Geoparsing: Diagram Parsing for Plane and Solid Geometry with a Unified Formal Language
Pith reviewed 2026-05-10 15:23 UTC · model grok-4.3
The pith
Parsed formal descriptions from geometry diagrams serve as cognitive scaffolds that boost multimodal language models on reasoning tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A unified formal language that integrates plane and solid geometry structures and semantic relations allows diagrams to be converted into accurate, verifiable textual representations; when these representations are supplied to multimodal large language models, they function as cognitive scaffolds that raise performance on geometry reasoning tasks.
What carries the argument
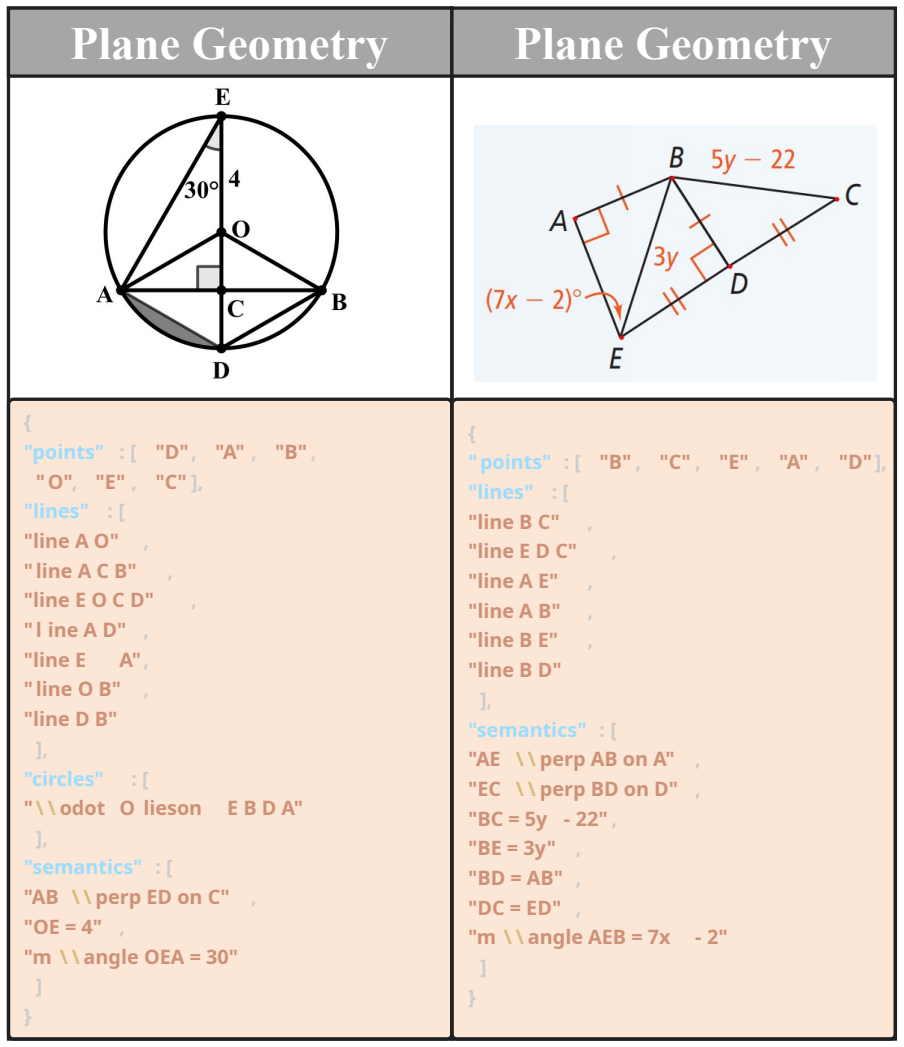
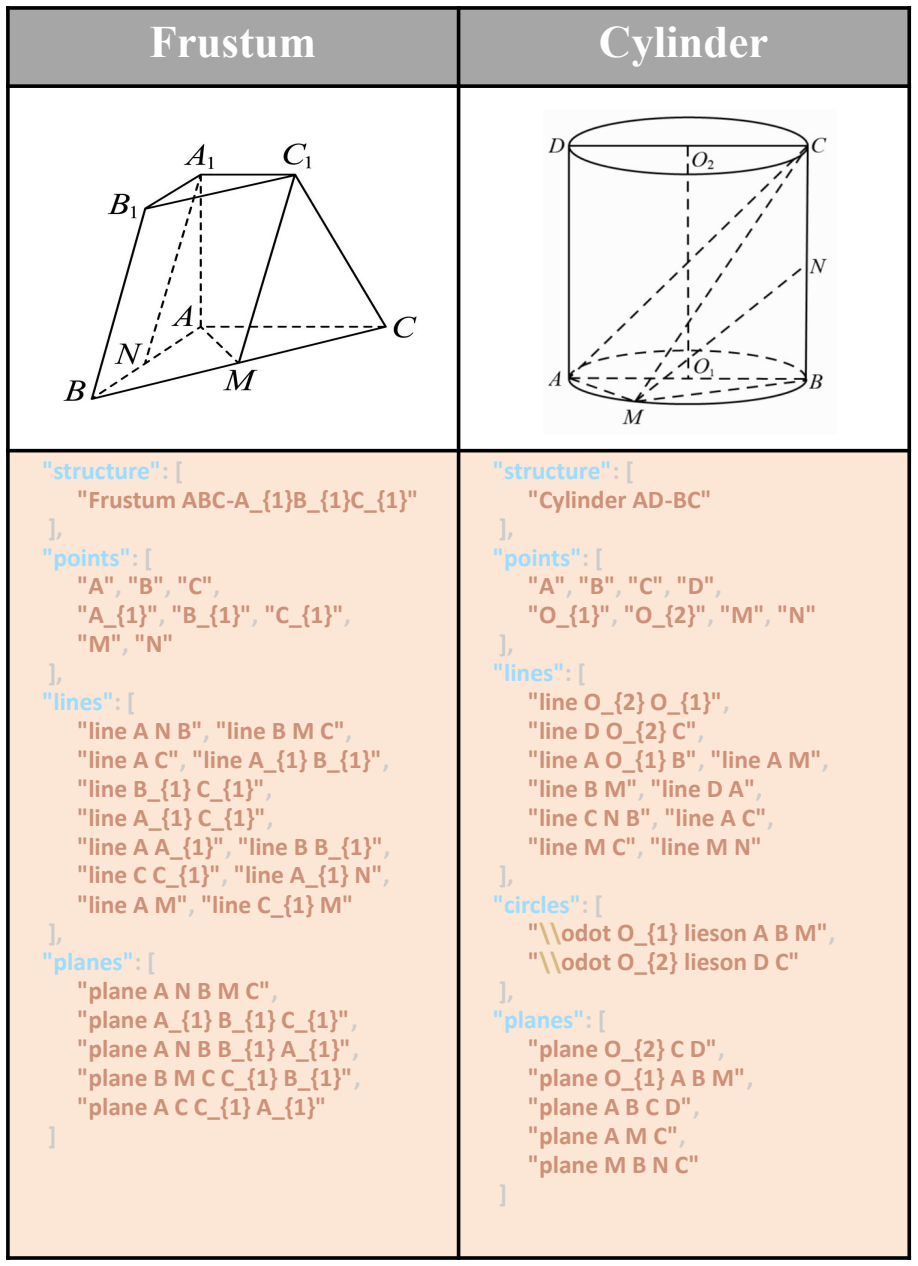
The unified formal language that comprehensively covers geometric structures and semantic relations in both plane and solid geometry.
If this is right
- The same language and training approach yields state-of-the-art accuracy when converting diagrams into formal descriptions.
- Supplying the parsed descriptions to multimodal models measurably raises their accuracy on geometry reasoning problems.
- A single training pipeline handles both two-dimensional plane figures and three-dimensional solid objects.
- Verifiable rewards during reinforcement learning enforce both syntactic validity and geometric consistency.
Where Pith is reading between the lines
- The same scaffold idea might be tested on other visual domains that combine diagrams with logical deduction, such as mechanics or circuit analysis.
- Measuring how often the parser produces descriptions that remain consistent when diagrams are rotated or projected would test the language's spatial completeness.
- The formal output could be fed directly into symbolic theorem provers to check whether the model-generated steps are logically sound.
Load-bearing premise
The proposed formal language fully captures every geometric structure and relation that appears in plane and solid diagrams without loss or ambiguity.
What would settle it
A collection of previously unseen geometry diagrams for which the model's output descriptions either mismatch expert annotations or produce no measurable gain in multimodal model accuracy on corresponding reasoning questions.
Figures

















read the original abstract
Multimodal Large Language Models (MLLMs) have achieved remarkable progress but continue to struggle with geometric reasoning, primarily due to the perception bottleneck regarding fine-grained visual elements. While formal languages have aided plane geometry understanding, solid geometry which requires spatial understanding remains largely unexplored. In this paper, we address this challenge by designing a unified formal language that integrates plane and solid geometry, comprehensively covering geometric structures and semantic relations. We construct GDP-29K, a large-scale dataset comprising 20k plane and 9k solid geometry samples collected from diverse real-world sources, each paired with its ground-truth formal description. To ensure syntactic correctness and geometric consistency, we propose a training paradigm that combines Supervised Fine-Tuning with Reinforcement Learning via Verifiable Rewards. Experiments show that our approach achieves state-of-the-art parsing performance. Furthermore, we demonstrate that our parsed formal descriptions serve as a critical cognitive scaffold, significantly boosting MLLMs' capabilities for downstream geometry reasoning tasks. Our data and code are available at Geoparsing.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce a unified formal language integrating plane and solid geometry, construct the GDP-29K dataset (20k plane + 9k solid samples with ground-truth formal descriptions collected from real-world sources), train via supervised fine-tuning combined with reinforcement learning using verifiable rewards to ensure syntactic and geometric correctness, achieve state-of-the-art parsing performance, and demonstrate that the resulting parsed formal descriptions serve as a critical cognitive scaffold that significantly boosts MLLM performance on downstream geometry reasoning tasks.
Significance. If the central claims hold, this would represent a meaningful advance by extending formal-language approaches to underexplored solid geometry, supplying a large-scale public dataset and code for reproducibility, and providing an empirical pathway to improve MLLM geometric reasoning through structured intermediate representations. The data and code release is an explicit strength that supports verification and extension by the community.
major comments (3)
- [Abstract] Abstract: the claim that parsed formal descriptions 'significantly boosting MLLMs' capabilities for downstream geometry reasoning tasks' is presented without any quantitative metrics, baselines, ablation results, or error analysis, which is load-bearing for the central assertion that the formal language functions as a cognitive scaffold rather than incidental structured text.
- [Unified formal language] Unified formal language section: the assertion that the language 'comprehensively covering geometric structures and semantic relations' in both plane and solid geometry lacks a grammar specification, completeness argument, or explicit treatment of edge cases such as hidden surfaces, projective relations, or non-convex intersections; without this, downstream gains cannot be reliably attributed to the scaffold.
- [Reinforcement Learning via Verifiable Rewards] Reinforcement Learning via Verifiable Rewards section: the description of verifiable rewards is insufficient to confirm that they enforce geometric (as opposed to purely syntactic) correctness, particularly for solid-geometry configurations; this directly affects the soundness of the training paradigm and the attribution of consistency claims.
minor comments (1)
- [Dataset] Dataset construction paragraph: additional detail on annotation protocols and inter-annotator agreement for the 9k solid-geometry samples would improve transparency without altering the core claims.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that parsed formal descriptions 'significantly boosting MLLMs' capabilities for downstream geometry reasoning tasks' is presented without any quantitative metrics, baselines, ablation results, or error analysis, which is load-bearing for the central assertion that the formal language functions as a cognitive scaffold rather than incidental structured text.
Authors: We acknowledge that the abstract presents the downstream benefit at a high level without specific numbers. The full manuscript reports quantitative results in the experiments section, including accuracy gains on geometry reasoning benchmarks when using parsed formal descriptions versus direct image input, along with baselines and ablations. We will revise the abstract to include key metrics (e.g., relative improvement percentages), a brief reference to the evaluation protocol, and mention of the cognitive-scaffold interpretation supported by those results. revision: yes
-
Referee: [Unified formal language] Unified formal language section: the assertion that the language 'comprehensively covering geometric structures and semantic relations' in both plane and solid geometry lacks a grammar specification, completeness argument, or explicit treatment of edge cases such as hidden surfaces, projective relations, or non-convex intersections; without this, downstream gains cannot be reliably attributed to the scaffold.
Authors: Section 3 defines the unified formal language with syntax and semantics for plane and solid primitives and relations; a BNF grammar appears in the appendix. Coverage draws from standard high-school geometry curricula, with hidden surfaces addressed via visibility predicates and non-convex cases via explicit set operations. We agree a dedicated completeness argument and expanded edge-case discussion (including projective relations) are valuable and will add a subsection on language scope, limitations, and justification for the chosen primitives in the revision. revision: partial
-
Referee: [Reinforcement Learning via Verifiable Rewards] Reinforcement Learning via Verifiable Rewards section: the description of verifiable rewards is insufficient to confirm that they enforce geometric (as opposed to purely syntactic) correctness, particularly for solid-geometry configurations; this directly affects the soundness of the training paradigm and the attribution of consistency claims.
Authors: Section 4.3 specifies the reward structure: a syntactic parser check plus a geometric verifier that evaluates properties such as distance/angle constraints, volume consistency, and 3D intersection validity using rule-based checks on the diagram. We will expand the section with pseudocode for the geometric verifier, concrete solid-geometry examples, and an ablation isolating the geometric reward's contribution to consistency. This will make the distinction between syntactic and geometric enforcement explicit. revision: yes
Circularity Check
No significant circularity; empirical pipeline relies on external data and verifiable rewards
full rationale
The paper's derivation chain consists of designing a unified formal language, collecting an external GDP-29K dataset from real-world sources, applying SFT+RL with verifiable rewards for syntactic and geometric correctness, and reporting experimental SOTA parsing performance plus downstream MLLM boosts. No quoted equations, fitted parameters renamed as predictions, or self-citation chains reduce any central claim to its own inputs by construction. The strongest claim (formal descriptions as cognitive scaffold) is presented as an empirical outcome on held-out tasks rather than a definitional or self-referential result.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A single formal language can comprehensively represent geometric structures and semantic relations for both plane and solid geometry
invented entities (1)
-
Unified formal language for plane and solid geometry
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Available at: https://openai.com/index/ gpt-5-system-card/. Peter Petersen. 2006.Riemannian geometry, volume
work page 2006
-
[2]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Springer. Runqi Qiao, Qiuna Tan, Guanting Dong, MinhuiWu MinhuiWu, Chong Sun, Xiaoshuai Song, Jiapeng Wang, Zhuoma GongQue, Shanglin Lei, Yifan Zhang, and 1 others. 2025. We-math: Does your large multi- modal model achieve human-like mathematical rea- soning? InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Vol- u...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Measuring multimodal mathematical reason- ing with math-vision dataset.Advances in Neural Information Processing Systems, 37:95095–95169. Peijie Wang, Zhong-Zhi Li, Fei Yin, Dekang Ran, and Cheng-Lin Liu. 2025a. Mv-math: Evaluating mul- timodal math reasoning in multi-visual contexts. In Proceedings of the Computer Vision and Pattern Recognition Conferenc...
-
[4]
The primary focus was on fixing ver- tex ordering and ensuring all geometric con- straints (e.g., parallelism) were captured. • Solid Geometry:Since MLLMs often fail to perceive 3D depth, annotators manually identified all faces, edges, and spatial rela- tions from scratch, following the hierarchi- cal structure of our formal language
-
[5]
Verification Stage:A different student from the team acted as a peer reviewer for each an- notated sample. They cross-checked the for- mal description against the original diagram to identify any missing primitives or incor- rect semantic tags. Any discrepancies were returned to the original annotator for revision
-
[6]
Final Acceptance Stage:Our expert leads (authors of this study) performed a final audit on the verified samples. This stage focused on ensuring the logical consistency of the for- mal language and the accuracy of complex 3D structures (e.g., non-trivial frustums and spheroids). Only samples with 100% consen- sus were moved to the final pool. B.3 Redundanc...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.