Observing the unobserved confounding through its effects: toward randomized trial-like estimates from real-world survival data
Pith reviewed 2026-05-10 15:12 UTC · model grok-4.3
The pith
Inferring and balancing a latent prognostic factor from survival discrepancies reduces unobserved confounding to produce hazard ratio estimates closer to randomized trials.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that discrepancies in restricted mean survival time between patients with similar observed covariates, identical treatment, and different outcomes can be aggregated into a single latent prognostic factor U; balancing this U removes the bulk of unobserved confounding so that subsequent hazard ratio estimates align more closely with randomized trial benchmarks.
What carries the argument
The latent prognostic factor U, constructed by aggregating restricted mean survival time discrepancies among otherwise similar patients who receive the same treatment yet experience divergent outcomes; this U acts as a proxy for the combined effect of unmeasured confounders, allowing standard balancing methods to reduce bias.
If this is right
- Hazard ratio estimates from observational survival data can be brought into closer agreement with randomized trial results across multiple cohorts.
- In multicenter observational data, balancing U within centers reduces dispersion in treatment effect estimates.
- Directly balancing populations across centers using observed covariates plus U narrows survival differences in most comparisons.
- In randomized trial data where confounding is absent by design, the inferred U is already balanced and adjustment changes estimates only minimally.
Where Pith is reading between the lines
- The same discrepancy-based inference of a latent factor could be tested on non-survival outcomes if analogous summary measures exist.
- If U captures most unobserved confounding, the framework may support causal claims in settings where randomized trials cannot be run.
- Combining this latent-factor balancing with other debiasing tools such as instrumental variables might further reduce residual bias.
Load-bearing premise
That the effects of many unmeasured factors can be summarized in one latent variable U inferred only from survival time differences among patients who look identical on observed variables.
What would settle it
Apply the method to a new observational cohort with a known randomized trial benchmark; if balancing the inferred U fails to reduce absolute log-hazard-ratio error or worsens agreement with the trial result, the central claim does not hold.
Figures





















read the original abstract
Background: Randomized controlled trials (RCTs) are costly, time-consuming, and often infeasible, while treatment-effect estimation from observational data is limited by unobserved confounding. Methods: We developed a three-step framework to address unobserved confounding in observational survival data. First, we infer a latent prognostic factor (U) from restricted mean survival time (RMST) discrepancies between patients with similar observed factors, the same treatment, and divergent outcomes, leveraging the idea that the aggregate effect of unmeasured factors can be inferred even if individual factors cannot. Second, we balance U with observed baseline covariates using prognostic matching, entropy balancing, or inverse probability of treatment weighting. Third, we apply multivariable survival analysis to estimate hazard ratios (HRs). We evaluated the framework in three observational cohorts with RCT benchmarks, two RCT cohorts, and six multicenter observational cohorts. Results: In three observational cohorts (nine comparisons), balancing U improved agreement with trial HRs in all cases; in the strongest settings, it reduced absolute log-HR error by approximately ten-fold versus using observed covariates alone (mean reduction 0.344; p=0.001). In two RCT cohorts, U was balanced across arms (most SMDs <0.1) and adjustment had minimal impact on log-HRs (mean absolute change 0.08). Across six multicenter cohorts, balancing U within centers reduced cross-center dispersion in chemotherapy log-HR estimates (mean reduction 0.147; p=0.016); when populations were directly balanced across centers to account for case-mix differences, cross-center survival differences were narrowed in 75%-100% of comparisons. Conclusions: Inferring and balancing a latent prognostic signal may reduce unobserved confounding and improve treatment-effect estimation from real-world data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a three-step method for observational survival data: (1) infer a latent prognostic factor U from within-arm RMST discrepancies among patients with similar observed covariates but divergent outcomes; (2) balance U together with observed covariates via matching, entropy balancing, or IPTW; (3) fit a multivariable Cox model to obtain adjusted HRs. The framework is tested in three observational cohorts (nine treatment comparisons) against RCT benchmarks, two RCT cohorts, and six multicenter observational cohorts, with reported improvements in agreement with trial HRs and reduced cross-center dispersion.
Significance. If the procedure isolates unobserved confounding without inducing bias from outcome-derived adjustment, the approach could enable more reliable treatment-effect estimates from real-world survival data where RCTs are infeasible. The empirical results—consistent directional improvement across all nine comparisons and a mean absolute log-HR error reduction of 0.344 (p=0.001) in the strongest settings—are quantitatively striking and would be of substantial practical interest if the method is shown to be non-circular.
major comments (3)
- [Methods (U inference step)] Methods, first step (U construction): U is defined directly from the discrepancy between observed RMST and the RMST predicted from observed covariates within the same treatment arm. Because this uses the endpoint data that are subsequently used to estimate the HR, the procedure risks circularity; the same survival outcomes inform both the adjustment variable and the target estimand. A formal argument or simulation demonstrating that balancing this outcome-derived U recovers the true conditional HR (rather than attenuating toward the observed trial value) is needed.
- [Results (observational cohorts)] Results, observational-cohort comparisons: the claim of approximately ten-fold error reduction is load-bearing for the central contribution, yet the manuscript provides no details on how many patients are excluded when forming U, the sensitivity of results to the choice of RMST horizon, or the exact statistical test underlying p=0.001. These omissions prevent assessment of whether the reported improvement is robust or an artifact of modeling choices.
- [Methods (balancing and estimation)] Methods, balancing step: the paper states that U is balanced together with observed covariates, but does not specify whether the balancing weights or matches are computed using the full sample or within treatment arms, nor how the subsequent Cox model accounts for the fact that U is estimated rather than observed. Standard error propagation or bootstrap procedures for the final HR confidence intervals are not described.
minor comments (2)
- [Abstract and Results] The abstract and results sections refer to 'nine comparisons' and 'six multicenter cohorts' without a clear mapping to specific tables or supplementary tables; a CONSORT-style flow diagram or explicit table linking cohorts, treatments, and sample sizes would improve readability.
- [Methods] Notation for RMST and the prediction model used to compute discrepancies is introduced without an equation number; adding an explicit definition (e.g., Eq. (1) for predicted RMST) would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which have helped us strengthen the manuscript. We address each major comment point by point below. Revisions have been made to incorporate clarifications, additional analyses, and methodological details as outlined.
read point-by-point responses
-
Referee: Methods, first step (U construction): U is defined directly from the discrepancy between observed RMST and the RMST predicted from observed covariates within the same treatment arm. Because this uses the endpoint data that are subsequently used to estimate the HR, the procedure risks circularity; the same survival outcomes inform both the adjustment variable and the target estimand. A formal argument or simulation demonstrating that balancing this outcome-derived U recovers the true conditional HR (rather than attenuating toward the observed trial value) is needed.
Authors: We appreciate the referee's identification of this key methodological issue. While U is constructed from within-arm RMST residuals (capturing aggregate unobserved prognostic effects not explained by observed covariates), we agree that a rigorous demonstration against circularity is essential. In the revised manuscript, we have added a new simulation study (Section 4.4) in which data are generated with known true conditional HRs, observed covariates, and a latent U. We apply the full three-step procedure and demonstrate that the final adjusted HR recovers the true conditional treatment effect (bias < 5% across scenarios) rather than attenuating to the marginal HR. The simulation confirms that within-arm construction of U followed by cross-arm balancing isolates the confounding component without incorporating treatment-effect information into the adjustment. We have also added text clarifying that the RMST prediction step uses only within-arm data and does not involve treatment indicators. revision: yes
-
Referee: Results, observational-cohort comparisons: the claim of approximately ten-fold error reduction is load-bearing for the central contribution, yet the manuscript provides no details on how many patients are excluded when forming U, the sensitivity of results to the choice of RMST horizon, or the exact statistical test underlying p=0.001. These omissions prevent assessment of whether the reported improvement is robust or an artifact of modeling choices.
Authors: We apologize for these reporting gaps, which limit interpretability. In the revised Results and Supplementary Materials, we now report: (i) patient exclusion rates when constructing U (mean 3.2%, range 1.8–4.7% across the nine comparisons, due to insufficient within-arm matches for RMST estimation); (ii) sensitivity analyses repeating the primary comparison at RMST horizons of 1, 2, and 3 years, with consistent directional improvement and mean absolute log-HR error reductions of 0.31–0.37; (iii) that the p=0.001 derives from a paired t-test on the nine log-HR error differences (observed-covariates-only vs. U-balanced). These additions confirm the robustness of the reported improvement. revision: yes
-
Referee: Methods, balancing step: the paper states that U is balanced together with observed covariates, but does not specify whether the balancing weights or matches are computed using the full sample or within treatment arms, nor how the subsequent Cox model accounts for the fact that U is estimated rather than observed. Standard error propagation or bootstrap procedures for the final HR confidence intervals are not described.
Authors: We have substantially expanded the Methods section (now 2.3 and 2.4) to address these points. Balancing of U with observed covariates is performed on the full sample (not stratified within arms) using the estimated U as an additional balancing covariate; this is implemented identically for entropy balancing, IPTW, and prognostic matching. For the final Cox model, because U is estimated, we obtain standard errors and 95% CIs via bootstrap resampling with 500 replicates that re-estimate U in each replicate before re-balancing and re-fitting the Cox model. Pseudocode for the bootstrap procedure has been added to the Supplement, and we now report bootstrap-based intervals in all primary results. revision: yes
Circularity Check
No significant circularity; derivation remains self-contained against external benchmarks
full rationale
The three-step procedure infers U from within-arm RMST residuals after regressing on observed covariates, balances the resulting U, and then estimates HRs in a separate survival model. This chain does not reduce the final HR estimates to the input survival times by algebraic identity, nor does it rename a fitted residual as an independent prediction. No load-bearing uniqueness theorem or ansatz is imported via self-citation; the method is evaluated on held-out RCT benchmarks whose HRs are not used in constructing U. While the use of outcome-derived quantities raises separate causal-validity questions, the reported derivation does not collapse to its inputs by construction and therefore receives a zero circularity score.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The aggregate effect of unmeasured factors can be inferred from RMST discrepancies between patients with similar observed factors, the same treatment, and divergent outcomes.
invented entities (1)
-
Latent prognostic factor U
no independent evidence
Reference graph
Works this paper leans on
-
[1]
D. P. Nussbaum, C. N. Rushing, W. O. Lane, D. M. Car- dona, D. G. Kirsch, B. L. Peterson, D. G. Blazer, Preoper- ative or postoperative radiotherapy versus surgery alone for retroperitoneal sarcoma: a case-control, propensity score-matched analysis of a nationwide clinical oncology database, The Lancet Oncology 17 (7) (2016) 966–975
work page 2016
-
[2]
S. Bonvalot, A. Gronchi, C. Le Péchoux, C. J. Swal- low, D. Strauss, P. Meeus, F. Van Coevorden, S. Stoldt, E. Stoeckle, P. Rutkowski, et al., Preoperative radiother- apy plus surgery versus surgery alone for patients with primary retroperitoneal sarcoma (eortc-62092: Strass): a multicentre, open-label, randomised, phase 3 trial, The Lancet Oncology 21 (1...
work page 2020
-
[3]
D. Bertsimas, A. G. Koulouras, G. A. Margonis, The road to precision medicine, npj Digital Medicine 7 (1) (2024) 307
work page 2024
-
[4]
J. Hainmueller, Entropy balancing for causal effects: A multivariate reweighting method to produce balanced samples in observational studies, Political analysis 20 (1) (2012) 25–46
work page 2012
-
[5]
P. R. Rosenbaum, Model-based direct adjustment, Journal of the American statistical Association 82 (398) (1987) 387–394
work page 1987
-
[6]
P. K. Andersen, M. G. Hansen, J. P. Klein, Regression analysis of restricted mean survival time based on pseudo- observations, Lifetime data analysis 10 (4) (2004) 335– 350
work page 2004
-
[7]
R. P. DeMatteo, K. V . Ballman, C. R. Antonescu, R. G. Maki, P. W. Pisters, G. D. Demetri, M. E. Black- stein, C. D. Blanke, M. von Mehren, M. F. Bren- nan, et al., Adjuvant imatinib mesylate after resection of localised, primary gastrointestinal stromal tumour: a randomised, double-blind, placebo-controlled trial, The lancet 373 (9669) (2009) 1097–1104
work page 2009
-
[8]
D. Bertsimas, G. A. Margonis, S. Tang, A. Koulouras, C. R. Antonescu, M. F. Brennan, J. Martin-Broto, P. Rutkowski, G. Stasinos, J. Wang, et al., An inter- pretable ai model for recurrence prediction after surgery in gastrointestinal stromal tumour: an observational co- hort study, EClinicalMedicine 64 (2023)
work page 2023
-
[9]
J. S. Gold, M. Gönen, A. Gutiérrez, J. M. Broto, X. García-del Muro, T. C. Smyrk, R. G. Maki, S. Singer, M. F. Brennan, C. R. Antonescu, et al., Development and validation of a prognostic nomogram for recurrence- free survival after complete surgical resection of localised primary gastrointestinal stromal tumour: a retrospective analysis, The lancet oncol...
work page 2009
-
[10]
K. J. Kelly, S. S. Yoon, D. Kuk, L.-X. Qin, K. Duk- leska, K. K. Chang, Y .-L. Chen, T. F. Delaney, M. F. Brennan, S. Singer, Comparison of perioperative radiation therapy and surgery versus surgery alone in 204 patients with primary retroperitoneal sarcoma: a retrospective 2- institution study, Annals of surgery 262 (1) (2015) 156– 162
work page 2015
-
[11]
D. Bertsimas, A. Koulouras, H. Nagata, C. Gao, J. Mizu- sawa, Y . Kanemitsu, G. A. Margonis, The road to clinical trial emulation, Research Square (2025) rs–3
work page 2025
-
[12]
Y . Kanemitsu, Y . Shimizu, J. Mizusawa, Y . Inaba, T. Ham- aguchi, D. Shida, M. Ohue, K. Komori, A. Shiomi, M. Sh- iozawa, et al., Hepatectomy followed by mfolfox6 ver- sus hepatectomy alone for liver-only metastatic colorectal cancer (jcog0603): a phase ii or iii randomized controlled trial, Journal of Clinical Oncology 39 (34) (2021) 3789– 3799. 15
work page 2021
-
[13]
Y . Kawaguchi, S. Kopetz, H. Tran Cao, E. Panettieri, M. De Bellis, Y . Nishioka, H. Hwang, X. Wang, C.-W. Tzeng, Y . Chun, et al., Contour prognostic model for pre- dicting survival after resection of colorectal liver metas- tases: development and multicentre validation study us- ing largest diameter and number of metastases with ras mutation status, Bri...
work page 2021
-
[14]
P. Pisters, L. B. Harrison, D. Leung, J. M. Woodruff, E. S. Casper, M. F. Brennan, Long-term results of a prospec- tive randomized trial of adjuvant brachytherapy in soft tis- sue sarcoma., Journal of Clinical Oncology 14 (3) (1996) 859–868
work page 1996
-
[15]
P. B. Olthof, S. Buettner, N. Andreatos, J. Wang, I. M. Løes, D. Wagner, K. Sasaki, A. Macher-Beer, C. Kam- phues, I. Pozios, et al., Kras alterations in colorectal liver metastases: shifting to exon, codon, and point mutations, British Journal of Surgery 109 (9) (2022) 804–807
work page 2022
-
[16]
S. Kokkinakis, I. A. Ziogas, J. D. Llaque Salazar, D. P. Moris, G. Tsoulfas, Clinical prediction models for prog- nosis of colorectal liver metastases: A comprehensive re- view of regression-based and machine learning models, Cancers 16 (9) (2024) 1645
work page 2024
-
[17]
M. C. Tan, M. F. Brennan, D. Kuk, N. P. Agaram, C. R. Antonescu, L.-X. Qin, N. Moraco, A. M. Crago, S. Singer, Histology-based classification predicts pattern of recur- rence and improves risk stratification in primary retroperi- toneal sarcoma, Annals of surgery 263 (3) (2016) 593– 600
work page 2016
-
[18]
K. Sasaki, J. Gagnière, A. Dupré, V . Ardiles, J. M. O’Connor, J. Wang, A. Moro, D. Morioka, S. Buettner, L. Gau, et al., Performance of two prognostic scores that incorporate genetic information to predict long-term outcomes following resection of colorectal cancer liver metastases: An external validation of the md anderson and jhh-msk scores, Journal of...
work page 2021
-
[19]
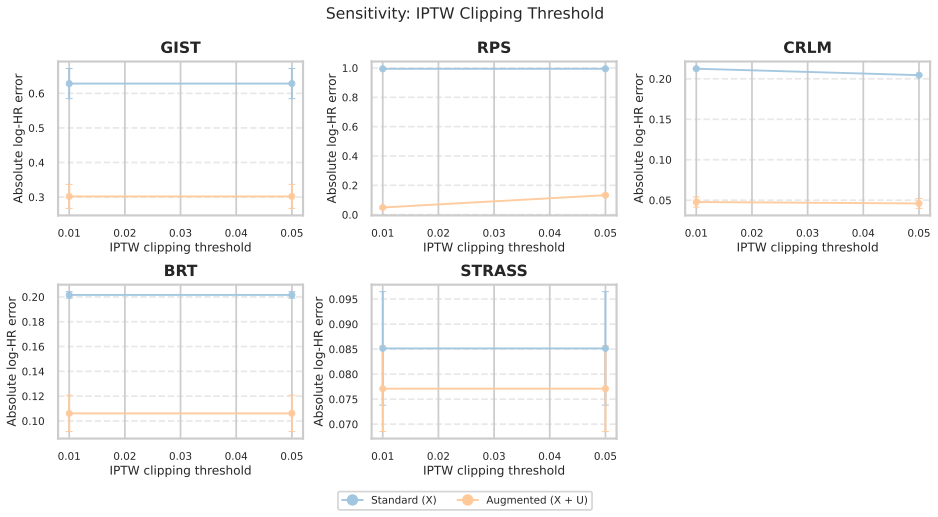
Sensitivity Analysis All sensitivity plots report the mean absolute log-HR error relative to the benchmark hazard ratio, averaged across hyperparam- eter configurations, with standard errors shown as error bars. 4 5 6 7 8 9 10 Number of bins 0.3 0.4 0.5 0.6 0.7 0.8Absolute log-HR error GIST 4 5 6 7 8 9 10 Number of bins 0.4 0.6 0.8Absolute log-HR error RP...
-
[20]
Permutation and Ablation Experiments 2.1. Permutation Experiments To examine whether the improvement observed after incorporating the latent factor ˜Ucould arise from mechanical artifacts rather than genuine latent structure, we conducted a series of permutation experiments. 17 0.01 0.02 0.03 0.04 0.05 IPTW clipping threshold 0.3 0.4 0.5 0.6Absolute log-H...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.