A Universal Textual Merge Strategy Based on Tokens for Version Control Systems
Pith reviewed 2026-05-10 12:48 UTC · model grok-4.3
The pith
Summer converts edits from one branch into token rewriting and move rules to merge text from the other branch.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
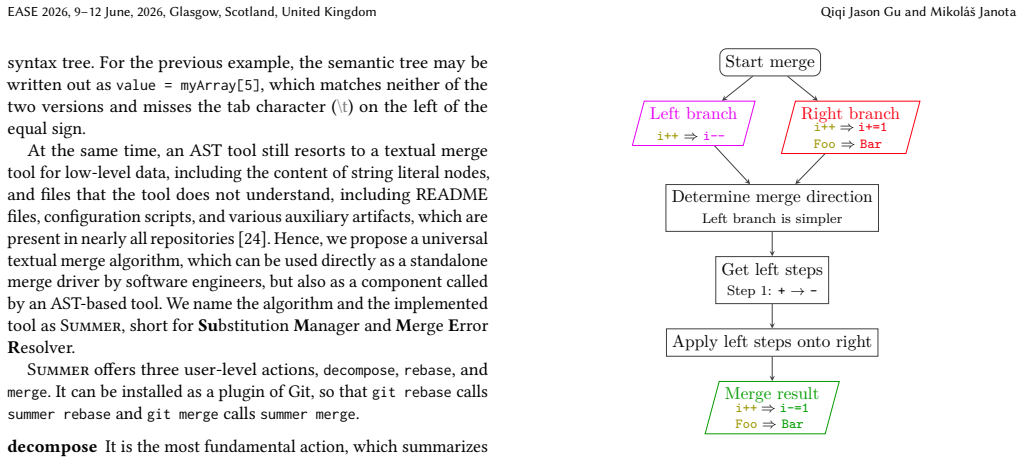
Summer formulates token-level changes in one branch into string-rewriting rules and move rules, and applies these rules to the text of the other branch to construct a merge. Despite being independent of programming languages, the move rules model extracting and inlining functions.
What carries the argument
String-rewriting rules and move rules derived from token-level differences, which are applied from one branch's changes to the other branch's text.
If this is right
- The same algorithm works on both Java and non-Java files without any parser change.
- Move rules let the merge capture structural edits such as function extraction and inlining.
- Verbatim reproduction of developer merges reaches 36 percent, higher than the five compared tools.
- Semantic accuracy ranks second while remaining fully format-preserving and language-independent.
- The approach extends naturally to any text-based artifacts, not just source code.
Where Pith is reading between the lines
- Existing version-control systems could adopt the rule-based step as an optional merge strategy for files that currently produce many conflicts.
- The same token-rule technique might be applied to collaborative editing of configuration files or documentation where syntax awareness is unavailable.
- Combining the rewriting rules with a lightweight post-check for obvious semantic mismatches could raise accuracy further without adding parser dependencies.
- Evaluating the method on merge histories from additional languages or from non-programming domains would test how far the universality claim holds.
Load-bearing premise
Dividing text into tokens and treating edits as rewriting and move rules will faithfully represent developer intent across refactorings and parallel edits without language-specific knowledge or loss of formatting.
What would settle it
A new collection of merge scenarios in which Summer produces fewer semantically correct results than a simple line-based tool, or in which formatting is altered in the output.
Figures


read the original abstract
Merging is a core operation in version control systems such as Git, but traditional line-based algorithms often yield spurious conflicts, particularly in the presence of refactorings or parallel edits. While syntax- and semantics-aware merging approaches can reduce conflicts, they introduce drawbacks such as loss of formatting, dependence on language-specific parsers, and limited flexibility across heterogeneous artifacts. To address this gap, we present Summer, a novel textual token-based merge algorithm independent of document formats. Dividing text into tokens, our approach formulates token-level changes in one branch into string-rewriting rules and move rules, and applies these rules to the text of the other branch to construct a merge. Despite being independent on programming languages, our move rules model extracting and inlining functions. We evaluated Summer on ConflictBench, a large benchmark of real-world merge scenarios, comparing it with five pioneering merge tools across Java and non-Java files. Experimental results show that Summer achieved the highest 36% accuracy in reproducing merges verbatim identical to developers', and ranked second in semantic accuracy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Summer, a token-based textual merge algorithm for version control systems. Text is divided into tokens; changes from one branch are expressed as string-rewriting rules and move rules that are then applied to the other branch. The method is presented as format- and language-independent, with move rules claimed to capture refactorings such as function extraction and inlining. On the ConflictBench benchmark of real-world merge scenarios, Summer is reported to achieve the highest 36% verbatim accuracy in reproducing developer merges and to rank second in semantic accuracy when compared against five other merge tools on both Java and non-Java files.
Significance. If the reported results hold, the work offers a practical middle ground between line-based merges (which produce spurious conflicts) and syntax- or semantics-aware approaches (which often lose formatting or require language-specific parsers). The empirical evaluation on a large, real-world benchmark supplies concrete evidence that a purely textual token-level strategy can reproduce a non-trivial fraction of developer merges verbatim while remaining broadly applicable.
minor comments (3)
- §4 (Evaluation): the definition of 'verbatim identical' merges should be stated explicitly, including how whitespace, comments, and formatting differences are treated; this directly affects interpretation of the 36% figure.
- §3.2 (Move rules): a short worked example showing token sequences before and after a function extraction would clarify how the move rules operate without language-specific knowledge.
- Table 1 or equivalent: the five baseline tools should be named and briefly characterized so readers can assess the fairness of the comparison.
Simulated Author's Rebuttal
We thank the referee for the positive summary and significance assessment of our work on Summer, and for recommending minor revision. No major comments were listed in the report, so there are no specific points requiring point-by-point rebuttal or changes to the manuscript.
Circularity Check
No significant circularity identified
full rationale
The paper presents a novel token-based merge algorithm (Summer) that formulates changes via string-rewriting and move rules, then reports empirical results on an external benchmark (ConflictBench) against five other tools. The central claims consist of measured performance metrics (36% verbatim accuracy, second in semantic accuracy) obtained through direct comparison on real-world scenarios. No load-bearing derivations, fitted parameters renamed as predictions, self-citation chains, or uniqueness theorems are invoked that reduce the reported outcomes to the inputs by construction. The algorithm description and evaluation setup remain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Paola Accioly, Paulo Borba, and Guilherme Cavalcanti. 2018. Understanding semi- structured merge conflict characteristics in open-source java projects.Empirical Software Engineering23, 4 (2018), 2051–2085
work page 2018
-
[2]
George W Adamson and Jillian Boreham. 1974. The use of an association measure based on character structure to identify semantically related pairs of words and document titles.Information storage and retrieval10, 7-8 (1974), 253–260
work page 1974
-
[3]
Sven Apel, Olaf Leßenich, and Christian Lengauer. 2012. Structured merge with auto-tuning: balancing precision and performance. InProceedings of the 27th IEEE/ACM International Conference on Automated Software Engineering. Association for Computing Machinery, New York, NY, USA, 120–129
work page 2012
-
[4]
Sven Apel, Jörg Liebig, Benjamin Brandl, Christian Lengauer, and Christian Käst- ner. 2011. Semistructured merge: rethinking merge in revision control systems. In Proceedings of the 19th ACM SIGSOFT symposium and the 13th European conference on Foundations of software engineering. Association for Computing Machinery, New York, NY, USA, 190–200
work page 2011
-
[5]
R Bates. 2002. Text editor interfaces for semantic editors.SBLP2002, VI Simpósio Brasileiro do Linguagens de Programmaçao(2002)
work page 2002
-
[6]
2025.wiggle - apply rejected patches and perform word-wise diffs
Neil Brown. 2025.wiggle - apply rejected patches and perform word-wise diffs. https://github.com/neilbrown/wiggle
work page 2025
-
[7]
Guilherme Cavalcanti, Paulo Borba, and Paola Accioly. 2017. Evaluating and improving semistructured merge.Proceedings of the ACM on Programming Lan- guages1, OOPSLA (2017), 1–27
work page 2017
-
[8]
Elizabeth Dinella, Todd Mytkowicz, Alexey Svyatkovskiy, Christian Bird, Mayur Naik, and Shuvendu Lahiri. 2022. Deepmerge: learning to merge programs.IEEE Transactions on Software Engineering49, 4 (2022), 1599–1614
work page 2022
-
[9]
2025.LastMerge: A language-agnostic structured tool for code integration
Joao Pedro Duarte, Paulo Borba, and Guilherme Cavalcanti. 2025.LastMerge: A language-agnostic structured tool for code integration. arXiv:2507.19687 [cs.SE] https://arxiv.org/abs/2507.19687
-
[10]
Max Ellis, Sarah Nadi, and Danny Dig. 2022. Operation-based refactoring-aware merging: an empirical evaluation.IEEE Transactions on Software Engineering49, 4 (2022), 2698–2721
work page 2022
-
[11]
Joseph Gentle and Martin Kleppmann. 2025. Collaborative Text Editing with Eg- walker: Better, Faster, Smaller. InProceedings of the Twentieth European Conference on Computer Systems. Association for Computing Machinery, New York, NY, USA, 311–328
work page 2025
-
[12]
Gleiph Ghiotto, Leonardo Murta, Márcio Barros, and Andre Van Der Hoek. 2018. On the nature of merge conflicts: a study of 2,731 open source Java projects hosted by GitHub.IEEE Transactions on Software Engineering46, 8 (2018), 892–915
work page 2018
-
[13]
Qiqi Gu and Mikoláš Janota. 2026. Source code of Improved ConflictBench. https://gitlab.com/token-based-merging/conflictbench
work page 2026
-
[14]
Qiqi Gu and Mikoláš Janota. 2026. Source code of Summer. https://gitlab.com/ token-based-merging/summer
work page 2026
-
[15]
Kaifeng Huang, Bihuan Chen, Xin Peng, Daihong Zhou, Ying Wang, Yang Liu, and Wenyun Zhao. 2018. Cldiff: generating concise linked code differences. In Proceedings of the 33rd ACM/IEEE international conference on automated software engineering. Association for Computing Machinery, New York, NY, USA, 679–690
work page 2018
-
[16]
Judah Jacobson. 2009. A formalization of darcs patch theory using inverse semigroups
work page 2009
-
[17]
Olaf Leßenich, Sven Apel, Christian Kästner, Georg Seibt, and Janet Siegmund
-
[18]
In2017 32nd IEEE/ACM International Conference on Automated Software Engineering (ASE)
Renaming and shifted code in structured merging: looking ahead for precision and performance. In2017 32nd IEEE/ACM International Conference on Automated Software Engineering (ASE). IEEE, IEEE, Urbana, IL, USA, 543–553
-
[19]
Mehran Mahmoudi, Sarah Nadi, and Nikolaos Tsantalis. 2019. Are refactorings to blame? an empirical study of refactorings in merge conflicts. In2019 IEEE 26th International Conference on Software Analysis, Evolution and Reengineering (SANER). IEEE, IEEE, Hangzhou, China, 151–162
work page 2019
-
[20]
Tom Mens. 2002. A state-of-the-art survey on software merging.IEEE transactions on software engineering28, 5 (2002), 449–462
work page 2002
-
[21]
Samuel Mimram and Cinzia Di Giusto. 2013. A categorical theory of patches. Electronic notes in theoretical computer science298 (2013), 283–307
work page 2013
-
[22]
Victor Cacciari Miraldo and Wouter Swierstra. 2019. An efficient algorithm for type-safe structural diffing.Proceedings of the ACM on Programming Languages 3, ICFP (2019), 1–29
work page 2019
-
[23]
Eugene W Myers. 1986. An O(ND) difference algorithm and its variations.Algo- rithmica1, 1 (1986), 251–266
work page 1986
-
[24]
Yusuf Sulistyo Nugroho, Hideaki Hata, and Kenichi Matsumoto. 2020. How different are different diff algorithms in Git?Empirical Software Engineering25 (2020), 790–823
work page 2020
-
[25]
Rangeet Pan, Vu Le, Nachiappan Nagappan, Sumit Gulwani, Shuvendu Lahiri, and Mike Kaufman. 2021. Can program synthesis be used to learn merge conflict resolutions? an empirical analysis. In2021 IEEE/ACM 43rd International Conference on Software Engineering (ICSE). IEEE, Madrid, Spain, 785–796
work page 2021
-
[26]
Ei Pa Pa Pe-Than, Laura Dabbish, and James D Herbsleb. 2018. Collaborative writing on GitHub: a case study of a book project. InCompanion of the 2018 ACM Conference on Computer Supported Cooperative Work and Social Computing. Association for Computing Machinery, New York, NY, USA, 305–308
work page 2018
-
[27]
David Roundy. 2005. Darcs: distributed version management in haskell. In Proceedings of the 2005 ACM SIGPLAN workshop on Haskell. Association for Computing Machinery, New York, NY, USA, 1–4
work page 2005
-
[28]
Georg Seibt, Florian Heck, Guilherme Cavalcanti, Paulo Borba, and Sven Apel
-
[29]
Leveraging structure in software merge: an empirical study.IEEE Transac- tions on Software Engineering48, 11 (2021), 4590–4610
work page 2021
-
[30]
Bowen Shen and Na Meng. 2024. ConflictBench: a benchmark to evaluate software merge tools.Journal of Systems and Software214 (2024), 112084
work page 2024
-
[31]
Bo Shen, Wei Zhang, Haiyan Zhao, Guangtai Liang, Zhi Jin, and Qianxiang Wang
-
[32]
IntelliMerge: a refactoring-aware software merging technique.Proceedings of the ACM on Programming Languages3, OOPSLA (2019), 1–28
work page 2019
-
[33]
Chaochao Shen, Wenhua Yang, Minxue Pan, and Yu Zhou. 2023. Git merge conflict resolution leveraging strategy classification and LLM. In2023 IEEE 23rd International Conference on Software Quality, Reliability, and Security (QRS). IEEE, Chiang Mai, Thailand, 228–239
work page 2023
-
[34]
Martin Sjölund. 2021. Evaluating a tree diff algorithm for use in modelica tools. In Modelica Conferences. Linköping University Electronic Press, Linköping, Sweden, 529–537
work page 2021
-
[35]
Alexey Svyatkovskiy, Sarah Fakhoury, Negar Ghorbani, Todd Mytkowicz, Eliza- beth Dinella, Christian Bird, Jinu Jang, Neel Sundaresan, and Shuvendu K Lahiri
-
[36]
Program merge conflict resolution via neural transformers. InProceedings of the 30th ACM joint European software engineering conference and symposium on the foundations of software engineering. Association for Computing Machinery, New York, NY, USA, 822–833
-
[37]
Walter F Tichy. 1984. The string-to-string correction problem with block moves. ACM Transactions on Computer Systems (TOCS)2, 4 (1984), 309–321
work page 1984
-
[38]
Gustavo Vale, Claus Hunsen, Eduardo Figueiredo, and Sven Apel. 2021. Chal- lenges of resolving merge conflicts: a mining and survey study.IEEE Transactions on Software Engineering48, 12 (2021), 4964–4985
work page 2021
-
[39]
Kaizhong Zhang and Tao Jiang. 1994. Some MAX SNP-hard results concerning unordered labeled trees.Inform. Process. Lett.49, 5 (1994), 249–254
work page 1994
-
[40]
Fengmin Zhu, Fei He, and Qianshan Yu. 2019. Enhancing precision of structured merge by proper tree matching. In2019 IEEE/ACM 41st International Conference on Software Engineering: Companion Proceedings (ICSE-Companion). IEEE, Montreal, QC, Canada, 286–287
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.