ToolSpec: Accelerating Tool Calling via Schema-Aware and Retrieval-Augmented Speculative Decoding
Pith reviewed 2026-05-10 14:14 UTC · model grok-4.3
The pith
ToolSpec accelerates LLM tool calling up to 4.2 times by using tool schemas and past calls for accurate speculative drafts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
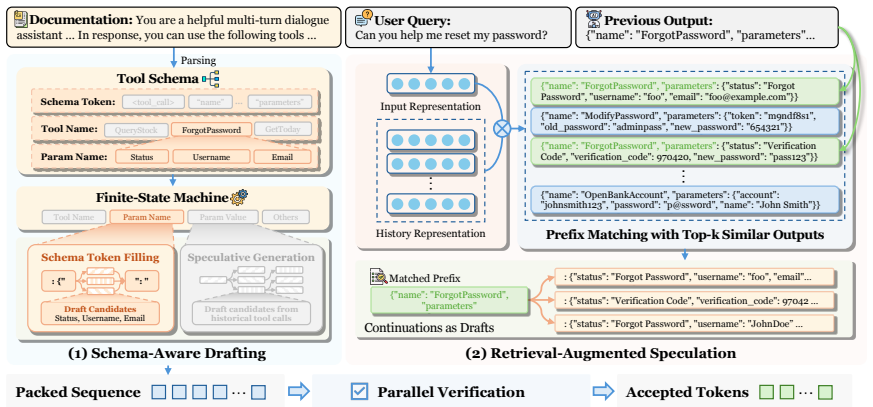
ToolSpec is a schema-aware, retrieval-augmented speculative decoding method that exploits predefined tool schemas to generate accurate drafts, using a finite-state machine to alternate between deterministic schema token filling and speculative generation for variable fields, while retrieving similar historical tool invocations to reuse as drafts, achieving up to 4.2x speedup across benchmarks and outperforming existing training-free methods.
What carries the argument
The finite-state machine that alternates between deterministic schema token filling and speculative generation for variable fields, combined with retrieval of similar past tool invocations for draft reuse.
If this is right
- Multi-turn and multi-step tool interactions become feasible at lower latency in real-time LLM serving.
- The method integrates directly into existing workflows without retraining or modifying the base model.
- Speculative decoding performance improves specifically for structured outputs compared with generic training-free baselines.
- Overall token generation throughput rises for any application relying on repeated tool schemas.
Where Pith is reading between the lines
- The same schema-plus-retrieval pattern could apply to other constrained generation tasks such as producing valid JSON or code snippets.
- If historical traces are available across domains, the retrieval component might reduce the need for model-specific tuning in structured prediction.
- A natural test would measure whether the speedup holds when tool schemas change frequently or when historical data is sparse.
Load-bearing premise
Tool-calling traces are highly structured, conform to constrained schemas, and often exhibit recurring invocation patterns that can be exploited for accurate draft generation.
What would settle it
Applying ToolSpec to tool-calling benchmarks with highly variable schemas and non-recurring patterns and measuring no speedup or lower draft acceptance rate would falsify the central claim.
Figures


read the original abstract
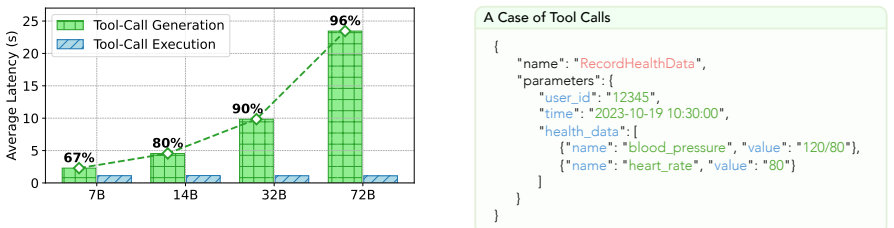
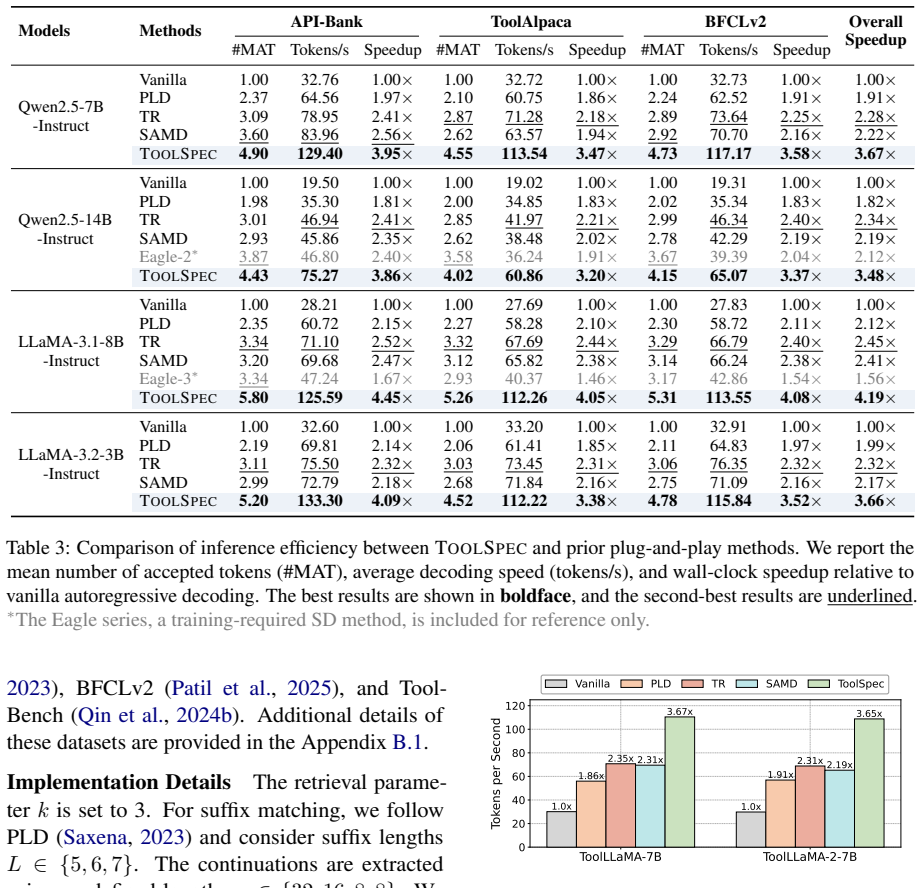
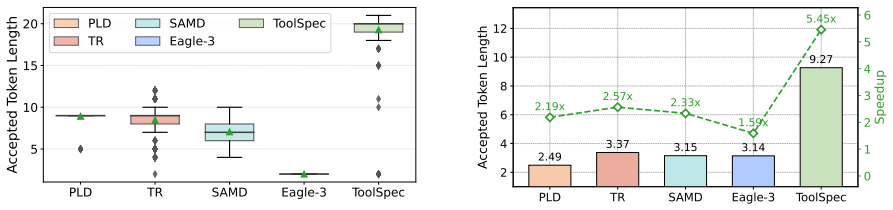
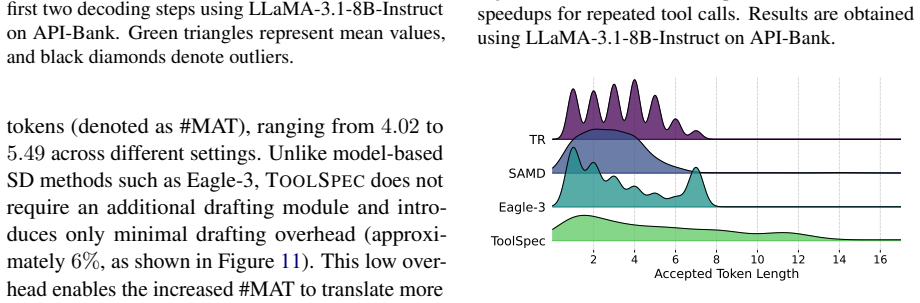
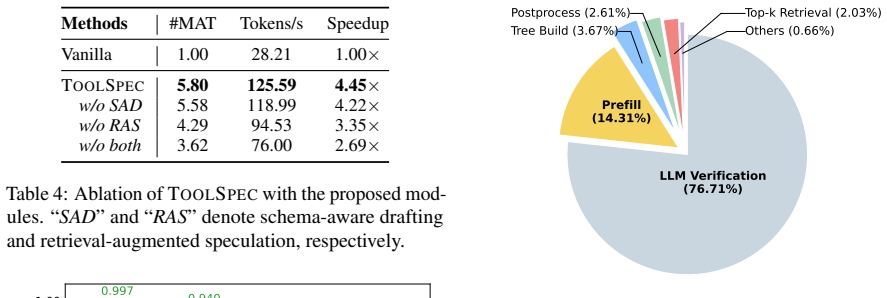
Tool calling has greatly expanded the practical utility of large language models (LLMs) by enabling them to interact with external applications. As LLM capabilities advance, effective tool use increasingly involves multi-step, multi-turn interactions to solve complex tasks. However, the resulting growth in tool interactions incurs substantial latency, posing a key challenge for real-time LLM serving. Through empirical analysis, we find that tool-calling traces are highly structured, conform to constrained schemas, and often exhibit recurring invocation patterns. Motivated by this, we propose ToolSpec, a schema-aware, retrieval-augmented speculative decoding method for accelerating tool calling. ToolSpec exploits predefined tool schemas to generate accurate drafts, using a finite-state machine to alternate between deterministic schema token filling and speculative generation for variable fields. In addition, ToolSpec retrieves similar historical tool invocations and reuses them as drafts to further improve efficiency. ToolSpec presents a plug-and-play solution that can be seamlessly integrated into existing LLM workflows. Experiments across multiple benchmarks demonstrate that ToolSpec achieves up to a 4.2x speedup, substantially outperforming existing training-free speculative decoding methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces ToolSpec, a training-free speculative decoding method for accelerating LLM tool calling. It combines a finite-state machine to deterministically fill constrained schema fields with retrieval of similar historical tool invocations as high-quality drafts. Motivated by an empirical observation that tool-calling traces are highly structured and exhibit recurring patterns, the approach is presented as a plug-and-play addition to existing LLM serving pipelines. The central empirical claim is that ToolSpec delivers up to 4.2× speedup over prior training-free speculative decoding baselines across multiple benchmarks.
Significance. If the speedup and robustness claims hold after proper controls, ToolSpec would provide a practical, training-free route to lower latency in multi-turn tool-augmented LLM applications. The plug-and-play design and explicit use of schema structure are clear engineering strengths that could see adoption in production serving systems.
major comments (2)
- [Abstract] Abstract: the 4.2× speedup is asserted without any description of the benchmarks, baseline implementations, number of runs, statistical significance tests, or error bars. This absence is load-bearing for the central empirical claim and prevents verification that the result survives standard controls.
- [§4] §4 (Experiments): no ablation or cold-start evaluation isolates the contribution of the retrieval component or measures degradation when historical data is sparse or absent. Because the speedup is predicated on the availability of retrievable recurring patterns, the lack of such a test leaves the generalizability claim unsupported.
minor comments (1)
- A diagram or pseudocode for the FSM state machine would clarify how deterministic schema filling interleaves with speculative generation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We appreciate the emphasis on strengthening the empirical presentation and generalizability claims. We address each major comment below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: [Abstract] Abstract: the 4.2× speedup is asserted without any description of the benchmarks, baseline implementations, number of runs, statistical significance tests, or error bars. This absence is load-bearing for the central empirical claim and prevents verification that the result survives standard controls.
Authors: We agree that the abstract would benefit from additional context to make the speedup claim more verifiable. In the revised manuscript, we will expand the abstract to briefly specify the benchmarks (tool-calling evaluation suites), the training-free speculative decoding baselines, and note that results are averaged over multiple runs with standard deviations reported. Detailed statistical significance tests and full error-bar analysis will remain in Section 4 due to abstract length limits. This change directly addresses the load-bearing nature of the claim without altering the reported results. revision: yes
-
Referee: [§4] §4 (Experiments): no ablation or cold-start evaluation isolates the contribution of the retrieval component or measures degradation when historical data is sparse or absent. Because the speedup is predicated on the availability of retrievable recurring patterns, the lack of such a test leaves the generalizability claim unsupported.
Authors: We acknowledge that explicit isolation of the retrieval component via cold-start and sparsity ablations is necessary to support generalizability. While the current experiments include implicit comparisons between schema-aware FSM drafting and the full retrieval-augmented system, we will add a dedicated subsection in the revised Section 4. This will include: (1) cold-start results with an empty historical database, (2) performance as a function of historical database size, and (3) degradation analysis under increasing data sparsity. These additions will quantify the retrieval contribution and clarify reliance on recurring patterns. revision: yes
Circularity Check
No circularity: empirical method proposal with independent experimental validation
full rationale
The paper presents ToolSpec as an engineering synthesis of existing speculative decoding techniques with FSM-based schema enforcement and retrieval of historical traces. The central claim of up to 4.2x speedup rests on benchmark experiments rather than any derivation, equation, or fitted parameter that reduces to its own inputs by construction. No self-definitional steps, fitted-input predictions, or load-bearing self-citations appear in the description; the observation that tool traces are structured is treated as an external empirical motivation, not a tautology. The result is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Ghost Tool Calls: Issue-Time Privacy for Speculative Agent Tools
Ghost tool calls from speculative dispatch create persistent intent leaks that only issue-time policies changing or suppressing call arguments or destinations can reduce, per evaluations of twelve policies on three corpora.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.