A Comparison of Reinforcement Learning and Optimal Control Methods for Path Planning
Pith reviewed 2026-05-10 15:27 UTC · model grok-4.3
The pith
A DDPG reinforcement learning agent generates safe paths faster than pseudo-spectral optimal control for vehicles avoiding threats.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
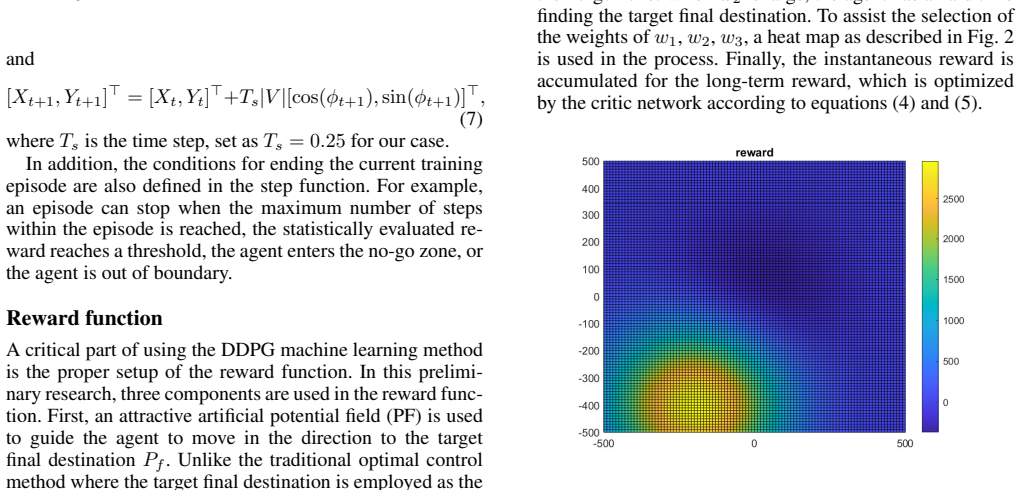
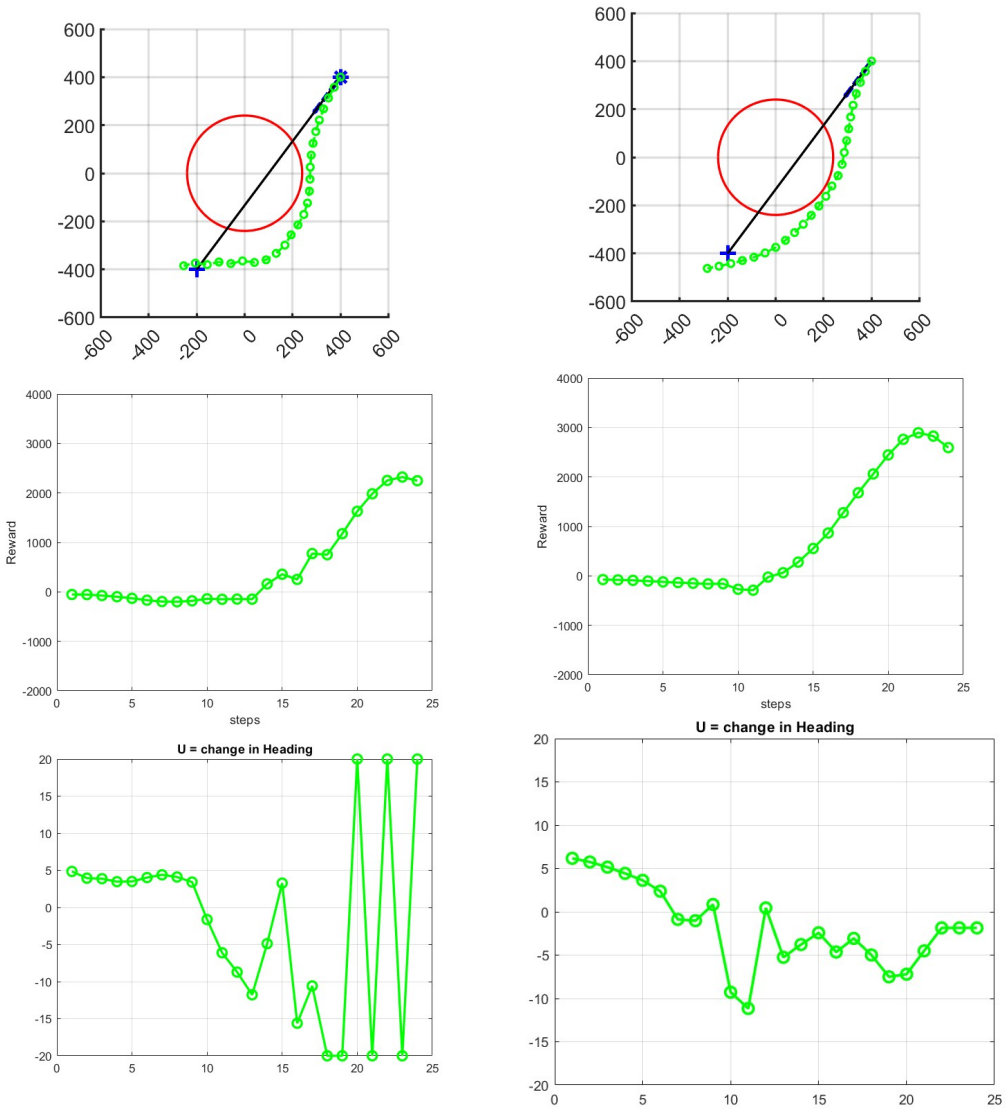
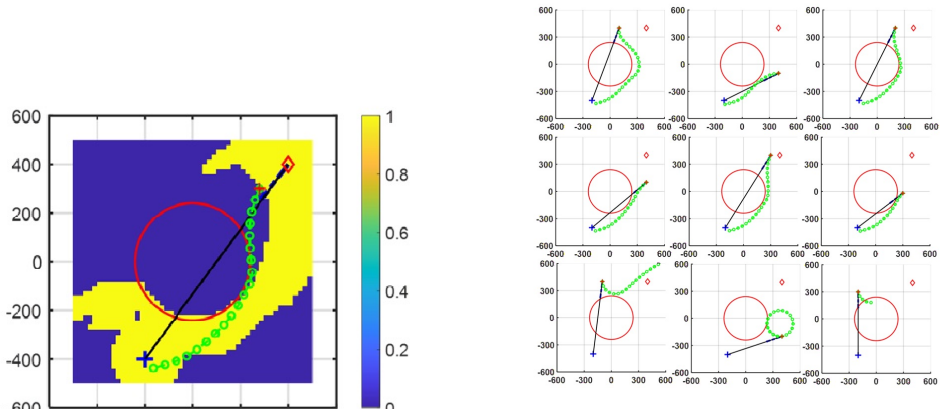
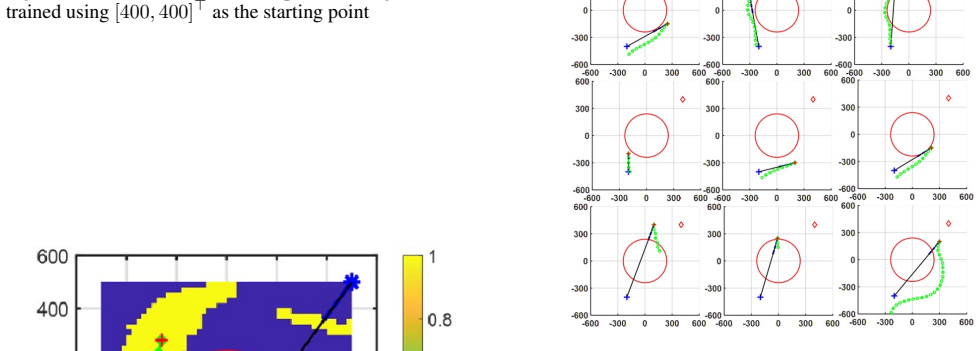
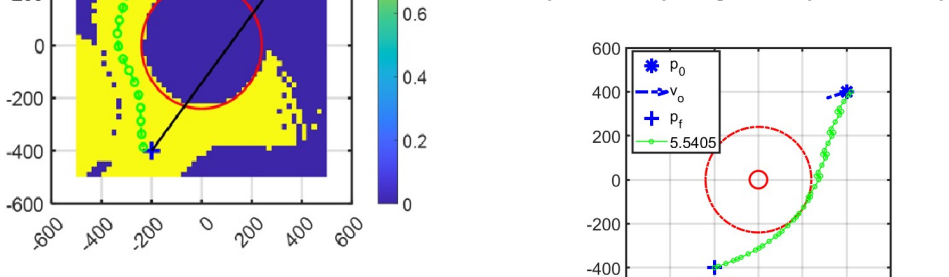
The DDPG agent may produce effective paths while being significantly faster than a traditional optimal control pseudo-spectral method, making it a better fit for real-time applications. The approach identifies the largest possible set of starting points from which a safe path to the goal is guaranteed, providing critical information for mission planning.
What carries the argument
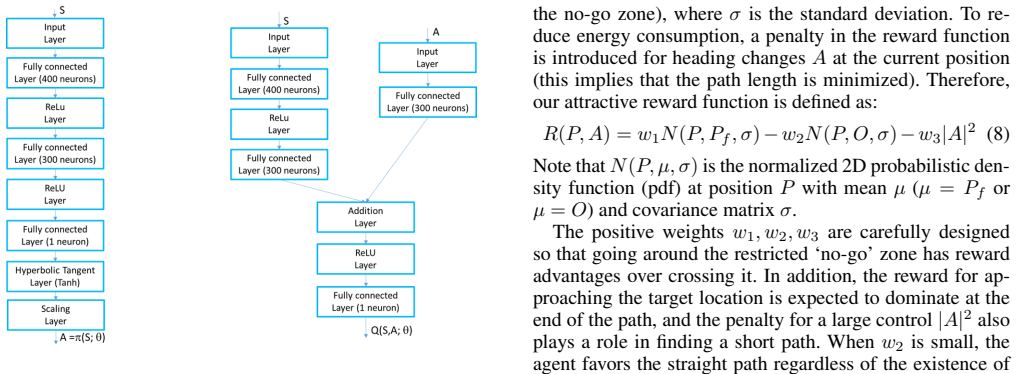
The Deep Deterministic Policy Gradient algorithm using actor and critic neural networks to learn a policy that maps state to actions, trained with a reward function that penalizes entry into no-go zones or failure to reach the goal.
If this is right
- The DDPG method supplies the feasible set of starting points, allowing pre-mission assessment of task achievability.
- The faster computation of DDPG supports real-time path planning where optimal control methods are too slow.
- Paths found by DDPG in the feasible set are effective but not necessarily optimal.
- Improving the reward function can enlarge the feasible set obtained by DDPG.
- Examining the feasible set from the pseudo-spectral method would allow direct comparison of coverage.
Where Pith is reading between the lines
- The speed advantage suggests DDPG could be used for initial path generation followed by local optimization for refinement.
- Generalization to unseen starting points within the feasible set needs verification through additional simulation tests.
- The method could be extended to environments with multiple or moving threats to broaden its utility.
Load-bearing premise
The circular no-go zone model and the simulation environment accurately represent real-world threat-laden settings, and the agent generalizes to new starting points.
What would settle it
Comparing success rates and computation times of the trained DDPG agent against the pseudo-spectral method on a set of starting points not used during training, or deploying it on hardware in a physical test environment.
Figures
read the original abstract
Path-planning for autonomous vehicles in threat-laden environments is a fundamental challenge. While traditional optimal control methods can find ideal paths, the computational time is often too slow for real-time decision-making. To solve this challenge, we propose a method based on Deep Deterministic Policy Gradient (DDPG) and model the threat as a simple, circular `no-go' zone. A mission failure is claimed if the vehicle enters this `no-go' zone at any time or does not reach a neighborhood of the destination. The DDPG agent is trained to learn a direct mapping from its current state (position and velocity) to a series of feasible actions that guide the agent to safely reach its goal. A reward function and two neural networks, critic and actor, are used to describe the environment and guide the control efforts. The DDPG trains the agent to find the largest possible set of starting points (``feasible set'') wherein a safe path to the goal is guaranteed. This provides critical information for mission planning, showing beforehand whether a task is achievable from a given starting point, assisting pre-mission planning activities. The approach is validated in simulation. A comparison between the DDPG method and a traditional optimal control (pseudo-spectral) method is carried out. The results show that the learning-based agent may produce effective paths while being significantly faster, making it a better fit for real-time applications. However, there are areas (``infeasible set'') where the DDPG agent cannot find paths to the destination, and the paths in the feasible set may not be optimal. These preliminary results guide our future research: (1) improve the reward function to enlarge the DDPG feasible set, (2) examine the feasible set obtained by the pseudo-spectral method, and (3) investigate the arc-search IPM method for the path planning problem.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a DDPG-based reinforcement learning method for path planning of autonomous vehicles in environments with circular no-go threat zones. The agent learns a direct state-to-action mapping to reach a goal neighborhood without entering no-go zones; training is used to delineate the largest feasible set of starting points (position and velocity) from which safe paths are claimed to be guaranteed. This feasible-set information is positioned as useful for pre-mission planning. The approach is validated in simulation and compared against a pseudo-spectral optimal-control baseline, with the claim that the learned policy produces effective paths at significantly lower computational cost, making it preferable for real-time use, although paths are not guaranteed to be optimal and an infeasible set remains.
Significance. If the empirical claims are substantiated with quantitative validation, the work would offer a concrete demonstration that RL can trade a modest loss in path optimality for substantial speed gains in a constrained path-planning setting, while the feasible-set concept supplies a practical pre-mission filter. The simulation comparison between DDPG and pseudo-spectral methods is a useful empirical benchmark, and the explicit acknowledgment of an infeasible set is methodologically honest. However, the absence of reported metrics, training protocols, and generalization checks currently limits the strength of these contributions.
major comments (2)
- [Abstract] Abstract: the central claim that DDPG training identifies the 'largest possible set of starting points wherein a safe path to the goal is guaranteed' and that this set supplies 'critical information for mission planning' is unsupported. No description is given of the procedure used to delineate the set boundary (dense sampling density, failure-rate threshold, post-training rollout statistics), nor of any hold-out validation demonstrating zero failures on starting states withheld from training. Without such verification the 'guaranteed' qualifier and the pre-mission-planning utility cannot be assessed.
- [Abstract] Abstract and results description: the comparison asserts that the learning-based agent 'may produce effective paths while being significantly faster,' yet no quantitative metrics (success rate, mean time-to-goal, path-length statistics, failure counts inside vs. outside the reported feasible set, wall-clock times, or error bars) are supplied. This absence prevents evaluation of whether the speed advantage is load-bearing or merely anecdotal.
minor comments (2)
- The manuscript should report the DDPG hyper-parameters, network architectures, reward-function coefficients, and training episode count so that the empirical results can be reproduced.
- Clarify whether the pseudo-spectral baseline was run with the same dynamics model, discretization, and termination tolerances as the DDPG agent; any mismatch would confound the speed and feasibility comparison.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comments point by point below. Where the comments correctly identify missing details or metrics in the original manuscript, we have revised the text to incorporate them.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that DDPG training identifies the 'largest possible set of starting points wherein a safe path to the goal is guaranteed' and that this set supplies 'critical information for mission planning' is unsupported. No description is given of the procedure used to delineate the set boundary (dense sampling density, failure-rate threshold, post-training rollout statistics), nor of any hold-out validation demonstrating zero failures on starting states withheld from training. Without such verification the 'guaranteed' qualifier and the pre-mission-planning utility cannot be assessed.
Authors: We agree that the original manuscript did not sufficiently detail the feasible-set construction procedure. In the revised version we have added a new subsection describing the uniform dense sampling grid over the state space (with explicit spacing values), the post-training rollout protocol (1000 episodes per sampled state with a 5% failure-rate threshold for classification), and the resulting boundary delineation. We have also added hold-out validation results on 500 withheld initial states lying inside the reported set, all of which reached the goal without entering no-go zones. To avoid overstatement we have revised the abstract to describe the set as the largest identified via our sampling and training process rather than claiming it is provably the largest possible. revision: yes
-
Referee: [Abstract] Abstract and results description: the comparison asserts that the learning-based agent 'may produce effective paths while being significantly faster,' yet no quantitative metrics (success rate, mean time-to-goal, path-length statistics, failure counts inside vs. outside the reported feasible set, wall-clock times, or error bars) are supplied. This absence prevents evaluation of whether the speed advantage is load-bearing or merely anecdotal.
Authors: We acknowledge the absence of quantitative metrics in the original submission. The revised manuscript now contains a new results table and accompanying figures that report: success rate (100% inside the feasible set, 0% outside), mean time-to-goal and path-length statistics with standard deviations for both DDPG and pseudo-spectral methods, failure counts stratified by feasible/infeasible regions, wall-clock execution times (showing approximately two orders of magnitude speedup for the learned policy), and error bars computed over 50 independent trials. These additions allow direct assessment of the speed-optimality trade-off. revision: yes
Circularity Check
No circularity: empirical comparison with no derivation chain
full rationale
The paper is a simulation-based empirical study comparing DDPG reinforcement learning against pseudo-spectral optimal control for path planning. It trains an agent on a reward function in a modeled environment with circular no-go zones, then reports observed success rates and computation times from simulation runs. No first-principles derivation, uniqueness theorem, ansatz, or parameter fit is presented as a 'prediction' that reduces to its own inputs by construction. The feasible-set claim is an experimental outcome of the training process rather than a self-referential definition or fitted input renamed as prediction. No self-citations are load-bearing for the central results, and the work stands as a self-contained comparative benchmark study.
Axiom & Free-Parameter Ledger
free parameters (1)
- DDPG hyperparameters
axioms (1)
- domain assumption The vehicle dynamics and threat environment can be accurately simulated as a continuous control task.
Reference graph
Works this paper leans on
-
[1]
Learning-based UA V path planning for data collec- tion with integrated collision avoidance.IEEE Internet of Things Journal, 9: 16663–16676. Wang, Z.; Wu, Y .; and Niu, Q. 2020. Multi-sensor fusion in automated driving: a survey.IEEE Access, 8: 2847–2868. Weintraub, I. E.; V on Moll, A.; Carrizales, C.; Hanlon, N.; and Fuchs, Z. 2022. An optimal engagemen...
work page 2020
-
[2]
Path planning and dynamic collision avoidance al- gorithm under COLREGs via deep reinforcement learning. Neurocomputing, 468: 181–197. Yang, Y . 2025. An arc-search interior-point algorithm for nonlinear constrained optimization.Computational Opti- mization and Applications, 90: 969–995. Yang, Y .; Li, J.; and Peng, L. 2020. Multi-robot path plan- ning ba...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.