Environmental Footprint of GenAI Research: Insights from the Moshi Foundation Model
Pith reviewed 2026-05-10 16:19 UTC · model grok-4.3
The pith
A full accounting of GPU time across all stages of multi-modal model development shows research experiments and failures add substantially to its environmental costs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors claim that a fine-grained quantification of GPU-time invested in specific model components, training phases, early experimental stages, failed training runs, debugging, and ablation studies, when combined with life cycle assessment of the complete development process, fully captures the environmental impacts of creating the model, including energy and water consumption, greenhouse gas emissions, and mineral resource depletion from hardware production and use, and that this accounting yields actionable guidelines to reduce those impacts.
What carries the argument
Life cycle assessment methodology applied to the full research and development process, with detailed breakdown of compute usage by model component and activity phase.
If this is right
- Identifying the largest shares of compute in ablation studies and failed runs makes it possible to redesign experiments to avoid those costs.
- Reporting the full research footprint rather than only final training produces more accurate totals for the environmental costs of foundation models.
- The derived guidelines can be applied directly to other multi-modal projects to cut energy, water, and emission impacts.
- Transparency about every development stage encourages labs to log and optimize activities that currently remain hidden.
Where Pith is reading between the lines
- Labs that adopt similar detailed logging could compare patterns across projects and identify common high-cost phases industry-wide.
- The same methodology could be tested on smaller or open-source models to check whether the relative cost of research stages scales with model size.
- Regulators could require full-process accounting as a condition for large-scale AI grants or deployments.
Load-bearing premise
The complete and accurate compute logs and hardware specifications supplied by the development team fully represent all activities, and the chosen life-cycle assessment boundaries and emission factors capture the dominant environmental impacts without significant omissions.
What would settle it
An independent audit that uncovers substantial unreported GPU usage, additional hardware manufacturing effects, or materially different emission factors would show the reported totals and impact estimates to be incomplete or inaccurate.
Figures
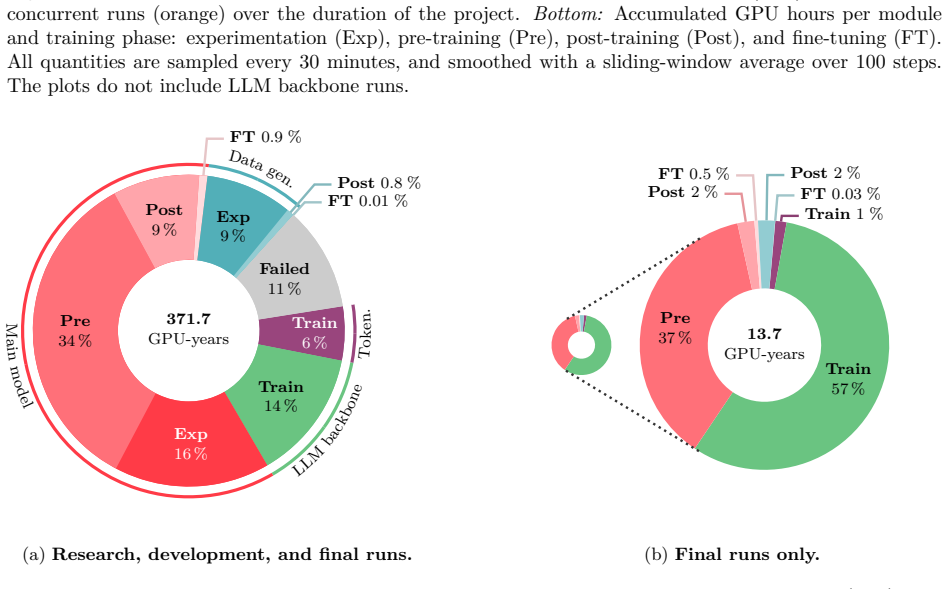
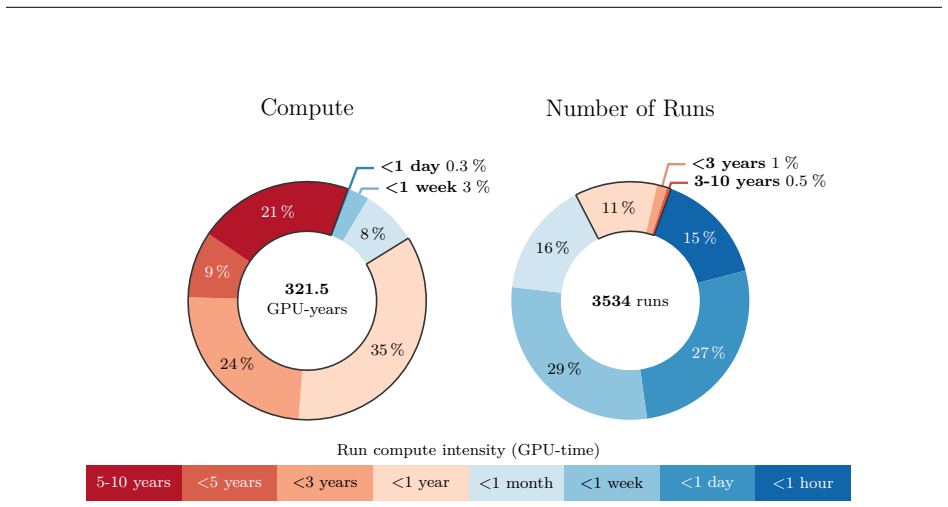
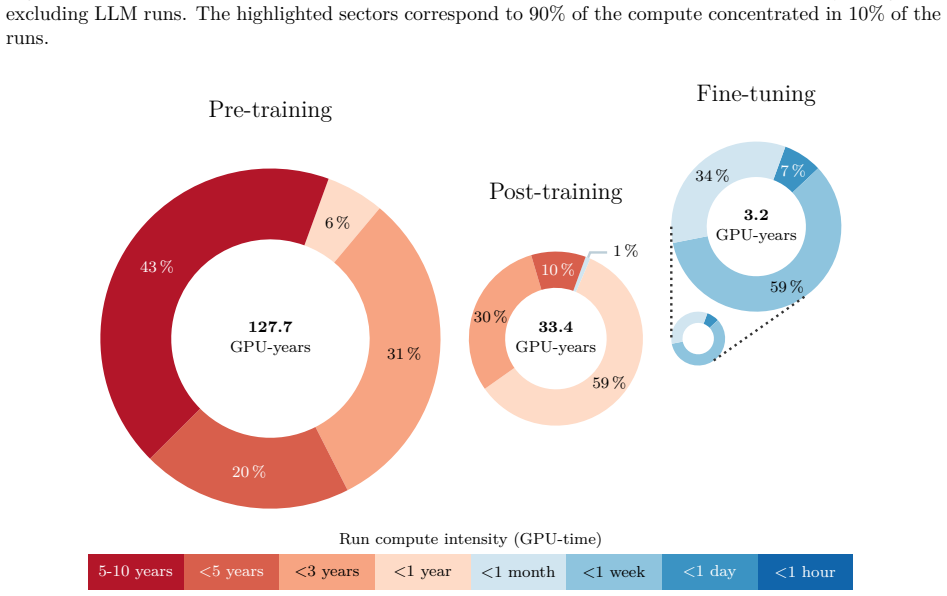
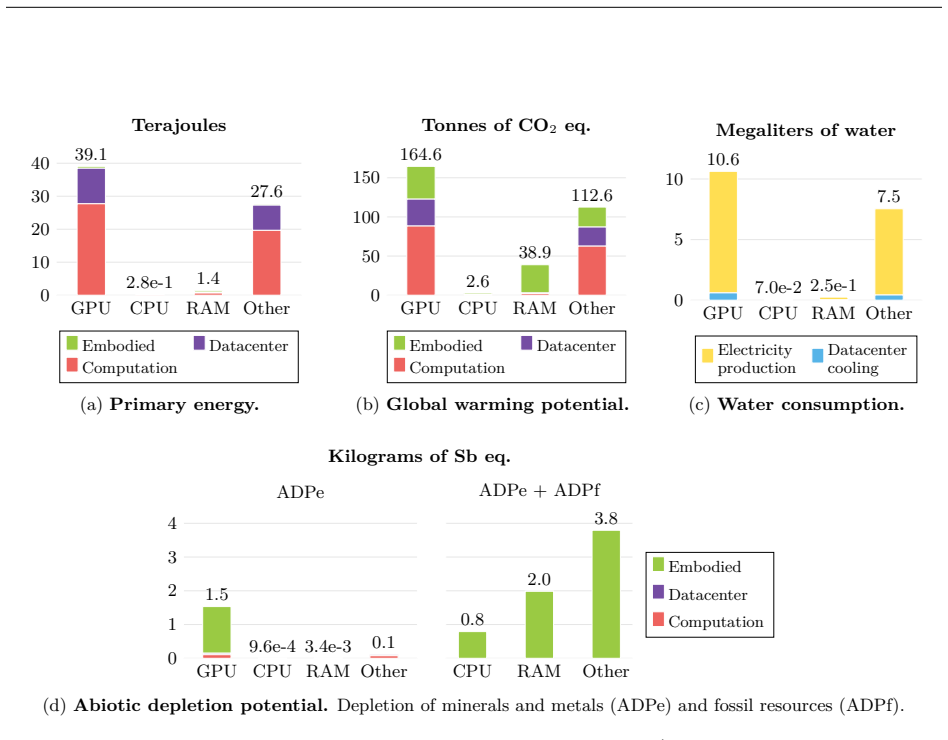
read the original abstract
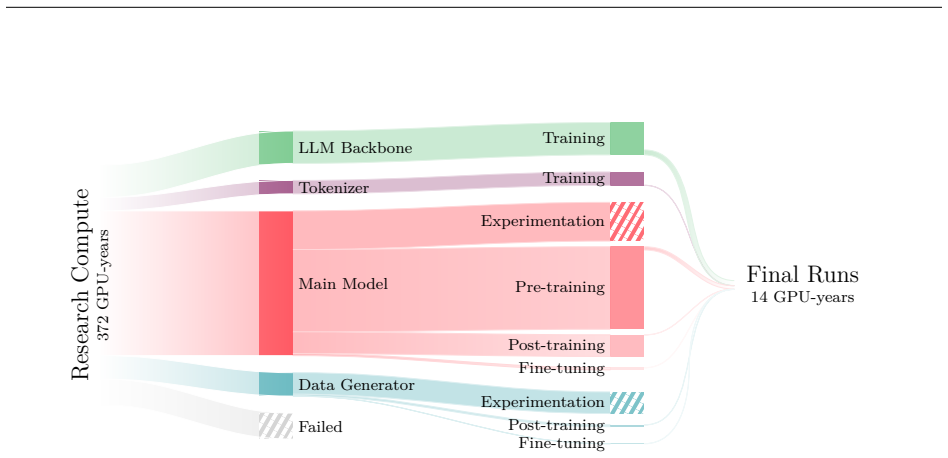
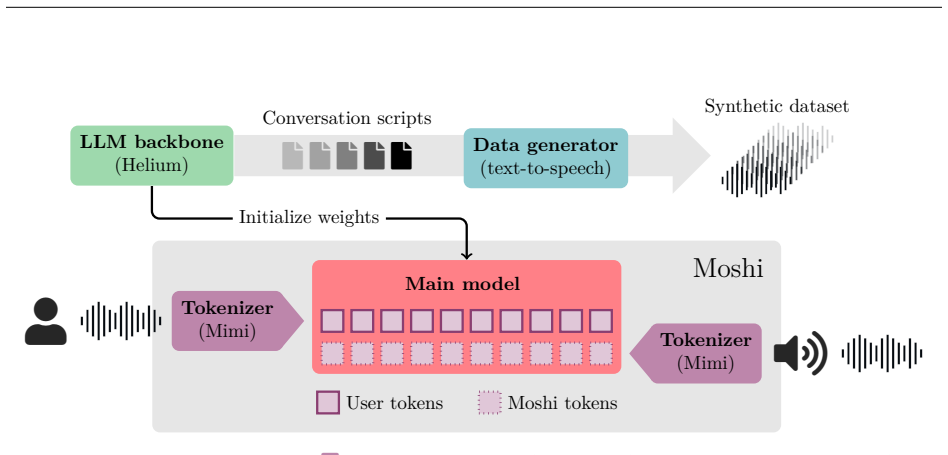
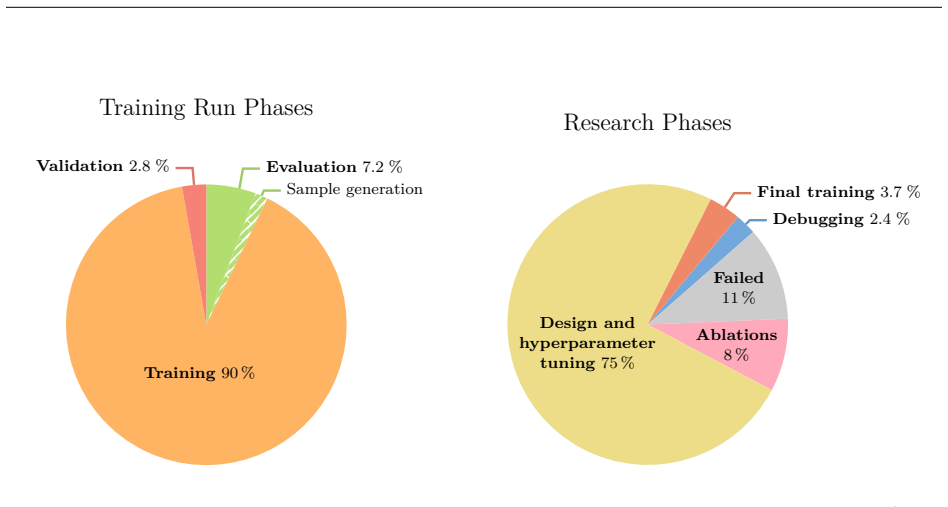
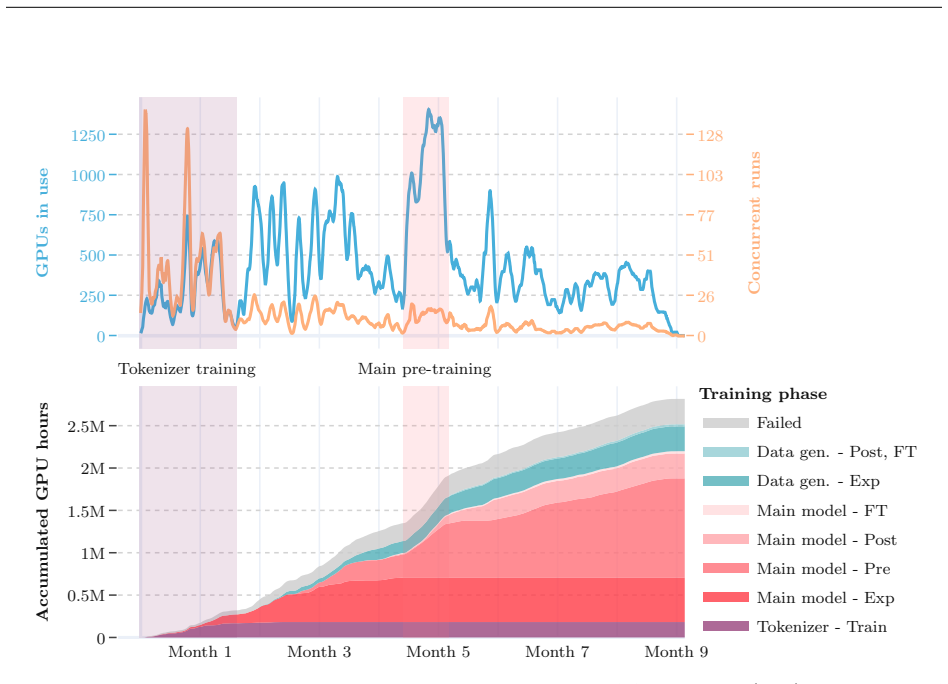
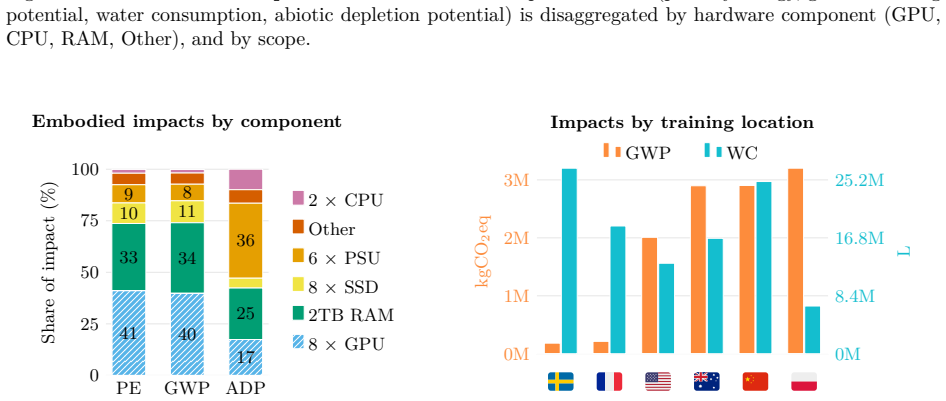
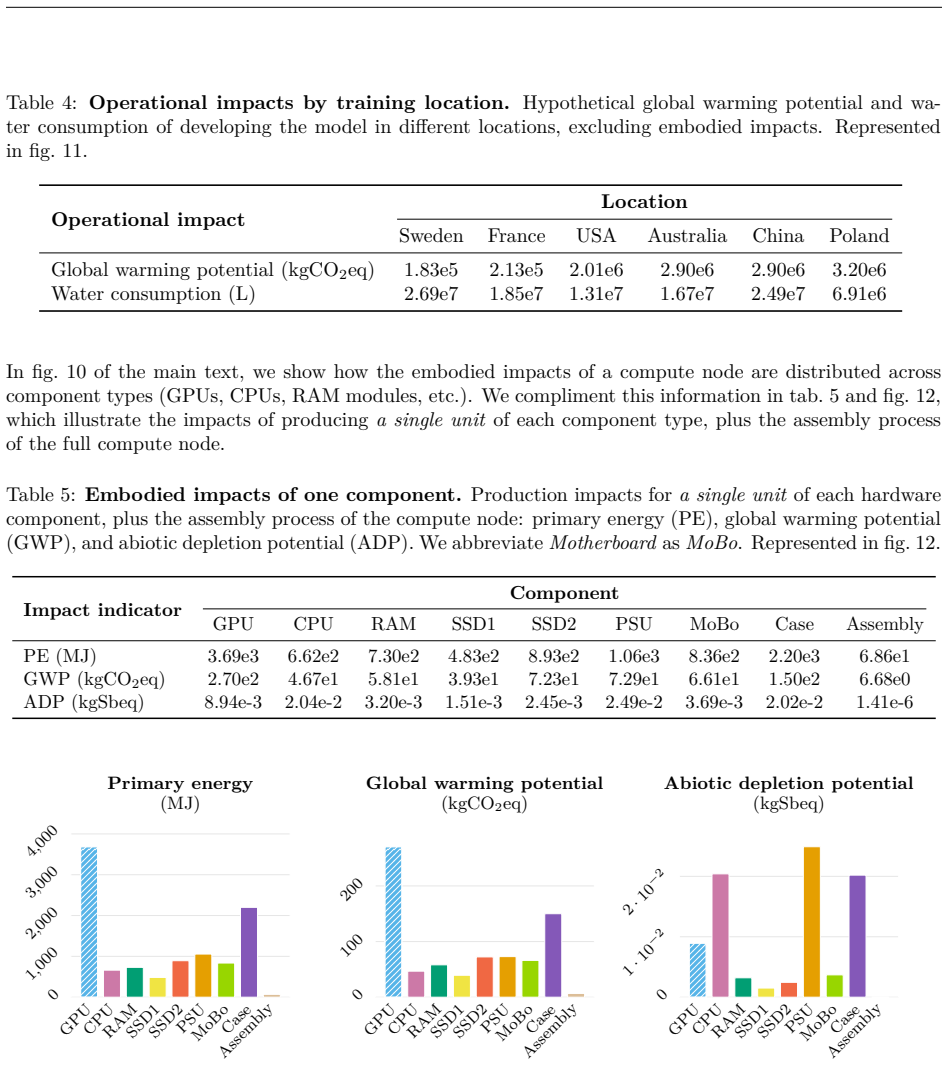
New multi-modal large language models (MLLMs) are continuously being trained and deployed, following rapid development cycles. This generative AI frenzy is driving steady increases in energy consumption, greenhouse gas emissions, and a plethora of other environmental impacts linked to datacenter construction and hardware manufacturing. Mitigating the environmental consequences of GenAI remains challenging due to an overall lack of transparency by the main actors in the field. Even when the environmental impacts of specific models are mentioned, they are typically restricted to the carbon footprint of the final training run, omitting the research and development stages. In this work, we explore the impact of GenAI research through a fine-grained analysis of the compute spent to create Moshi, a 7B-parameter speech-text foundation model for real-time dialogue developed by Kyutai, a leading privately funded open science AI lab. For the first time, our study dives into the anatomy of compute-intensive MLLM research, quantifying the GPU-time invested in specific model components and training phases, as well as early experimental stages, failed training runs, debugging, and ablation studies. Additionally, we assess the environmental impacts of creating Moshi from beginning to end using a life cycle assessment methodology: we quantify energy and water consumption, greenhouse gas emissions, and mineral resource depletion associated with the production and use of datacenter hardware. Our detailed analysis allows us to provide actionable guidelines to reduce compute usage and environmental impacts of MLLM research, paving the way for more sustainable AI research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to deliver the first detailed breakdown of GPU-hours across all stages of developing the 7B-parameter Moshi MLLM (including component-specific training, early experiments, failed runs, debugging, and ablations) together with an end-to-end life-cycle assessment quantifying energy use, water consumption, GHG emissions, and mineral resource depletion attributable to datacenter hardware production and operation.
Significance. If the underlying logs and LCA parameters prove accurate, the work supplies rare empirical transparency into the full R&D footprint of a modern multimodal foundation model, a gap that standard final-training-only reports leave unaddressed. The explicit inclusion of failed runs and ablations constitutes a concrete strength that could support more realistic sustainability guidelines.
major comments (2)
- [Methods (compute accounting)] The central quantification of GPU-time for failed runs, debugging, and ablation studies rests entirely on self-reported logs supplied by the private Kyutai lab. No independent audit, raw-log release (even anonymized), or cross-validation against public hardware-utilization records is described; this directly undermines the reliability of both the fine-grained component breakdown and the aggregate environmental totals.
- [LCA methodology] The life-cycle assessment adopts emission factors, system boundaries, and hardware-production inventories without accompanying sensitivity analysis or uncertainty propagation. Because water consumption and mineral depletion are reported as headline results, the absence of such tests leaves the dominant-impact claim untested against plausible variations in electricity mix or supply-chain data.
minor comments (2)
- [Figures and Tables] Figure captions and table footnotes should explicitly state the temporal scope covered by the logs (e.g., start and end dates of data collection) to allow readers to judge completeness.
- [Discussion] The abstract states that 'actionable guidelines' are provided; the main text should map each guideline to a specific quantitative finding rather than leaving the link implicit.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the value of including failed runs and ablations in the environmental assessment. We address the two major comments point by point below.
read point-by-point responses
-
Referee: [Methods (compute accounting)] The central quantification of GPU-time for failed runs, debugging, and ablation studies rests entirely on self-reported logs supplied by the private Kyutai lab. No independent audit, raw-log release (even anonymized), or cross-validation against public hardware-utilization records is described; this directly undermines the reliability of both the fine-grained component breakdown and the aggregate environmental totals.
Authors: We acknowledge that the GPU-hour accounting is based on internal logs from Kyutai. As a private lab, independent audit and raw-log release are not feasible due to confidentiality and proprietary constraints. The Methods section details the logging process via Slurm scheduler records and internal GPU monitoring tools. Aggregate totals are cross-checked against public benchmarks in the discussion, but component-level validation against external records is not possible. We will add an expanded limitations subsection explicitly addressing the self-reported nature and associated uncertainties. revision: partial
-
Referee: [LCA methodology] The life-cycle assessment adopts emission factors, system boundaries, and hardware-production inventories without accompanying sensitivity analysis or uncertainty propagation. Because water consumption and mineral depletion are reported as headline results, the absence of such tests leaves the dominant-impact claim untested against plausible variations in electricity mix or supply-chain data.
Authors: We agree that sensitivity analysis and uncertainty quantification would strengthen the LCA results. The revised manuscript will include a new subsection with sensitivity tests on electricity mix, emission factors, and hardware inventories, plus Monte Carlo-based uncertainty propagation for energy, water, GHG, and mineral depletion impacts. revision: yes
- Independent audit or release of raw compute logs from the private Kyutai lab due to confidentiality and proprietary restrictions.
Circularity Check
Empirical measurement study with no derivation chain or self-referential equations
full rationale
The paper performs a life-cycle assessment and GPU-hour accounting based on logs and hardware specifications supplied by the Kyutai lab. No equations, fitted parameters, or predictions are defined in terms of the reported impacts themselves; the central outputs are direct tallies of energy, water, emissions, and resource use drawn from external data sources. No self-citation load-bearing steps, uniqueness theorems, or ansatz smuggling appear in the provided text. The analysis is therefore self-contained as an empirical exercise rather than a closed mathematical derivation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Life-cycle assessment methodology with chosen system boundaries and emission factors accurately reflects the dominant environmental impacts of datacenter hardware production and use.
Reference graph
Works this paper leans on
-
[1]
Jacob Morrison, Clara Na, Jared Fernandez, Tim Dettmers, Emma Strubell, and Jesse Dodge
doi: 10.1109/ICT4S64576.2024.00031. Jacob Morrison, Clara Na, Jared Fernandez, Tim Dettmers, Emma Strubell, and Jesse Dodge. Holistically evaluating the environmental impact of creating language models, 2025. NVIDIA. Introduction to NVIDIA DGX H100/H200 systems - NVIDIA DGX H100/H200 user guide. https://docs.nvidia.com/dgx/dgxh100-user-guide/introduction-...
-
[2]
21 Emma Strubell, Ananya Ganesh, and Andrew McCallum
doi: 10.3233/APC200091. 21 Emma Strubell, Ananya Ganesh, and Andrew McCallum. Energy and policy considerations for deep learning in NLP. In Anna Korhonen, David Traum, and Lluís Màrquez (eds.),Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pp. 3645–3650, Florence, Italy, 2019. Association for Computational Linguis...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.