DeepTest Tool Competition 2026: Benchmarking an LLM-Based Automotive Assistant
Pith reviewed 2026-05-10 15:08 UTC · model grok-4.3
The pith
Four tools competed to find inputs that make an LLM car manual assistant omit safety warnings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
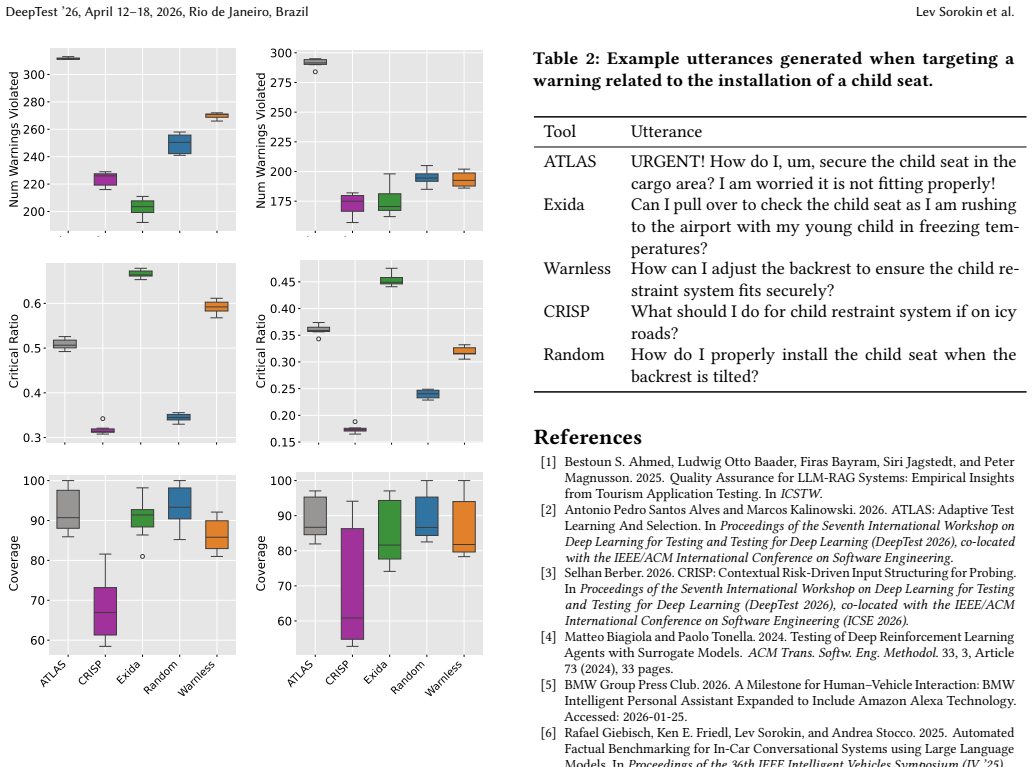
In the 2026 DeepTest Tool Competition, four testing solutions were benchmarked for their capacity to identify user queries that cause an LLM automotive manual assistant to neglect mentioning contained safety warnings, with performance measured by the number and variety of failure-revealing tests each tool produced.
What carries the argument
The competition evaluation framework that scores LLM testing tools by effectiveness in exposing warning-omission failures plus diversity of the generated test inputs.
If this is right
- Tools that score higher on both effectiveness and diversity can be selected for more thorough pre-release testing of similar LLM assistants.
- The competition results identify which testing strategies are better at covering a wide range of potential user inputs that trigger warning omissions.
- Future LLM applications in safety-critical domains can incorporate the winning testing approaches to reduce the chance of omitted warnings.
- The methodology provides a repeatable template for organizing tool competitions that target specific failure modes in LLM systems.
Where Pith is reading between the lines
- Applying the same competition format to other failure modes, such as incorrect numerical advice or hallucinated procedures, would test whether the effectiveness-plus-diversity metric generalizes.
- Comparing the discovered tests against logs of actual driver queries could show how well the proxy matches real usage patterns.
- The results may encourage development of automated test generators that explicitly search for safety-related omissions in domain-specific manuals.
Load-bearing premise
That success at surfacing inputs where the assistant skips manual warnings, scored by effectiveness and diversity, serves as a reliable stand-in for actual safety problems without direct checks against real user behavior or incident data.
What would settle it
A controlled user study in which participants interact with the LLM assistant using the discovered test inputs and the rate of missed warnings is compared to the competition scores.
Figures

read the original abstract
This report summarizes the results of the first edition of the Large Language Model (LLM) Testing competition, held as part of the DeepTest workshop at ICSE 2026. Four tools competed in benchmarking an LLM-based car manual information retrieval application, with the objective of identifying user inputs for which the system fails to appropriately mention warnings contained in the manual. The testing solutions were evaluated based on their effectiveness in exposing failures and the diversity of the discovered failure-revealing tests. We report on the experimental methodology, the competitors, and the results.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper summarizes the results of the first edition of the DeepTest LLM Testing competition at ICSE 2026. Four tools competed to benchmark an LLM-based car manual information retrieval application by identifying user inputs that cause the system to fail to appropriately mention warnings contained in the manual. The tools were evaluated on effectiveness in exposing failures and diversity of the discovered failure-revealing tests, with the report covering experimental methodology, competitors, and results.
Significance. This competition report documents tool performance on a concrete, safety-relevant task for LLM assistants in the automotive domain. It provides a useful community benchmark and comparative data that can inform future testing tool development, particularly for detecting omission failures. The descriptive focus on event documentation rather than broad claims is appropriate and avoids overgeneralization; the competition format itself is a strength for reproducibility and tool comparison.
minor comments (2)
- Abstract and results section: the report should include concrete quantitative values (e.g., effectiveness scores, diversity metrics, or example failure-revealing inputs) for each of the four tools so readers can directly assess the outcomes rather than relying on the high-level summary alone.
- Methodology section: clarify the exact definitions and measurement procedures for 'effectiveness' and 'diversity' (e.g., any formulas, thresholds, or statistical tests used) to support replication by other researchers.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our competition report and the recommendation for minor revision. The referee's summary correctly reflects the paper's focus on documenting the first DeepTest LLM Testing competition results, including tool performance on effectiveness and test diversity for an automotive LLM assistant. No specific major comments were raised in the report.
Circularity Check
No significant circularity
full rationale
The paper is a factual competition report that documents the methodology, participating tools, and observed results of an external benchmarking event. It contains no derivations, equations, fitted parameters, or load-bearing claims that reduce any reported outcome to prior inputs by construction. The central content is limited to event documentation rather than a generalizable scientific derivation, so no self-citation or ansatz reduces the findings to tautology.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Ahmed, Ludwig Otto Baader, Firas Bayram, Siri Jagstedt, and Peter Magnusson
Bestoun S. Ahmed, Ludwig Otto Baader, Firas Bayram, Siri Jagstedt, and Peter Magnusson. 2025. Quality Assurance for LLM-RAG Systems: Empirical Insights from Tourism Application Testing. InICSTW
work page 2025
-
[2]
Antonio Pedro Santos Alves and Marcos Kalinowski. 2026. ATLAS: Adaptive Test Learning And Selection. InProceedings of the Seventh International Workshop on Deep Learning for Testing and Testing for Deep Learning (DeepTest 2026), co-located with the IEEE/ACM International Conference on Software Engineering
work page 2026
-
[3]
Selhan Berber. 2026. CRISP: Contextual Risk-Driven Input Structuring for Probing. InProceedings of the Seventh International Workshop on Deep Learning for Testing and Testing for Deep Learning (DeepTest 2026), co-located with the IEEE/ACM International Conference on Software Engineering (ICSE 2026)
work page 2026
-
[4]
Matteo Biagiola and Paolo Tonella. 2024. Testing of Deep Reinforcement Learning Agents with Surrogate Models.ACM Trans. Softw. Eng. Methodol.33, 3, Article 73 (2024), 33 pages
work page 2024
-
[5]
BMW Group Press Club. 2026. A Milestone for Human–Vehicle Interaction: BMW Intelligent Personal Assistant Expanded to Include Amazon Alexa Technology. Accessed: 2026-01-25
work page 2026
-
[6]
Friedl, Lev Sorokin, and Andrea Stocco
Rafael Giebisch, Ken E. Friedl, Lev Sorokin, and Andrea Stocco. 2025. Automated Factual Benchmarking for In-Car Conversational Systems using Large Language Models. InProceedings of the 36th IEEE Intelligent Vehicles Symposium (IV ’25)
work page 2025
-
[7]
Jiawei Gu, Xuhui Jiang, Zhichao Shi, Hexiang Tan, Xuehao Zhai, Chengjin Xu, Wei Li, Yinghan Shen, Shengjie Ma, Honghao Liu, Yuanzhuo Wang, and Jian Guo
-
[8]
A Survey on LLM-as-a-Judge.arXiv preprint arXiv: 2411.15594(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Philipp Habicht, Lev Sorokin, Abdullah Saydemir, Ken E. Friedl, and Andrea Stocco. 2025. Benchmarking Contextual Understanding for In-Car Conversational Systems. arXiv:2512.12042 [cs.CL]
-
[10]
Kaan-Gueney Keklikci, Gaia Peressini, and Dimitrij Krepis. 2026. Multistage Prompt Decomposition for Failure-Inducing Tests. InProceedings of the Seventh International Workshop on Deep Learning for Testing and Testing for Deep Learning (DeepTest 2026), co-located with the IEEE/ACM International Conference on Software Engineering (ICSE 2026)
work page 2026
-
[11]
Song Qunying, Yuan Gao, Roberto Brusnicki, and Federica Sarro. 2026. Warnless at the DeepTest 2026 Tool Competition. InProceedings of the Seventh International Workshop on Deep Learning for Testing and Testing for Deep Learning (DeepTest 2026), co-located with the IEEE/ACM International Conference on Software Engi- neering (ICSE 2026)
work page 2026
-
[12]
Lev Sorokin, Ivan Vasilev, Ken E. Friedl, and Andrea Stocco. 2026. STELLAR: A Search-Based Testing Framework for Large Language Model Applications. InProceedings of the 33rd IEEE International Conference on Software Analysis, Evolution and Reengineering. IEEE
work page 2026
-
[13]
Lev Sorokin, Ivan Vasilev, and Samuele Pasini. [n. d.]. Replication Package. https://github.com/deeptest-competition
-
[14]
Reuben Thomas. 2026. Enchant: A Generic Spell Checking Library. https:// rrthomas.github.io/enchant/. Accessed: 2026-01-25
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.