GPU acceleration of plane-wave density functional theory calculations in Abinit
Pith reviewed 2026-05-10 15:00 UTC · model grok-4.3
The pith
Abinit achieves GPU speedups for plane-wave DFT by revising the Kohn-Sham iterative diagonalizer.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The Abinit implementation on multi-GPU architectures relies on algorithmic revisions of the iterative diagonalization procedure in the resolution of the Kohn-Sham problem to identify GPU-efficient mathematical operations (linear algebra, FFTs) applied to wave functions distributed in memory, and supplies detailed performance results comparing CPU nodes versus heterogeneous CPU-GPU nodes together with a comparison of LOBPCG and Chebyshev polynomial filtering in terms of GPU efficiency.
What carries the argument
Revised iterative diagonalization procedure that selects and applies GPU-efficient linear algebra and FFT operations to distributed wave functions.
If this is right
- Heterogeneous CPU-GPU nodes deliver higher throughput than CPU-only nodes for the same plane-wave DFT workloads.
- Chebyshev polynomial filtering exploits GPU resources more effectively than LOBPCG in this setting.
- Vendor library calls for linear algebra and FFTs become the dominant computational kernels after the revisions.
- Large-scale electronic structure runs become feasible on GPU-equipped supercomputers without changing the underlying physics model.
Where Pith is reading between the lines
- The same pattern of favoring linear algebra and FFT operations could be applied to accelerate other plane-wave DFT packages.
- Further gains may appear when the number of GPU nodes grows into the hundreds for systems containing thousands of atoms.
- The reported speedups assume that data movement between CPU and GPU remains a minor fraction of total time.
- Verification on a broader set of materials and properties would strengthen that accuracy is preserved.
Load-bearing premise
The algorithmic revisions to the iterative diagonalization preserve numerical accuracy and convergence properties of the original CPU implementation.
What would settle it
Identical input system yields total energies or forces that differ beyond floating-point tolerance when the same calculation is run on the original CPU version versus the GPU version.
Figures






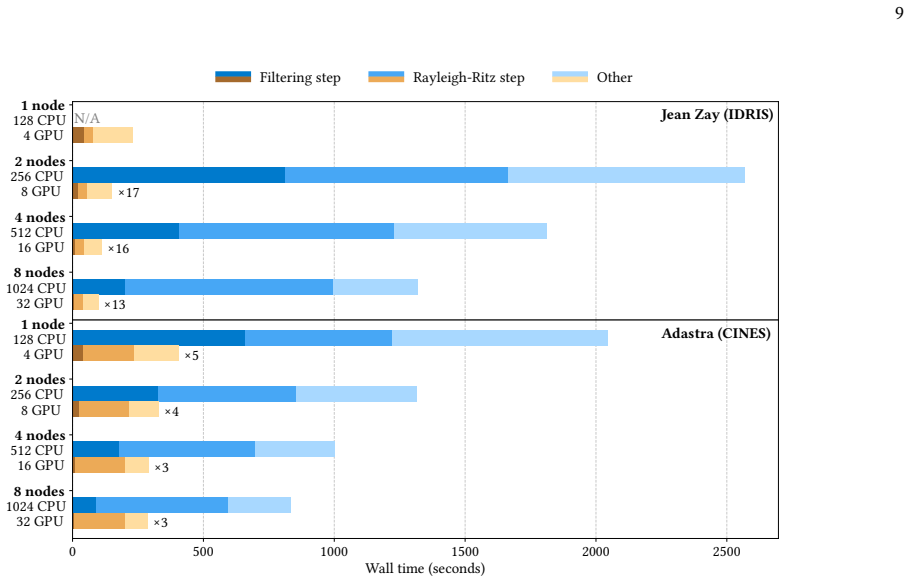



read the original abstract
We report on the GPU porting of the Abinit high-performance simulation code for plane-wave DFT calculations. Large-scale electronic structure calculations require computing the electronic wave function by solving the Kohn-Sham problem discretized over a large number of plane-wave basis functions. Porting such calculations over hundreds of GPU nodes relies not only on extensive usage of vendor libraries from a development perspective, but also on algorithmic revisions of the iterative diagonalization procedure in the resolution of the Kohn-Sham problem to identify GPU-efficient mathematical operations (linear algebra, FFTs) applied to wave functions distributed in memory. The present contribution discusses the Abinit implementation on multi-GPU architectures, providing detailed performance results to compare CPU nodes versus heterogeneous CPU-GPU nodes. Particular attention is given in the comparison of two different diagonalization algorithms, that is Locally Optimal Block Preconditioned Conjugate Gradient and Chebyshev polynomial filtering, in terms of their GPU efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reports the GPU porting of the Abinit plane-wave DFT code, emphasizing algorithmic revisions to the LOBPCG and Chebyshev polynomial filtering iterative diagonalization procedures to identify GPU-efficient operations (linear algebra and FFTs) on distributed wave functions. It provides performance benchmarks comparing CPU-only nodes to heterogeneous CPU-GPU nodes, with particular focus on the relative GPU efficiency of the two diagonalization algorithms.
Significance. If the central claims hold, this contribution would be significant for enabling scalable large-scale electronic structure calculations on modern GPU-accelerated HPC systems. The explicit comparison of LOBPCG versus Chebyshev filtering on GPUs offers practical guidance for algorithm selection in similar codes, and the reliance on vendor libraries plus distributed-memory considerations addresses key implementation challenges in the field.
major comments (2)
- [§5] §5 (Performance results), Tables 1-3: The reported timings for LOBPCG and Chebyshev filtering on CPU versus CPU-GPU nodes do not include any side-by-side numerical equivalence metrics (e.g., total energy differences, eigenvalue residuals, or iteration counts to convergence) for identical inputs and systems. This is load-bearing for the claim that the algorithmic revisions preserve the original numerical accuracy and convergence properties while delivering the speedups.
- [Implementation section] Implementation section (preceding the benchmarks): The description of the revisions to the iterative diagonalization does not specify how the GPU paths maintain mathematical equivalence to the CPU versions (e.g., identical preconditioning, filtering polynomials, or convergence criteria). Without this, it is unclear whether observed speedups reflect true acceleration or altered iteration behavior.
minor comments (2)
- [Abstract] The abstract states that 'detailed performance results' are provided yet contains no quantitative values, error bars, or system sizes; moving a representative timing or speedup figure into the abstract would improve immediate readability.
- [Figures] Figure captions for the performance plots should explicitly state the number of nodes, basis-set sizes, and whether single- or double-precision arithmetic was used.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive comments on our manuscript describing the GPU porting of Abinit's plane-wave DFT solver. The feedback correctly identifies the need for explicit numerical validation and clearer description of algorithmic equivalence, both of which we will address in the revision. Our point-by-point responses follow.
read point-by-point responses
-
Referee: [§5] §5 (Performance results), Tables 1-3: The reported timings for LOBPCG and Chebyshev filtering on CPU versus CPU-GPU nodes do not include any side-by-side numerical equivalence metrics (e.g., total energy differences, eigenvalue residuals, or iteration counts to convergence) for identical inputs and systems. This is load-bearing for the claim that the algorithmic revisions preserve the original numerical accuracy and convergence properties while delivering the speedups.
Authors: We agree that side-by-side numerical equivalence metrics are necessary to substantiate that the GPU ports preserve accuracy and convergence behavior. In the revised manuscript we will add a dedicated subsection (or supplementary table) in §5 that reports, for each benchmark system and both diagonalization methods, the total energy, maximum eigenvalue residual, and number of iterations to convergence on CPU-only versus CPU-GPU nodes using identical input parameters. These quantities will be shown to agree to within double-precision round-off, confirming that the observed speedups arise from hardware acceleration rather than altered numerics. revision: yes
-
Referee: [Implementation section] Implementation section (preceding the benchmarks): The description of the revisions to the iterative diagonalization does not specify how the GPU paths maintain mathematical equivalence to the CPU versions (e.g., identical preconditioning, filtering polynomials, or convergence criteria). Without this, it is unclear whether observed speedups reflect true acceleration or altered iteration behavior.
Authors: We accept that the implementation section would benefit from greater explicitness on mathematical equivalence. We will revise the text to state that the GPU paths employ exactly the same preconditioning operators, the same Chebyshev polynomial degrees and filtering coefficients, and the identical convergence thresholds and stopping criteria as the CPU implementations. The algorithmic changes are limited to reordering and offloading linear-algebra and FFT kernels to vendor libraries while preserving the mathematical structure of both LOBPCG and Chebyshev filtering; iteration counts and residual histories therefore remain unchanged. revision: yes
Circularity Check
No circularity: empirical implementation and benchmarking report
full rationale
The paper is a porting and performance benchmarking study of Abinit on GPUs. It describes algorithmic revisions to iterative diagonalization (LOBPCG and Chebyshev filtering) for GPU efficiency and reports timing comparisons between CPU and heterogeneous nodes. No derivation chain, first-principles predictions, fitted parameters renamed as outputs, or self-citation load-bearing arguments exist. Central claims rest on measured wall-clock times and GPU utilization, which are direct empirical observations rather than quantities constructed from the paper's own inputs. The absence of any claimed mathematical equivalence or predictive derivation precludes circularity by the defined criteria.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard Kohn-Sham equations discretized in a plane-wave basis
Reference graph
Works this paper leans on
- [1]
- [2]
-
[3]
Ruffino, F. F. et al., Procedia Comput. Sci.240(2024) 52–60
work page 2024
-
[4]
et al., Journal of Computational Chemistry33 (2012) 2581
Hacene, M. et al., Journal of Computational Chemistry33 (2012) 2581
work page 2012
-
[5]
Stegailov, V. and Vecher, V., Efficiency Analysis of Intel, AMD and Nvidia 64-Bit Hardware for Memory-Bound Problems: A Case Study of Ab Initio Calculations with VASP, inParallel 12 0 25 50 75 100 125 150 Execution Time per Iteration (s) 4 6 8 10 12 Polynomial Degree,nline ×3.52 ×5.91 ×3.91 ×7.35 ×4.20 ×8.52 ×4.39 ×9.60 ×4.53 ×11.00 LOBPCG CPU LOBPCG GPU ...
work page 2018
-
[6]
Su- percomput.80(2024) 16679–16702
Nieves-Pérez, I., Muñoz, A., Almeida, F., and Blanco, V., J. Su- percomput.80(2024) 16679–16702
work page 2024
-
[7]
Genovese, L., Videau, B., Deutsch, T., Tran, H., and Goedecker, S., Improvements of BigDFT code in modern HPC architec- tures, 2011, PRACE White Paper
work page 2011
-
[8]
Mortensen, J. J. et al., The Journal of Chemical Physics160 (2024) 092503
work page 2024
-
[9]
M., and Gavini, V., Computer Physics Communications280(2022) 108473
Das, S., Motamarri, P., Subramanian, V., Rogers, D. M., and Gavini, V., Computer Physics Communications280(2022) 108473
work page 2022
-
[10]
Das, S. et al., Fast, scalable and accurate finite-element based ab initio calculations using mixed precision computing: 46 PFLOPS simulation of a metallic dislocation system, inProceed- ings of the International Conference for High Performance Com- puting, Networking, Storage and Analysis, SC ’19, New York, NY, USA, 2019, Association for Computing Machinery
work page 2019
-
[11]
E., and Suryanarayana, P., The Journal of Chemical Physics162(2025) 184105
Jing, X., Sharma, A., Pask, J. E., and Suryanarayana, P., The Journal of Chemical Physics162(2025) 184105
work page 2025
-
[12]
Verstraete, M. J. et al., The Journal of Chemical Physics163 (2025) 164126
work page 2025
-
[13]
et al., Modelling and Simulation in Materials Science and Engineering31(2023) 063301
Gavini, V. et al., Modelling and Simulation in Materials Science and Engineering31(2023) 063301
work page 2023
-
[14]
et al., Numerical Linear Algebra with Applications 21(2014) 457
Dongarra, J. et al., Numerical Linear Algebra with Applications 21(2014) 457. Algorithm Degree Wall Time # SCF Squared WF residual ndeg(s) iterations at iter. 1 ChebFi 4 295.8 28 3.0e-6 6 204.0 17 2.6e-6 8 198.8 15 1.5e-6 10 198.8 14 1.0e-6 12 204.7 14 8.0e-7 14 221.4 14 2.5e-7 AlgorithmnlineWall Time # SCF Squared WF residual (s) iterations at iter. 1 LO...
work page 2014
-
[15]
Carter Edwards, H., Trott, C. R., and Sunderland, D., Jour- nal of Parallel and Distributed Computing74(2014) 3202, Domain-Specific Languages and High-Level Frameworks for High-Performance Computing
work page 2014
-
[16]
Torrent, M.,Density-Functional Theory electronic structure cal- culations within the “Projector Augmented-Wave” approach, Ha- bilitation à diriger des recherches, Université Paris - Saclay, 2024
work page 2024
-
[17]
Frigo, M. and Johnson, S. G., FFTW: An adaptive software ar- chitecture for the FFT, inProceedings of the 1998 IEEE Inter- national Conference on Acoustics, Speech and Signal Processing, ICASSP’98 (Cat. No. 98CH36181), volume 3, pages 1381–1384, IEEE, 1998
work page 1998
-
[18]
NVIDIA Corporation, cuFFT: the CUDA Fast Fourier Trans- form library,https://developer.nvidia.com/cufft, Ac- cessed: 2026-04-08
work page 2026
-
[19]
Advanced Micro Devices, Inc., hipFFT: an FFT marshalling library,https://rocm.docs.amd.com/projects/hipFFT, Accessed: 2026-04-08
work page 2026
-
[20]
Haidar, A., Dong, T. T., Tomov, S., Luszczek, P., and Dongarra, J., A Framework for Batched and GPU-Resident Factorization Algorithms Applied to Block Householder Transformations, in High Performance Computing, edited by Kunkel, J. M. and Lud- wig, T., pages 31–47, Cham, 2015, Springer International Pub- lishing
work page 2015
- [21]
-
[22]
Bottin, F., Leroux, S., Knyazev, A., and Zérah, G., Computa- tional Materials Science42(2008) 329
work page 2008
-
[23]
and Torrent, M., Computer Physics Communications 187(2015) 98
Levitt, A. and Torrent, M., Computer Physics Communications 187(2015) 98
work page 2015
-
[24]
Demmel, J. W., Marques, O. A., Parlett, B. N., and Vömel, C., SIAM Journal on Scientific Computing30(2008) 1508
work page 2008
-
[25]
Cooley, J. W. and Tukey, J. W., Mathematics of Computation 19(1965) 297
work page 1965
-
[26]
Thakur, R., Rabenseifner, R., and Gropp, W., The Interna- tional Journal of High Performance Computing Applications 19(2005) 49
work page 2005
-
[27]
OpenMP Architecture Review Board, OpenMP Application Programming Interface, Version 5.0, Specification, 2018
work page 2018
-
[28]
nvidia.com/cuda/toolkit, Accessed: 2026-04-08
NVIDIA Corporation, CUDA Toolkit,https://developer. nvidia.com/cuda/toolkit, Accessed: 2026-04-08
work page 2026
-
[29]
Advanced Micro Devices, Inc., AMD ROCm Software for HPC,https://www.amd.com/en/products/software/ rocm/hpc.html, Accessed: 2026-04-08
work page 2026
-
[30]
Advanced Micro Devices, Inc., rocFFT: discrete FFT written in HIP,https://rocm.docs.amd.com/projects/rocFFT, Accessed: 2026-04-08
work page 2026
-
[31]
NVIDIA Corporation, cuBLAS: Basic Linear Algebra on NVIDIA GPUs,https://developer.nvidia.com/cublas, Accessed: 2026-04-08
work page 2026
-
[32]
com/projects/rocBLAS, Accessed: 2026-04-08
Advanced Micro Devices, Inc., rocBLAS: the ROCm Basic Lin- ear Algebra Subprograms library,https://rocm.docs.amd. com/projects/rocBLAS, Accessed: 2026-04-08
work page 2026
-
[33]
NVIDIA Corporation, cuSOLVER: Direct Linear Solvers on NVIDIA GPUs,https://developer.nvidia.com/ cusolver, Accessed: 2026-04-08
work page 2026
-
[34]
amd.com/projects/rocSOLVER, Accessed: 2026-04-08
Advanced Micro Devices, Inc., rocSOLVER: LAPACK routines on top of the AMD ROCm platform,https://rocm.docs. amd.com/projects/rocSOLVER, Accessed: 2026-04-08
work page 2026
-
[35]
et al., Journal of Physics: Condensed Matter26 (2014) 213201
Marek, A. et al., Journal of Physics: Condensed Matter26 (2014) 213201
work page 2014
-
[36]
NVIDIA Corporation, Nsight Compute an interactive profiler for CUDA,https://developer.nvidia.com/ nsight-compute, Accessed: 2026-04-08
work page 2026
-
[37]
Williams, S., Waterman, A., and Patterson, D., Commun. ACM 52(2009) 65–76
work page 2009
-
[38]
NVIDIA Corporation, NVIDIA A100 Tensor Core GPU Archi- tecture,https://www.nvidia.com/en-us/data-center/ a100, Accessed: 2026-04-08
work page 2026
-
[39]
R., Computer Physics Communications254(2020) 107330
Liou, K.-H., Yang, C., and Chelikowsky, J. R., Computer Physics Communications254(2020) 107330
work page 2020
-
[40]
R., and Saad, Y., Computer Physics Communications183(2012) 497
Schofield, G., Chelikowsky, J. R., and Saad, Y., Computer Physics Communications183(2012) 497
work page 2012
-
[41]
CCRT, CCRT: Research and Technology Computing Cen- ter,https://www-hpc.cea.fr/en/CCRT.html, Accessed: 2026-04-08
work page 2026
-
[42]
IDRIS, IDRIS High Performance Computing Center,https: //www.idris.fr/eng/, Accessed: 2026-04-08
work page 2026
-
[43]
CINES, CINES High Performance Computing Center,https: //www.cines.fr, Accessed: 2026-04-08. Appendix A: Machine specifications Technical specifications of the CPU/GPU hybrid partitions used for benchmarking are shown in Table III. Appendix B:AbinitGPU-enabled functionalities Table IV summarizes GPU-enabled functionalities in Abinitversion 10.6. 14 Superco...
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.