Recognition: unknown
Fundus Image-based Glaucoma Screening via Retinal Knowledge-Oriented Dynamic Multi-Level Feature Integration
Pith reviewed 2026-05-10 15:02 UTC · model grok-4.3
The pith
A tri-branch framework fuses retinal anatomical priors with dynamic lesion localization to raise glaucoma screening robustness in fundus images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
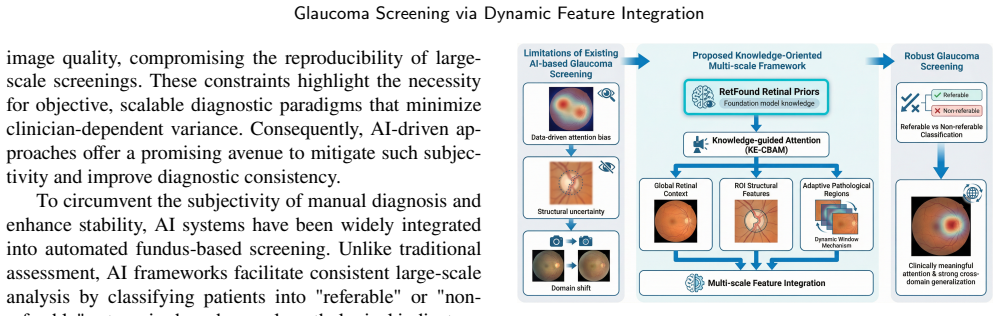
The central claim is that a retinal knowledge-oriented framework that combines dynamic multi-scale feature learning with domain-specific retinal priors in a tri-branch architecture, using a Dynamic Window Mechanism to locate informative regions and a Knowledge-Enhanced Convolutional Attention Module to inject retinal priors, produces more robust glaucoma classification than purely data-driven baselines.
What carries the argument
The Knowledge-Enhanced Convolutional Attention Module that injects retinal priors into attention learning together with the Dynamic Window Mechanism that adaptively selects diagnostically relevant regions.
If this is right
- The tri-branch design captures global retinal context, optic disc and cup structure, and localized pathological cues at the same time.
- Adaptive region selection via the Dynamic Window Mechanism allows pathological signals outside fixed anatomical zones to contribute to the decision.
- Retinal priors steer attention learning so the model focuses on clinically meaningful patterns rather than dataset-specific noise.
- Performance reaches an AUC of 98.5 percent and accuracy of 94.6 percent on the large AIROGS collection while maintaining strong results on multiple external benchmarks.
Where Pith is reading between the lines
- The same prior-guided dynamic localization could be tested on other retinal diseases where lesions appear in variable locations.
- If the priors transfer reliably, the method reduces the amount of labeled data needed for new screening tasks.
- The approach implies that medical imaging models may benefit more from explicit anatomical constraints than from ever-larger purely statistical training sets.
Load-bearing premise
Retinal priors taken from a pre-trained foundation model will remain accurate and helpful when the model encounters new fundus datasets whose imaging conditions and patient demographics differ from the pre-training data.
What would settle it
On a held-out fundus dataset with different cameras and demographics, the full model shows no gain in AUC or accuracy over a plain convolutional network trained from scratch, or expert review finds that the attention maps highlight areas unrelated to actual glaucomatous damage.
Figures









read the original abstract
Automated diagnosis based on color fundus photography is essential for large-scale glaucoma screening. However, existing deep learning models are typically data-driven and lack explicit integration of retinal anatomical knowledge, which limits their robustness across heterogeneous clinical datasets. Moreover, pathological cues in fundus images may appear beyond predefined anatomical regions, making fixed-region feature extraction insufficient for reliable diagnosis. To address these challenges, we propose a retinal knowledge-oriented glaucoma screening framework that integrates dynamic multi-scale feature learning with domain-specific retinal priors. The framework adopts a tri-branch structure to capture complementary retinal representations, including global retinal context, structural features of the optic disc/cup, and dynamically localized pathological regions. A Dynamic Window Mechanism is devised to adaptively identify diagnostically informative regions, while a Knowledge-Enhanced Convolutional Attention Module incorporates retinal priors extracted from a pre-trained foundation model to guide attention learning. Extensive experiments on the large-scale AIROGS dataset demonstrate that the proposed method outperforms diverse baselines, achieving an AUC of 98.5% and an accuracy of 94.6%. Additional evaluations on multiple datasets from the SMDG-19 benchmark further confirm its strong cross-domain generalization capability, indicating that knowledge-guided attention combined with adaptive lesion localization can significantly improve the robustness of automated glaucoma screening systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a retinal knowledge-oriented glaucoma screening framework for fundus images. It uses a tri-branch architecture to capture global retinal context, optic disc/cup structural features, and dynamically localized pathological regions. A Dynamic Window Mechanism adaptively identifies informative regions, and a Knowledge-Enhanced Convolutional Attention Module injects retinal priors from a pre-trained foundation model to guide attention. Experiments report an AUC of 98.5% and accuracy of 94.6% on the large-scale AIROGS dataset, with additional evaluations on SMDG-19 benchmark datasets claimed to demonstrate cross-domain generalization.
Significance. If the performance numbers are reproducible and the knowledge integration demonstrably improves robustness, the work could contribute to more reliable automated glaucoma screening in heterogeneous clinical settings. The tri-branch design with adaptive localization addresses a plausible limitation of fixed-region approaches, and the use of pre-trained retinal priors is a reasonable direction for injecting anatomical knowledge. However, the significance is limited by the absence of detailed validation for the core knowledge-transfer assumption.
major comments (2)
- [Abstract / Experiments] Abstract and Experiments (assumed §4): The central claim attributes the reported AUC 98.5% and cross-domain gains on SMDG-19 to the Knowledge-Enhanced Convolutional Attention Module, yet no quantitative check is provided that the extracted retinal priors remain diagnostically accurate under domain shift (e.g., no prior-to-ground-truth agreement scores, no ablation of the module on out-of-domain sets, and no comparison of prior quality before/after transfer). If the priors degrade, the gains could arise from the tri-branch architecture or Dynamic Window Mechanism alone.
- [Abstract] Abstract: No information is given on training protocol, data splits, statistical testing, or ablation studies. This makes it impossible to assess whether the reported numbers reflect a genuine advance or could be reproduced under standard practices.
minor comments (1)
- [Abstract] The abstract refers to 'diverse baselines' and 'multiple datasets from the SMDG-19 benchmark' without naming them or providing per-dataset metrics; adding this detail would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and have revised the manuscript accordingly to improve clarity and strengthen the validation of our claims.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and Experiments (assumed §4): The central claim attributes the reported AUC 98.5% and cross-domain gains on SMDG-19 to the Knowledge-Enhanced Convolutional Attention Module, yet no quantitative check is provided that the extracted retinal priors remain diagnostically accurate under domain shift (e.g., no prior-to-ground-truth agreement scores, no ablation of the module on out-of-domain sets, and no comparison of prior quality before/after transfer). If the priors degrade, the gains could arise from the tri-branch architecture or Dynamic Window Mechanism alone.
Authors: We agree that explicit quantitative validation of the retinal priors' accuracy under domain shift (such as prior-to-ground-truth agreement or isolated module ablations on out-of-domain data) would provide stronger support for attributing gains specifically to the Knowledge-Enhanced Convolutional Attention Module. Our current experiments show strong overall performance and cross-domain generalization on SMDG-19 with the full framework, but we did not include these specific prior-quality checks. In the revised manuscript, we will add an ablation isolating the module on the SMDG-19 out-of-domain sets along with any feasible prior-quality comparisons. revision: yes
-
Referee: [Abstract] Abstract: No information is given on training protocol, data splits, statistical testing, or ablation studies. This makes it impossible to assess whether the reported numbers reflect a genuine advance or could be reproduced under standard practices.
Authors: The training protocol, data splits, statistical testing, and ablation studies are detailed in the Experiments section of the full manuscript. However, we acknowledge that the abstract lacks a summary of these elements, which limits immediate assessment. We have revised the abstract to briefly note the experimental setup, including cross-validation and the presence of ablation studies confirming component contributions. revision: yes
Circularity Check
No circularity: empirical performance on external benchmarks
full rationale
The paper proposes a tri-branch architecture with a Dynamic Window Mechanism and Knowledge-Enhanced Convolutional Attention Module that incorporates priors from a pre-trained foundation model. All reported results consist of empirical AUC and accuracy metrics evaluated on independent public datasets (AIROGS and SMDG-19 benchmark). No equations, derivations, fitted parameters renamed as predictions, or self-referential definitions appear in the provided text. The central claims are therefore falsifiable against external data and do not reduce to the model's own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
World Health Organization, Blindness and visual impairment, WHO FactSheet,2023.URL:https://www.who.int/news-room/fact-sheets/ detail/blindness-and-visual-impairment, accessed: 2026-02-12
2023
-
[2]
H. A. Quigley, A. T. Broman, The number of people with glaucoma worldwide in 2010 and 2020, British journal of ophthalmology 90 (2006) 262–267
2010
-
[3]
Y.-C.Tham,X.Li,T.Y.Wong,H.A.Quigley,T.Aung,C.-Y.Cheng, Global prevalence of glaucoma and projections of glaucoma burden through2040:asystematicreviewandmeta-analysis,Ophthalmology 121 (2014) 2081–2090
2014
-
[4]
J. M. Tielsch, J. Katz, H. A. Quigley, N. R. Miller, A. Sommer, Intraobserver and interobserver agreement in measurement of optic disc characteristics, Ophthalmology 95 (1988) 350–356
1988
-
[5]
M.Rosano,A.Furnari,L.Gulino,C.Santoro,G.M.Farinella,Image- based navigation in real-world environments via multiple mid-level representations: Fusion models, benchmark and efficient evaluation, Autonomous Robots 47 (2023) 1483–1502
2023
-
[6]
S.-A. Yuan, Z. Wang, F.-L. He, S.-W. Zhang, Z.-Y. Zhao, Gfhanet: Globalfeaturehybridattentionnetworkforsalientobjectdetectionin side-scan sonar images, IEEE Access (2024)
2024
-
[7]
Jalili, A
J. Jalili, A. Jiravarnsirikul, C. Bowd, B. Chuter, A. Belghith, M. H. Goldbaum, S. L. Baxter, R. N. Weinreb, L. M. Zangwill, M. Christo- pher, Glaucomadetectionandfeatureidentificationviagpt-4vfundus image analysis, Ophthalmology Science 5 (2025) 100667
2025
-
[8]
Huang, X
W. Huang, X. Liao, H. Chen, Y. Hu, W. Jia, Q. Wang, Deep local-to-global feature learning for medical image super-resolution, Computerized Medical Imaging and Graphics 115 (2024) 102374
2024
-
[9]
S. Woo, J. Park, J.-Y. Lee, I. S. Kweon, Cbam: Convolutional block attention module, in: Proceedings of the European conference on computer vision (ECCV), 2018, pp. 3–19
2018
-
[10]
J. B. Jonas, G. C. Gusek, G. O. Naumann, Optic disk morphometry in high myopia, Graefe’s archive for clinical and experimental ophthalmology 226 (1988) 587–590
1988
-
[11]
D.F.Garway-Heath,D.Poinoosawmy,F.W.Fitzke,R.A.Hitchings, Mappingthevisualfieldtotheopticdiscinnormaltensionglaucoma eyes, Ophthalmology 107 (2000) 1809–1815
2000
-
[12]
G. C. Caiado, G. A. Samico, G. V. da Silva Filho, S. H. Teixeira, T. S. Prata, C. P. B. Gracitelli, A. Paranhos Jr, Correlation of optic nerve hemoglobin levels with structural and functional parameters in glaucoma, Scientific Reports 15 (2025) 19190
2025
-
[13]
G.D.Joshi,J.Sivaswamy,S.Krishnadas, Opticdiskandcupsegmen- tationfrommonocularcolorretinalimagesforglaucomaassessment, IEEE transactions on medical imaging 30 (2011) 1192–1205
2011
-
[14]
Cheng, J
J. Cheng, J. Liu, Y. Xu, F. Yin, D. W. K. Wong, N.-M. Tan, D. Tao, C.-Y. Cheng, T. Aung, T. Y. Wong, Superpixel classification based optic disc and optic cup segmentation for glaucoma screening, IEEE transactions on medical imaging 32 (2013) 1019–1032
2013
-
[15]
F. Li, W. Xiang, L. Zhang, W. Pan, X. Zhang, M. Jiang, H. Zou, Jointopticdiskandcupsegmentationforglaucomascreeningusinga region-based deep learning network, Eye 37 (2023) 1080–1087
2023
-
[16]
Y. Xu, J. Liu, J. Cheng, F. Yin, N. M. Tan, D. W. K. Wong, C. Y. Cheng, Y. C. Tham, T. Y. Wong, Efficient optic cup localization based on superpixel classification for glaucoma diagnosis in digital fundus images, in: Proceedings of the 21st International Conference on Pattern Recognition (ICPR2012), IEEE, 2012, pp. 49–52
2012
-
[17]
Y. Zhou, M. A. Chia, S. K. Wagner, M. S. Ayhan, D. J. Williamson, R. R. Struyven, T. Liu, M. Xu, M. G. Lozano, P. Woodward-Court, et al., A foundation model for generalizable disease detection from retinal images, Nature 622 (2023) 156–163
2023
-
[18]
Q. Hou, Y. Zhou, J. H. L. Goh, K. Zou, S. M. E. Yew, S. Srinivasan, M. Wang, T. W. S. Lo, X. Lei, S. K. Wagner, et al., Can a natural image-based foundation model outperform a retina-specific model in detecting ocular and systemic diseases?, Ophthalmology Science 6 (2026) 100923
2026
-
[19]
H.Fu,J.Cheng,Y.Xu,D.W.K.Wong,J.Liu,X.Cao, Jointopticdisc and cup segmentation based on multi-label deep network and polar transformation, IEEE transactions on medical imaging 37 (2018) 1597–1605
2018
-
[20]
Truhn, T
C.DeVente,K.A.Vermeer,N.Jaccard,H.Wang,H.Sun,F.Khader, D. Truhn, T. Aimyshev, Y. Zhanibekuly, T.-D. Le, et al., Airogs: Artificialintelligenceforrobustglaucomascreeningchallenge, IEEE transactions on medical imaging 43 (2023) 542–557
2023
-
[21]
doi:10.34740/KAGGLE/DS/2329670
R.Kiefer,Smdg,astandardizedfundusglaucomadataset,2023.URL: https://www.kaggle.com/ds/2329670. doi:10.34740/KAGGLE/DS/2329670
-
[22]
P. Li, J. Liu, Early diagnosis and quantitative analysis of stages in retinopathy of prematurity based on deep convolutional neural networks, TranslationalVisionScience&Technology11(2022)17– 17
2022
-
[23]
J. Zhao, H. Lei, H. Xie, P. Li, Y. Liu, G. Zhang, B. Lei, Dual-branch attention network and swin spatial pyramid pooling for retinopathy of prematurity classification, in: 2023 IEEE 20th International Symposium on Biomedical Imaging (ISBI), IEEE, 2023, pp. 1–4
2023
-
[24]
M. Alam, E. J. Zhao, C. K. Lam, D. L. Rubin, Segmentation- assisted fully convolutional neural network enhances deep learning performance to identify proliferative diabetic retinopathy, Journal of clinical medicine 12 (2023) 385
2023
-
[25]
R.C.Joshi,A.K.Sharma,M.K.Dutta,Visiondeep-ai:Deeplearning- basedretinalbloodvesselssegmentationandmulti-classclassification framework for eye diagnosis, Biomedical Signal Processing and Control 94 (2024) 106273
2024
-
[26]
Almeida, J
J. Almeida, J. Kubicek, M. Penhaker, M. Cerny, M. Augustynek, A. Varysova, A. Bansal, J. Timkovic, Enhancing rop plus form diag- nosis: an automatic blood vessel segmentation approach for newborn fundus images, Results in engineering 24 (2024) 103054
2024
-
[27]
Xiong, F
H. Xiong, F. Long, M. S. Alam, J. Sang, Multi-glaucnet: A multi- task model for optic disc segmentation, blood vessel segmentation and glaucoma detection, Biomedical Signal Processing and Control 99 (2025) 106850
2025
-
[28]
C.Guan,H.Ai,W.Wang,R.P.Singh,S.Song, Diffmcg:Adiffusion model with mask-conditioned guiding module for medical image classification, Neural Networks (2026) 108690
2026
-
[29]
S.S.U.Shah,M.Huzaifa,H.K.K.Tareen,M.N.Bajwa, Optiguard: Generalized, attention-driven & explainable glaucoma classification, in:202547thAnnualInternationalConferenceoftheIEEEEngineer- ing in Medicine and Biology Society (EMBC), IEEE, 2025, pp. 1–7. Yuzhuo Zhou, Chi Liu, Sheng Shen, et al.:Preprint submitted to ElsevierPage 13 of 13
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.