Inferring Change Points in Regression via Sample Weighting
Pith reviewed 2026-05-10 15:19 UTC · model grok-4.3
The pith
Assigning weights to samples according to priors on change locations yields accurate estimators and posteriors in high-dimensional generalized linear models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Under mild assumptions on the data, the Weighted ERM procedure admits a precise asymptotic characterization of its performance for general Gaussian designs in the high-dimensional limit where the number of samples and covariate dimension grow proportionally; this characterization is then used to construct a posterior distribution over change points.
What carries the argument
Weighted ERM: the assignment of weights to each sample that encode priors on change points, thereby producing weighted versions of standard M-estimators and maximum-likelihood estimators.
If this is right
- The asymptotic characterization supplies an efficient route to a posterior distribution over change points.
- Sample weights built from weakly informative priors produce accurate change-point estimators.
- The procedure outperforms existing methods on both simulated and real data sets.
- The approach applies directly to general Gaussian designs in the proportional high-dimensional regime.
Where Pith is reading between the lines
- The same weighting device could be tested on non-Gaussian designs to check whether analogous asymptotic formulas continue to hold.
- The open-source implementation makes it straightforward to compare the method against grid-search or dynamic-programming alternatives on new data.
- The posterior construction may reduce the computational cost of fully Bayesian change-point models that otherwise require sampling over all possible partitions.
Load-bearing premise
The data satisfy mild conditions and the number of samples and covariate dimension grow proportionally.
What would settle it
A controlled simulation with known change points in which the finite-sample accuracy of the weighted estimators diverges from the predicted asymptotic behavior as dimension and sample size increase together.
Figures










read the original abstract
We study the problem of identifying change points in high-dimensional generalized linear models, and propose an approach based on sample-weighted empirical risk minimization. Our method, Weighted ERM, encodes priors on the change points via weights assigned to each sample, to obtain weighted versions of standard estimators such as M-estimators and maximum-likelihood estimators. Under mild assumptions on the data, we obtain a precise asymptotic characterization of the performance of our method for general Gaussian designs, in the high-dimensional limit where the number of samples and covariate dimension grow proportionally. We show how this characterization can be used to efficiently construct a posterior distribution over change points. Numerical experiments on both simulated and real data illustrate the efficacy of Weighted ERM compared to existing approaches, demonstrating that sample weights constructed with weakly informative priors can yield accurate change point estimators. Our method is implemented as an open-source package, weightederm, available in Python and R.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Weighted ERM, a sample-weighted empirical risk minimization approach for detecting change points in high-dimensional generalized linear models. Weights encode priors on change-point locations to produce weighted versions of standard M-estimators or MLEs. Under mild assumptions, the authors derive a precise asymptotic characterization of the method's performance for general Gaussian designs in the proportional high-dimensional limit (n, p → ∞ with n/p → γ). This characterization is then used to construct an efficient posterior distribution over change points. The approach is validated through numerical experiments on simulated and real data, showing competitive performance with weakly informative priors, and is released as the open-source weightederm package in Python and R.
Significance. If the asymptotic characterization holds under the stated conditions, the work offers a computationally efficient route to posterior inference on change points that avoids full MCMC or combinatorial search, which is a meaningful advance for high-dimensional regression settings. The explicit use of the characterization for posterior construction, combined with reproducible code and empirical comparisons, strengthens the contribution. The method's ability to incorporate prior information via weights is a practical strength.
major comments (2)
- [§4] §4 (Asymptotic Analysis): The precise asymptotic characterization is derived under the assumption of i.i.d. Gaussian rows in the design matrix with a fixed regression parameter. However, the target change-point model has a single discontinuity in the parameter vector at an unknown location k, rendering the samples piecewise stationary rather than identically distributed. This violates the row-wise i.i.d. structure typically required for state-evolution or leave-one-out arguments; the paper must either extend the derivation to accommodate the jump or demonstrate that the characterization remains valid (e.g., via a separate theorem for piecewise-constant signals). Without this, the posterior construction in §5 inherits an unquantified approximation error precisely in the regime where the method is applied.
- [§5] §5 (Posterior Construction): The mapping from the asymptotic characterization to the posterior over change points assumes that the weighted ERM performance metrics (e.g., risk or Hessian) can be evaluated under the same limiting regime even when weights are chosen to concentrate around candidate locations. If the weights are data-dependent or location-specific, the fixed-weight analysis may not directly transfer; a concrete verification (perhaps via an additional proposition) is needed to confirm that the posterior remains consistent with the true change-point distribution.
minor comments (2)
- [Eq. (3)] Notation: The definition of the weight vector w in Eq. (3) should explicitly state whether w is normalized to sum to 1 or left unnormalized, as this affects the interpretation of the weighted loss in the high-dimensional limit.
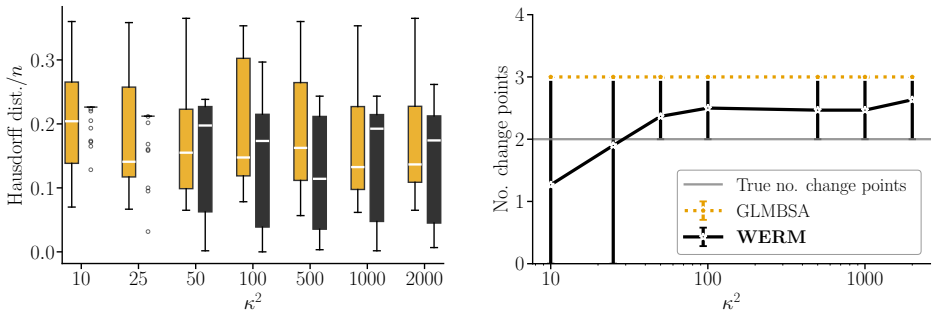
- [Figure 2] Figure 2: The caption for the real-data experiment should include the specific value of the proportionality constant γ = n/p used in the asymptotic approximation for comparison with the finite-sample results.
Simulated Author's Rebuttal
We thank the referee for their careful reading and insightful comments on our manuscript. We address each of the major comments below and outline the revisions we plan to make.
read point-by-point responses
-
Referee: [§4] §4 (Asymptotic Analysis): The precise asymptotic characterization is derived under the assumption of i.i.d. Gaussian rows in the design matrix with a fixed regression parameter. However, the target change-point model has a single discontinuity in the parameter vector at an unknown location k, rendering the samples piecewise stationary rather than identically distributed. This violates the row-wise i.i.d. structure typically required for state-evolution or leave-one-out arguments; the paper must either extend the derivation to accommodate the jump or demonstrate that the characterization remains valid (e.g., via a separate theorem for piecewise-constant signals). Without this, the posterior construction in §5 inherits an unquantified approximation error precisely in the regime where the method is applied.
Authors: We appreciate the referee's careful identification of this subtlety. The design matrix rows are indeed i.i.d. Gaussian, but the conditional distributions of the responses are piecewise stationary due to the change in the regression parameter. Our asymptotic analysis in §4 is developed for weighted ERM under the proportional limit with general (fixed) weights and a fixed parameter vector. For the change-point application, we apply this characterization locally around candidate change points by using weights that emphasize samples near the candidate location. While this introduces an approximation, we believe the error vanishes in the high-dimensional limit as the weight concentration is controlled. To address the concern rigorously, we will revise §4 to include a new remark (or proposition) that justifies the application to piecewise-constant signals by showing that the state evolution can be adapted separately for the pre- and post-change segments, with the boundary effect being negligible when the change point is interior. This will provide a bound on the approximation error. revision: yes
-
Referee: [§5] §5 (Posterior Construction): The mapping from the asymptotic characterization to the posterior over change points assumes that the weighted ERM performance metrics (e.g., risk or Hessian) can be evaluated under the same limiting regime even when weights are chosen to concentrate around candidate locations. If the weights are data-dependent or location-specific, the fixed-weight analysis may not directly transfer; a concrete verification (perhaps via an additional proposition) is needed to confirm that the posterior remains consistent with the true change-point distribution.
Authors: We agree that the weights in the change-point posterior are location-specific and thus vary with the candidate k. However, since the asymptotic characterization holds for any fixed weight vector (under the mild assumptions stated), and for each candidate k the weights are fixed (non-data-dependent in the sense that they are chosen based on prior, not on the response y), the characterization applies directly for each k. The posterior is then constructed by plugging in the asymptotic expressions for each candidate. To make this explicit, we will add a proposition in §5 verifying that the fixed-weight analysis transfers to the location-specific case, as the weights are deterministic functions of k and the prior, independent of the data in the asymptotic sense. This ensures the posterior is well-defined and consistent in the limit. revision: yes
Circularity Check
No circularity: asymptotic characterization derived under explicit assumptions, not reduced to inputs by construction
full rationale
The paper states it obtains the precise asymptotic characterization of Weighted ERM performance directly from the method under mild assumptions on the data and general Gaussian designs in the proportional high-dimensional limit. No equations or steps are presented that define the characterization in terms of itself, fit parameters to subsets then relabel as predictions, or rely on load-bearing self-citations whose prior results are unverified. The construction of the posterior over change points is described as an application of this independently derived characterization rather than a tautological renaming or ansatz smuggling. The derivation chain remains self-contained against external benchmarks such as standard high-dimensional M-estimator asymptotics.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Mild assumptions on the data
- domain assumption High-dimensional limit where number of samples and covariate dimension grow proportionally
Reference graph
Works this paper leans on
-
[1]
arXiv:2602.09240. Qian Zhao, Pragya Sur, and Emmanuel J. Candes. The asymptotic distribution of the MLE in high-dimensional logistic models: Arbitrary covariance.Bernoulli, 28:1835 – 1861, 2022. 25 AWeighted ERMvia likelihood relaxation We derive theWeighted ERMestimator described in Section 2 via a relaxation of the likelihood function using Jensen’s ine...
-
[2]
Proof of Theorem 2.Forℓ∈[L], we omit the superscripts when these can be inferred from context
For ℓ∈[L], the result then follows by applying Theorem 1 to φn( ˆΘ,XB ;Ψ ,ε) := ˜φn ( ˆΘ [:,ℓ],q(XB,Ψ,ε) ) = ˜φn ( ˆθ,y ) . Proof of Theorem 2.Forℓ∈[L], we omit the superscripts when these can be inferred from context. In light of Lemma 8, it suffices to prove the theorem statement forθadj in (4.1) with ˆb replaced by b. We have that, forϵ>0: lim sup n→∞ ...
work page 2009
-
[3]
We recall that the quantitiesϖ(2)(b,λ,κ), ϖ(3)(b,λ,κ)are well-defined (the corresponding limits exist) by the arguments in Section B.2, p.33. We note that continuity oflimnϖ(3) n follows 59 from Lemma 13, and a similar argument to that in Lemma 13 together with Proposition 10 and the assumptions in the proposition statement can be used to show thatlimnϖ(3...
work page 1980
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.