Mitigating Privacy Risk via Forget Set-Free Unlearning
Pith reviewed 2026-05-10 15:54 UTC · model grok-4.3
The pith
Partially-blind unlearning removes the influence of specific training data without retaining or accessing the forget set.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Partially-blind unlearning utilizes auxiliary information to remove the influence of a forget set without explicit access to it, operationalized by the Reload framework which combines gradient optimization with structured weight sparsification to achieve unlearning that approximates full retraining from scratch.
What carries the argument
The Reload framework, which performs gradient optimization using a small portion of the retain set and applies structured sparsification to model weights.
Load-bearing premise
Sufficient auxiliary information exists to accurately identify and remove the influence of the forget set without direct access to it.
What would settle it
A comparison where the unlearned model fails to match the accuracy or privacy properties of a model retrained from scratch on the retain set alone, or where membership inference attacks still detect the forgotten data.
Figures















read the original abstract
Training machine learning models requires the storage of large datasets, which often contain sensitive or private data. Storing data is associated with a number of potential risks which increase over time, such as database breaches and malicious adversaries. Machine unlearning is the study of methods to efficiently remove the influence of training data subsets from previously-trained models. Existing unlearning methods typically require direct access to the "forget set" -- the data to be forgotten-and organisations must retain this data for unlearning rather than deleting it immediately upon request, increasing risks associated with the forget set. We introduce partially-blind unlearning -- utilizing auxiliary information to unlearn without explicit access to the forget set. We also propose a practical framework Reload, a partially-blind method based on gradient optimization and structured weight sparsification to operationalize partially-blind unlearning. We show that Reload efficiently unlearns, approximating models retrained from scratch, and outperforms several forget set-dependent approaches. On language models, Reload unlearns entities using <0.025% of the retain set and <7% of model weights in <8 minutes on Llama2-7B. In the corrective case, Reload achieves unlearning even when only 10% of corrupted data is identified.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
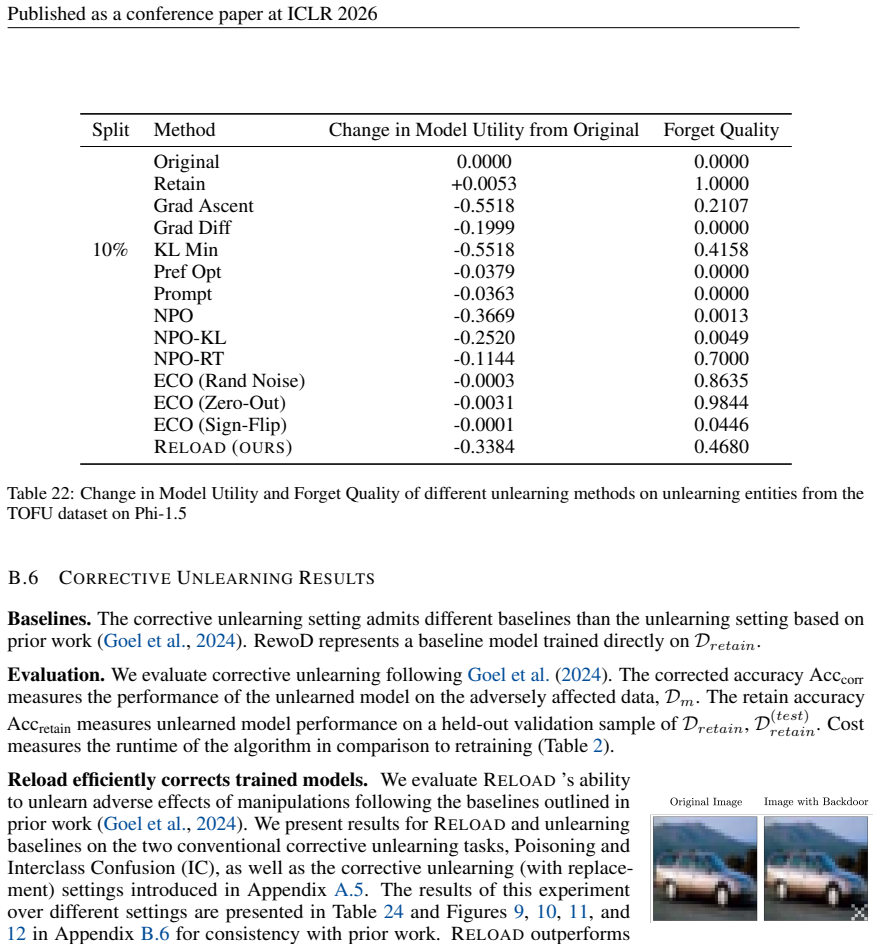
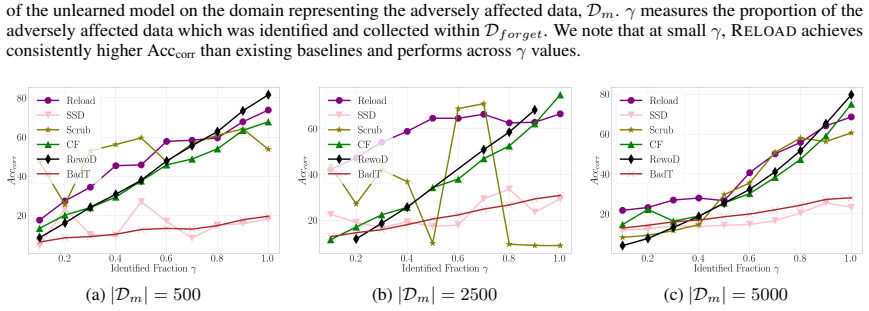
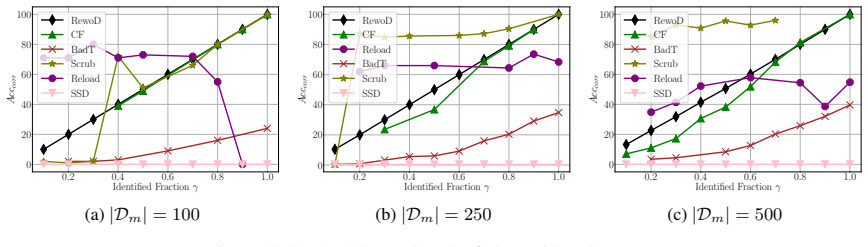
Summary. The paper introduces partially-blind unlearning, which removes the influence of a forget set from a trained model without direct access to that set by instead using auxiliary information. It proposes the Reload framework, which performs gradient optimization on the auxiliary data followed by structured weight sparsification. The central empirical claim is that Reload produces models that approximate those retrained from scratch, outperforms several forget-set-dependent baselines, and scales efficiently to large language models (e.g., unlearning entities on Llama2-7B using <0.025% of the retain set and <7% of model weights in <8 minutes). A secondary corrective-case result shows successful unlearning when only 10% of corrupted data is identified.
Significance. If the approximation to retrained-from-scratch models holds under the stated conditions, the work would meaningfully reduce the privacy risk of retaining sensitive data solely for future unlearning requests. The reported efficiency on Llama2-7B and the ability to operate with extremely small auxiliary sets are practically relevant for deployment. The absence of any free parameters or self-referential derivations is a positive feature, but the result remains empirical and its generalizability hinges on unproven assumptions about auxiliary-data coverage.
major comments (3)
- [Method (Reload framework)] The central claim that Reload approximates retrained-from-scratch models rests on the unstated assumption that gradients computed on the auxiliary set span the same directions as the (unseen) forget-set gradients. No analysis or bound is supplied showing when this spanning property holds, nor is there a demonstration that the subsequent structured sparsification removes rather than masks residual forget influence.
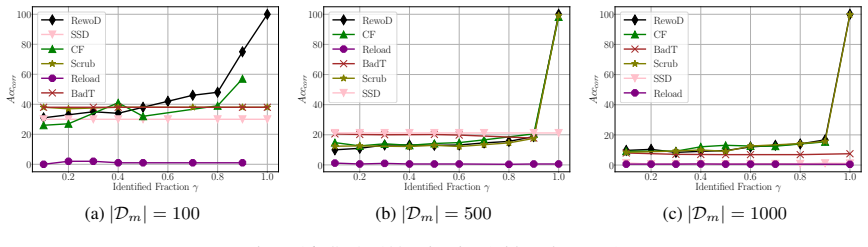
- [Experiments (corrective case)] The corrective-case experiment reports success when only 10% of corrupted data is identified. This result is consistent with the method succeeding primarily when auxiliary data already overlaps substantially with the target influence, yet no additional experiments test generalization to lower-overlap regimes or quantify the required overlap.
- [Experiments (language-model evaluation)] The language-model results claim unlearning with <0.025% of the retain set, but the manuscript supplies no protocol details on how the auxiliary set is sampled, how entity influence is measured, or statistical significance of the reported approximation to retraining. These omissions make it impossible to assess whether the efficiency numbers are robust or cherry-picked.
minor comments (2)
- [Introduction] The introduction of the term 'partially-blind unlearning' would benefit from an explicit contrast with fully blind and fully supervised unlearning in the first paragraph.
- [Preliminaries] Notation for the auxiliary set, retain set, and sparsification mask should be introduced once and used consistently; several passages reuse symbols without redefinition.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and the opportunity to improve our manuscript. We address each of the major comments point by point below, indicating where revisions will be made.
read point-by-point responses
-
Referee: [Method (Reload framework)] The central claim that Reload approximates retrained-from-scratch models rests on the unstated assumption that gradients computed on the auxiliary set span the same directions as the (unseen) forget-set gradients. No analysis or bound is supplied showing when this spanning property holds, nor is there a demonstration that the subsequent structured sparsification removes rather than masks residual forget influence.
Authors: We appreciate the referee pointing out the implicit assumption in our framework. Reload relies on the auxiliary data being representative enough for the gradient directions to align sufficiently with those of the forget set, as evidenced by our empirical approximations to retrained models. We agree that a formal bound would be valuable but is beyond the current scope; instead, we will expand the discussion to include conditions under which this alignment is expected (e.g., distributional similarity between auxiliary and forget data) and add experiments demonstrating that sparsification eliminates rather than merely masks the influence, such as through post-unlearning membership inference tests on the forget set. revision: partial
-
Referee: [Experiments (corrective case)] The corrective-case experiment reports success when only 10% of corrupted data is identified. This result is consistent with the method succeeding primarily when auxiliary data already overlaps substantially with the target influence, yet no additional experiments test generalization to lower-overlap regimes or quantify the required overlap.
Authors: We concur that exploring lower overlap regimes is important for understanding the method's applicability. We will add new experiments in the revised version that systematically vary the overlap between the identified auxiliary data and the target forget set, reporting performance metrics as a function of overlap percentage to quantify the required coverage for successful unlearning. revision: yes
-
Referee: [Experiments (language-model evaluation)] The language-model results claim unlearning with <0.025% of the retain set, but the manuscript supplies no protocol details on how the auxiliary set is sampled, how entity influence is measured, or statistical significance of the reported approximation to retraining. These omissions make it impossible to assess whether the efficiency numbers are robust or cherry-picked.
Authors: We regret the omission of these details. In the revision, we will include a comprehensive experimental protocol in the main text or appendix detailing: (1) the random sampling procedure for the auxiliary set from the retain set (excluding target entities), (2) the metrics for measuring entity influence (perplexity on targeted prompts and attack success rates), and (3) results averaged over multiple runs with standard deviations and statistical tests to confirm the robustness of the reported efficiency and approximation quality. revision: yes
- A formal theoretical analysis or bound on the conditions under which auxiliary-set gradients span the directions of the unseen forget-set gradients.
Circularity Check
No significant circularity; empirical claims rest on external validation
full rationale
The paper proposes Reload as a practical framework for partially-blind unlearning via gradient optimization and structured sparsification, with central claims consisting of empirical demonstrations that it approximates retrained-from-scratch models, outperforms forget-set-dependent baselines, and succeeds on Llama2-7B with tiny auxiliary data fractions. No equations, uniqueness theorems, or fitted parameters are presented as predictions; the derivation chain consists of algorithmic description followed by experimental results on held-out benchmarks. No self-citations are invoked as load-bearing mathematical facts, and no step reduces a claimed output to an input by construction. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
UCI Machine Learning Repository (1996).https: //doi.org/10.24432/C5GP7S
URLhttps://api.semanticscholar.org/CorpusID:6628106. Ron Kohavi. Census Income. UCI Machine Learning Repository, 1996. DOI: https://doi.org/10.24432/C5GP7S. Alex Krizhevsky. Learning multiple layers of features from tiny images.University of Toronto, 05 2012. Alex Krizhevsky, Vinod Nair, and Geoffrey Hinton. Cifar-100 (canadian institute for advanced rese...
-
[2]
Follow the style of [select one learning theory approach: In-Depth Exploration/Reflective Thinking/Summarization and Synthesis/Focus on Key Concepts/Contextual Understanding/Critical Analysis/Question-Based Learning]
-
[3]
Explicitly identify: • The fundamental concepts that must be understood • Key relationships between important elements • Critical facts that require focus for mastery • How these elements connect to and are relevant for reasoning or application
-
[4]
Be formatted as a directive that encourages active engagement with the material (approximately 3-5 sentences)
-
[5]
unlearn" the influence of{zi}i=1,...,K on our original model, and “relearn
Frame the learning in a way that facilitates long-term retention, practical application, and maximizes extracting knowledge from the learner. TARGET CONCEPT: {content} Your contextual prompt should help the learner not just memorize information but develop a deeper, more applicable understanding of the concept. """ A.5 CORRECTIVEUNLEARNING ANDGRADIENTDERI...
work page 2024
-
[6]
Covariate Correction: Dretain ={z ′ i = (x ′ i, yi)}i=1,...,K ∪ {z i}i=K+1,...,N , where x′ i represents a corrected version of the featuresxi, and indices K+1, ..., N correspond to those with erroneous covariates (e.g., data was corrupted during collection/pre-processing)
-
[7]
Label Correction: Dretain ={z ′ i = (xi, y′ i)}i=1,...,K ∪ {zi}i=K+1,...,N , where y′ i represents a corrected version of the label yi, and indices K+ 1, ..., N correspond to those that were originally mis-labelled during annotation
-
[8]
Backdoor Removal: Dretain ={z ′ i = (x ′ i, yi)}i=1,...,K ∪ {(xi, yi)}i=K+1,...,N , where x′ i represents a version of the features xi lacking the injected backdoor pattern, and indices K+ 1, ..., N correspond to those that were originally transformed with a backdoor during processing. Models trained with backdoors in the training set learn shortcuts (Gei...
work page 2020
-
[9]
Alpha (α): The quantile of weights to reinitialise
-
[10]
Ascent Learning Rate: The step size for the ascent stage of RELOAD
-
[11]
Finetuning Learning Rate: The step size for the finetuning stage of RELOAD
-
[12]
This setting is a hyperparameter of RELOAD
Weight Reset Method: The scheme to use for reinitialising weights B.7.1 WEIGHTRESET/REINITIALISATIONMETHODS First, we detail the different weight reinitialisation methods we explore as options for the resetting step of RELOAD. This setting is a hyperparameter of RELOAD. Mean.The selected parameters are replaced with the mean value of the tensor they are p...
work page 2010
-
[13]
ReloadWithoutAscent: This is the same as the standard RELOADalgorithm without the ascent step
-
[14]
ReloadWithNormalisation: This variant employs gradient normalisation before the calculation of knowledge values to increase directional information and reduce scaling issues
-
[15]
Select results for corrective unlearning are shown in Figure 17
ReloadWithCosineKV: This variant uses cosine similarity between gradients to compute knowledge values instead of gradient magnitudes We demonstrate these variants against the baselines RELOADalgorithm on corrective unlearning tasks. Select results for corrective unlearning are shown in Figure 17. (a) CIFAR10 Example 1 (b) CIFAR10 Example 2 (c) CIFAR100 Ex...
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.