Expect the Unexpected? Testing the Surprisal of Salient Entities
Pith reviewed 2026-05-10 16:07 UTC · model grok-4.3
The pith
Globally salient entities show higher surprisal but reduce it for surrounding content.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
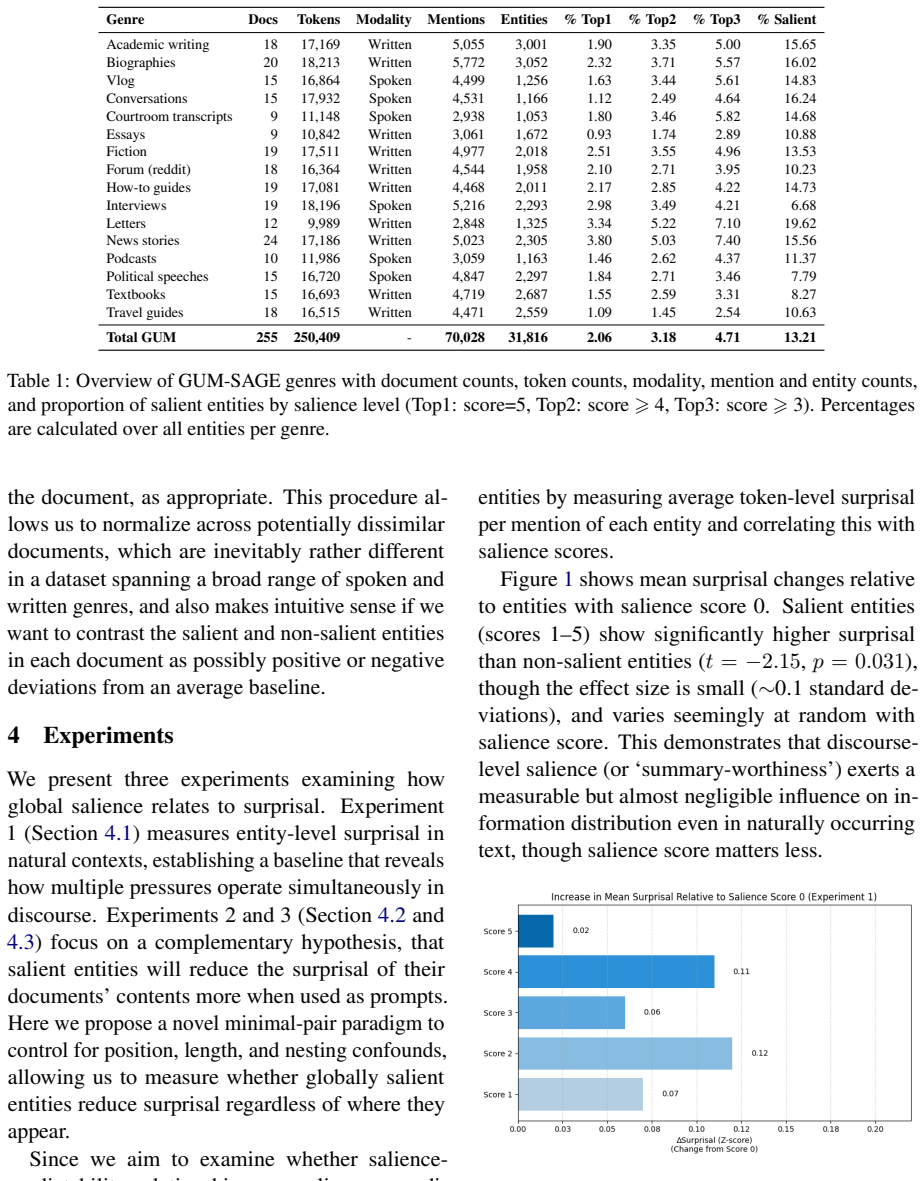
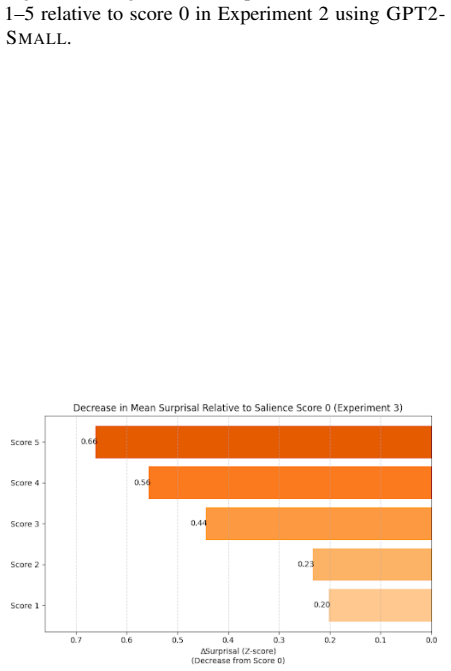
Globally salient entities exhibit significantly higher surprisal than non-salient ones, even controlling for position, length, and nesting confounds. Moreover, salient entities systematically reduce surprisal for surrounding content when used as prompts, enhancing document-level predictability. This effect varies by genre, appearing strongest in topic-coherent texts and weakest in conversational contexts. Our findings refine the UID competing pressures framework by identifying global entity salience as a mechanism shaping information distribution in discourse.
What carries the argument
Global entity salience, identified through manual annotation of 70K mentions, tested via minimal-pair prompting that measures surprisal differences with and without the salient entity in context.
If this is right
- Information density must be measured at both local and discourse-wide scales to capture how readers track important participants.
- Salient entities function as anchors that lower the surprise of later material, supporting more efficient overall communication.
- Genre differences show that information packaging adapts to the goals of the text, not just sentence-level rules.
- Language models may improve document-level coherence by treating salient entities as high-priority context.
Where Pith is reading between the lines
- The same salience-surprisal link could be tested in non-English languages to see whether discourse conventions differ.
- Writers might deliberately front-load salient entities in some genres to help readers build a stable mental model early.
- Automatic systems for detecting salience could be evaluated by checking whether they also predict where surprisal spikes occur.
Load-bearing premise
The manual labels for which entities count as globally salient are consistent and not shaped by the annotators already knowing the full text content.
What would settle it
Re-annotating salience on the same 70K mentions with new annotators and re-running the controlled surprisal comparisons yields no reliable difference between salient and non-salient entities.
Figures








read the original abstract
Previous work examining the Uniform Information Density (UID) hypothesis has shown that while information as measured by surprisal metrics is distributed more or less evenly across documents overall, local discrepancies can arise due to functional pressures corresponding to syntactic and discourse structural constraints. However, work thus far has largely disregarded the relative salience of discourse participants. We fill this gap by studying how overall salience of entities in discourse relates to surprisal using 70K manually annotated mentions across 16 genres of English and a novel minimal-pair prompting method. Our results show that globally salient entities exhibit significantly higher surprisal than non-salient ones, even controlling for position, length, and nesting confounds. Moreover, salient entities systematically reduce surprisal for surrounding content when used as prompts, enhancing document-level predictability. This effect varies by genre, appearing strongest in topic-coherent texts and weakest in conversational contexts. Our findings refine the UID competing pressures framework by identifying global entity salience as a mechanism shaping information distribution in discourse.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript investigates the relationship between global entity salience and surprisal in discourse, drawing on 70K manually annotated mentions across 16 English genres and a novel minimal-pair prompting procedure. It claims that salient entities exhibit significantly higher surprisal than non-salient ones after controlling for position, length, and nesting; that salient entities reduce surprisal for surrounding content when used as prompts; and that this effect is strongest in topic-coherent genres and weakest in conversational contexts. The work positions these findings as refining the Uniform Information Density hypothesis by identifying salience as an additional competing pressure on information distribution.
Significance. If the empirical results prove robust, the paper contributes a new mechanism—global entity salience—to the UID competing-pressures framework, supported by large-scale manual annotation and a controlled prompting design. The scale of the annotated data and the attempt to isolate salience via minimal pairs are clear strengths that could inform future discourse modeling and predictability research.
major comments (3)
- [Section 3] The annotation protocol (Section 3) does not report inter-annotator agreement, number of annotators per mention, or detailed guidelines for determining global salience; given that the central claims rest on the reliability of the 70K annotations, this omission is load-bearing for interpreting the surprisal differences.
- [Section 4] Results (Section 4) report statistical significance but omit effect sizes, exact test statistics, and a full account of how the controls for position, length, and nesting were implemented in the regression models; without these, the strength of the 'significantly higher surprisal' claim cannot be fully evaluated.
- [Section 5] The minimal-pair prompting method (Section 5) lacks sufficient specification of pair construction, prompt templates, and checks for model-specific artifacts; this is critical because the claim that salient entities enhance document-level predictability depends on the method cleanly isolating global salience.
minor comments (2)
- [Abstract] The abstract uses '70K' while the main text should adopt consistent numeric formatting (e.g., 70,000) for readability.
- [Figures] Figure captions and axis labels in the genre-variation plots could more explicitly state the surprisal metric and model used.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. The comments identify important gaps in reporting that we agree need to be addressed to strengthen the manuscript. We respond to each major comment below and commit to the corresponding revisions.
read point-by-point responses
-
Referee: [Section 3] The annotation protocol (Section 3) does not report inter-annotator agreement, number of annotators per mention, or detailed guidelines for determining global salience; given that the central claims rest on the reliability of the 70K annotations, this omission is load-bearing for interpreting the surprisal differences.
Authors: We agree that the current description of the annotation protocol is insufficient. In the revised manuscript we will add a new subsection to Section 3 that (a) reproduces the key portions of the annotation guidelines used to determine global salience (entity persistence, topical centrality, and discourse role), (b) states that three annotators independently labeled each of the 70K mentions with majority vote for final labels, and (c) reports inter-annotator agreement (Fleiss' kappa) computed on a held-out double-annotated subset. These additions will allow readers to evaluate the reliability of the salience distinctions that underpin the surprisal results. revision: yes
-
Referee: [Section 4] Results (Section 4) report statistical significance but omit effect sizes, exact test statistics, and a full account of how the controls for position, length, and nesting were implemented in the regression models; without these, the strength of the 'significantly higher surprisal' claim cannot be fully evaluated.
Authors: We accept that the statistical reporting in Section 4 is incomplete. The revision will include (i) effect sizes (standardized regression coefficients and partial R^{2} for the salience predictor), (ii) full test statistics (t-values, degrees of freedom, and exact p-values), and (iii) the complete model specification: a linear mixed-effects regression with fixed effects for salience, log(position), log(length), nesting (binary), and random intercepts for document and genre. We will also add a supplementary table with the full coefficient table and model diagnostics. revision: yes
-
Referee: [Section 5] The minimal-pair prompting method (Section 5) lacks sufficient specification of pair construction, prompt templates, and checks for model-specific artifacts; this is critical because the claim that salient entities enhance document-level predictability depends on the method cleanly isolating global salience.
Authors: We agree that the minimal-pair procedure requires fuller documentation. In the revised Section 5 we will (a) describe the exact criteria and matching procedure used to construct each salient/non-salient pair (frequency, syntactic role, and linear position), (b) reproduce the full prompt templates together with an example pair, and (c) report robustness checks across two additional models plus controls for prompt length and lexical overlap. These details will demonstrate that the observed reduction in surrounding surprisal is attributable to global salience rather than model-specific or surface-form artifacts. revision: yes
Circularity Check
Empirical study with no circular derivation
full rationale
The paper's central claims rest on new empirical data from 70K manually annotated entity mentions across 16 genres of English plus a novel minimal-pair prompting method. These support the reported findings on surprisal differences for salient entities and their effects on surrounding content, after controlling for position, length, and nesting. No load-bearing step reduces by construction to self-citations, fitted parameters renamed as predictions, or self-definitional equations; the derivation chain consists of data collection, statistical controls, and genre-specific observations that are independently falsifiable outside the paper's own inputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Surprisal metrics derived from language models serve as a reliable proxy for information content and predictability in natural discourse.
- domain assumption Manually annotated entity salience labels accurately capture global importance independent of local context.
Reference graph
Works this paper leans on
-
[1]
Jennifer E Arnold. 2010. How speakers refer: The role of accessibility. Language and Linguistics Compass, 4(4):187--203
work page 2010
-
[2]
Jennifer E Arnold. 2025. Why does recency guide pronoun comprehension? I t’s not just topicality, attention, or predictability. Discourse Processes, pages 1--23
work page 2025
-
[3]
Vincent Boswijk and Matt Coler. 2020. https://doi.org/doi:10.1515/opli-2020-0042 What is salience? Open Linguistics, 6(1):713--722
-
[4]
Wallace Chafe. 1994. Discourse, Consciousness, and Time. The Flow and Displacementof Conscious Experiencein Speaking and Writing. University of Chicago Press, Chicago & London
work page 1994
-
[5]
Thomas Hikaru Clark, Clara Meister, Tiago Pimentel, Michael Hahn, Ryan Cotterell, Richard Futrell, and Roger Levy. 2023. https://doi.org/10.1162/tacl_a_00589 A cross-linguistic pressure for U niform I nformation D ensity in word order . Transactions of the Association for Computational Linguistics, 11:1048--1065
-
[6]
Thomas Hikaru Clark, Ethan Gotlieb Wilcox, Edward Gibson, and Roger P. Levy. 2022. Evidence for availability effects on speaker choice in the R ussian comparative alternation. In Proceedings of the 44th Annual Meeting of the Cognitive Science Society, pages 3044--3050
work page 2022
-
[7]
Manning, Joakim Nivre, and Daniel Zeman
Marie-Catherine de Marneffe, Christopher D. Manning, Joakim Nivre, and Daniel Zeman. 2021. https://doi.org/10.1162/coli_a_00402 U niversal D ependencies . Computational Linguistics, 47(2):255--308
-
[8]
Milan Dojchinovski, Dinesh Reddy, Tom \'a s Kliegr, Tom \'a s Vitvar, and Harald Sack. 2016. Crowdsourced corpus with entity salience annotations. In Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC'16), pages 3307--3311
work page 2016
-
[9]
Jesse Dunietz and Dan Gillick. 2014. A new entity salience task with millions of training examples. In Proceedings of the 14th Conference of the European Chapter of the Association for Computational Linguistics, volume 2: Short Papers, pages 205--209
work page 2014
-
[10]
August Fenk and Gertraud Fenk. 1980. Konstanz im K urzzeitgedächtnis -- K onstanz im sprachlichen I nformationsfluß? Zeitschrift für experimentelle und angewandte Psychologie, 27(3):400--414
work page 1980
-
[11]
Michael Gamon, Tae Yano, Xinying Song, Johnson Apacible, and Patrick Pantel. 2013. Identifying salient entities in web pages. In Proceedings of the 22nd ACM international conference on Information & Knowledge Management, pages 2375--2380
work page 2013
-
[12]
Matteo Gay, Coleman Haley, Mario Giulianelli, and Edoardo Ponti. 2026. https://doi.org/10.18653/v1/2026.eacl-long.178 Is information density uniform when utterances are grounded on perception and discourse? In Proceedings of the 19th Conference of the E uropean Chapter of the A ssociation for C omputational L inguistics (Volume 1: Long Papers) , pages 382...
- [13]
-
[14]
Barbara J. Grosz, Aravind K. Joshi, and Scott Weinstein. 1995. https://aclanthology.org/J95-2003/ C entering: A framework for modeling the local coherence of discourse . Computational Linguistics, 21(2):203--225
work page 1995
-
[15]
Barbara J. Grosz and Candace L. Sidner. 1986. https://aclanthology.org/J86-3001/ Attention, intentions, and the structure of discourse . Computational Linguistics, 12(3):175--204
work page 1986
-
[16]
T. Florian Jaeger and Roger Levy. 2006. https://proceedings.neurips.cc/paper_files/paper/2006/file/c6a01432c8138d46ba39957a8250e027-Paper.pdf Speakers optimize information density through syntactic reduction . In Advances in Neural Information Processing Systems, volume 19. MIT Press
work page 2006
-
[17]
Jessica Lin and Amir Zeldes. 2021. https://doi.org/10.18653/v1/2021.law-1.18 W iki GUM : Exhaustive entity linking for wikification in 12 genres . In Proceedings of the Joint 15th Linguistic Annotation Workshop (LAW) and 3rd Designing Meaning Representations (DMR) Workshop, pages 170--175, Punta Cana, Dominican Republic. Association for Computational Linguistics
-
[18]
Jessica Lin and Amir Zeldes. 2025. https://doi.org/10.18653/v1/2025.findings-acl.24 GUM - SAGE : A novel dataset and approach for graded entity salience prediction . In Findings of the Association for Computational Linguistics: ACL 2025, pages 438--455, Vienna, Austria. Association for Computational Linguistics
-
[19]
Yang Janet Liu, Tatsuya Aoyama, Wesley Scivetti, Yilun Zhu, Shabnam Behzad, Lauren Elizabeth Levine, Jessica Lin, Devika Tiwari, and Amir Zeldes. 2024. https://doi.org/10.18653/v1/2024.emnlp-main.684 GDTB : Genre diverse data for E nglish shallow discourse parsing across modalities, text types, and domains . In Proceedings of the 2024 Conference on Empiri...
-
[20]
Yang Janet Liu and Amir Zeldes. 2023. https://doi.org/10.18653/v1/2023.findings-acl.593 GUMS um: Multi-genre data and evaluation for E nglish abstractive summarization . In Findings of the Association for Computational Linguistics: ACL 2023, pages 9315--9327, Toronto, Canada. Association for Computational Linguistics
-
[21]
Clara Meister, Tiago Pimentel, Patrick Haller, Lena J \"a ger, Ryan Cotterell, and Roger Levy. 2021. https://doi.org/10.18653/v1/2021.emnlp-main.74 Revisiting the U niform I nformation D ensity hypothesis . In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 963--980, Online and Punta Cana, Dominican Republic. ...
-
[22]
Tiago Pimentel, Ryan Cotterell, and Brian Roark. 2021. https://doi.org/10.18653/v1/2021.eacl-main.3 Disambiguatory signals are stronger in word-initial positions . In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, pages 31--41, Online. Association for Computational Linguistics
-
[23]
Hannah Rohde and Andrew Kehler. 2014. Grammatical and information-structural influences on pronoun production. Language, Cognition and Neuroscience, 29(8):912--927
work page 2014
-
[24]
Péter Rácz. 2013. https://doi.org/doi:10.1515/9783110305395 Salience in Sociolinguistics. A Quantitative Approach . De Gruyter Mouton, Berlin, Boston
-
[25]
Victor Sanh, Lysandre Debut, Julien Chaumond, and Thomas Wolf. 2019. Distilbert, a distilled version of bert: smaller, faster, cheaper and lighter. In NeurIPS EMC 2 Workshop
work page 2019
-
[26]
Eleftheria Tsipidi, Franz Nowak, Ryan Cotterell, Ethan Wilcox, Mario Giulianelli, and Alex Warstadt. 2024. https://doi.org/10.18653/v1/2024.emnlp-main.1047 Surprise! U niform I nformation D ensity isn`t the whole story: Predicting surprisal contours in long-form discourse . In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Pro...
-
[27]
Klaus von Heusinger and Petra B. Schumacher. 2019. https://doi.org/10.1016/j.pragma.2019.07.025 Discourse prominence: Definition and application . Journal of Pragmatics, 154:117--127
-
[28]
Chuan Wu, Evangelos Kanoulas, Maarten de Rijke, and Wei Lu. 2020. WN-Salience : A corpus of news articles with entity salience annotations. In Proceedings of the 12th Language Resources and Evaluation Conference, pages 2095--2102
work page 2020
-
[29]
Alessandra Zarcone, Marten Van Schijndel, Jorrig Vogels, and Vera Demberg. 2016. Salience and attention in surprisal-based accounts of language processing. Frontiers in Psychology, 7(844)
work page 2016
-
[30]
Amir Zeldes. 2017. The GUM corpus: Creating multilayer resources in the classroom. Language Resources and Evaluation, 51(3):581--612
work page 2017
-
[31]
Amir Zeldes. 2022. https://doi.org/10.5210/dad.2022.102 Can we fix the scope for coreference? P roblems and solutions for benchmarks beyond OntoNotes . Dialogue & Discourse, 13(1):41--62
-
[32]
Amir Zeldes, Katherine Conhaim, and Lauren Levine. 2026. https://arxiv.org/abs/2603.27358 Not worth mentioning? A pilot study on salient proposition annotation . ArXiv preprint 2603.27358
work page internal anchor Pith review arXiv 2026
-
[33]
Yilun Zhu, Sameer Pradhan, and Amir Zeldes. 2021. https://doi.org/10.18653/v1/2021.acl-short.59 O nto GUM : Evaluating contextualized SOTA coreference resolution on 12 more genres . In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 2...
-
[34]
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[35]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.