately deny alcohol use initially, but a patient with no social-cultural noise should not deny documented symptoms
-
[10]
The simulator cannot fabricate or alter these invariant facts regardless of noise profile
Invariant Consistency:Demographic infor- mation (age, sex, occupation) must match the patient profile exactly. The simulator cannot fabricate or alter these invariant facts regardless of noise profile
-
[11]
the pain started three days ago,
History Consistency:The verifier maintains a record of all patient statements within a con- versation and flags any contradictions. For ex- ample, if the patient previously stated “the pain started three days ago,” a later statement of “it began last month” would trigger regeneration. If any constraint check fails, regeneration is trig- gered with targete...
-
[12]
Batch Extraction:For each unique symp- tom across all patient cases, query the UMLS Metathesaurus once and cache the results
-
[13]
Structured Storage:Store the extracted con- text in a per-symptom JSON structure within each patient configuration
-
[14]
Runtime Loading:During conversation sim- ulation, load the pre-computed context no API calls required. This approach offers several advantages: (1) zero latency overhead during simulation, (2) no rate lim- iting concerns, (3) reproducible context across runs, and (4) ability to manually review and augment ex- tracted contexts. E.5 Context Extraction Algor...
-
[15]
Concept Resolution:Query the UMLS search endpoint to obtain the primary Concept Unique Identifier (CUI) for the symptom term
-
[16]
Synonym Extraction:Retrieve all English atoms (lexical variants) associated with the CUI. This captures alternative phrasings such as “chest pain,” “thoracic pain,” “pain in chest.”
-
[17]
Variation Discovery:Perform a word-based search to identify related concepts with differ- ent qualifiers (e.g., “burning chest pain,” “crush- ing chest pain,” “dull chest pain”)
-
[18]
SNOMED CT Relation Traversal:Query SNOMED CT source-asserted relations for the symptom’s SNOMED identifier. This yields richly structured clinical relationships includ- ing: • Associations:“accompanied by sweating,” “with nausea” • Locations:“left-sided,” “radiating to arm,” “between shoulder blades” • Modifiers:“made worse by exertion,” “re- lieved by re...
-
[19]
Structured Aggregation:Organize extracted information per-symptom to prevent context bleeding in multi-symptom cases. E.6 Example: Chest Pain Context For the symptom “chest pain” (CUI: C0008031, SNOMED: 29857009), our algorithm extracts the following semantic context A7: E.7 Example: Headache Context For the symptom “headache” (CUI: C0018681, SNOMED: 2506...
-
[20]
Flexibility:Permits semantically valid expres- sions that strict rules would reject (e.g., “my arm feels weird” with chest pain)
-
[21]
Rich Context:SNOMED CT relations provide clinically meaningful associations that capture real patient expression patterns. UMLS Context: Chest Pain Synonyms (29 English variants): • Chest Pain, Chest Pains, Pain in chest, Thoracic pain, PAIN CHEST, Pain;chest Variations (25 related concepts): • Dull chest pain, Burning chest pain, Crushing chest pain • Ra...
-
[22]
Semantic Reasoning:The LLM can handle novel phrasings not explicitly in UMLS by rea- soning about semantic similarity
-
[23]
Low False Positive Rate:Empirically achieves 9.3% hallucination rate while maintaining 4.04/5.0 realism score
-
[24]
recall” and “cognitive confusion
Zero Runtime Latency:Pre-computed con- texts eliminate API bottlenecks during simula- tion. F Additional Experimental Details F.1 Hyperparameters Table A3 summarizes the key hyperparameters used across all experimental runs. F.2 Compute Resources All experiments were conducted on a cluster with 8× NVIDIA A100 80GB GPUs. The 70B mod- els were run with 4-bi...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.