Finite-Step Bounds for Iterated Correlation Matrices
Pith reviewed 2026-05-10 11:54 UTC · model grok-4.3
The pith
Probabilistic upper bounds on finite-step expansion ratios for Pearson correlation matrix iterations hold with at least 95 percent coverage.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
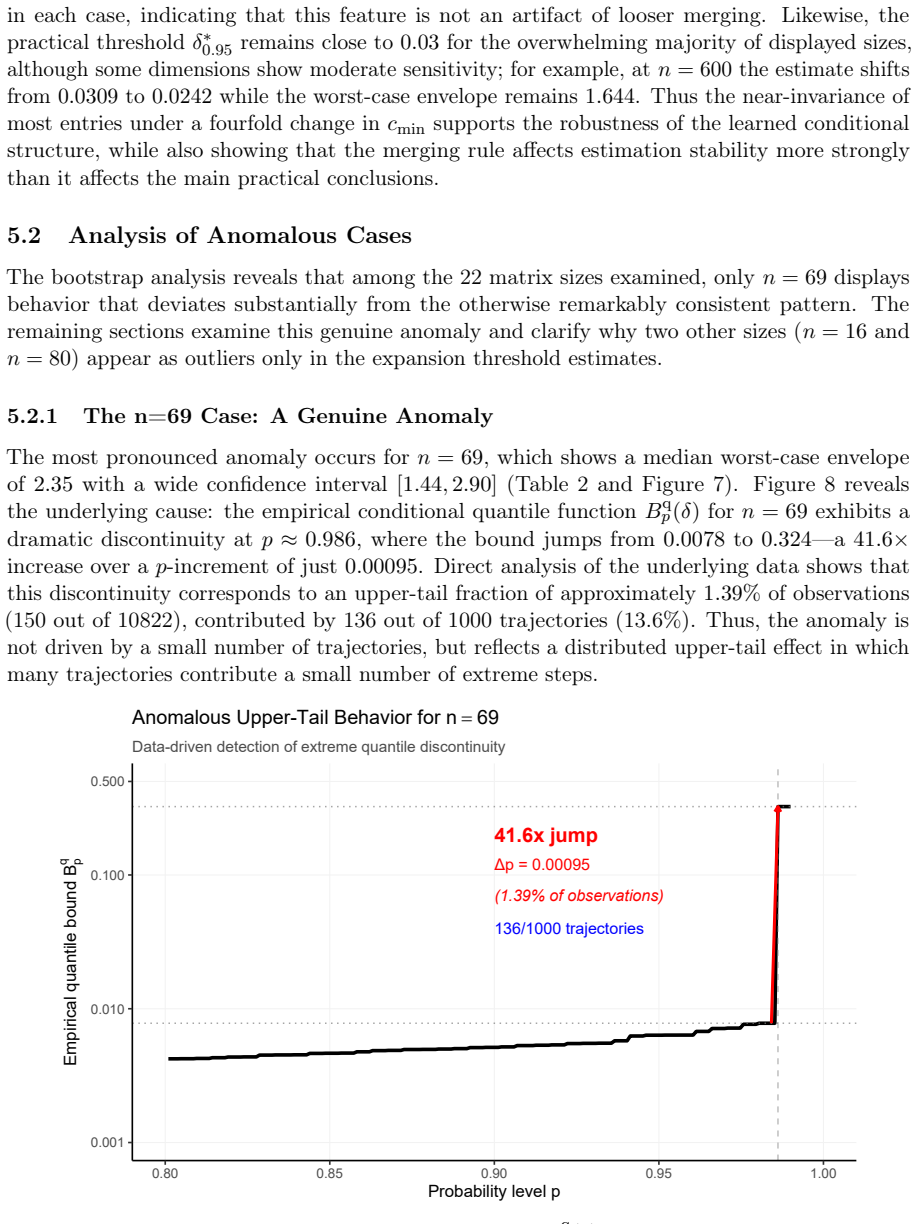
For the sequence of matrices generated by the Pearson update, the ratios ρ_k = Δ_{k+1}/Δ_k satisfy P(ρ_k ≤ B_p(δ_k)) ≥ p where δ_k = Δ_k/n and the functions B_p are empirical conditional p-quantiles of log ρ_k given δ_k under logarithmic binning; the baseline 0.95-quantile version yields P(ρ ≤ 1 | δ ≤ 0.03) ≥ 0.95 uniformly in n and P(ρ ≤ 1.7) ≥ 0.95 for 21 of 22 dimensions, with one exceptional dimension reaching 2.35.
What carries the argument
State-dependent bounds B_p(δ) formed as empirical conditional p-quantiles of log ρ_k conditioned on δ_k under logarithmic binning, with larger families obtained by multiplicative adjustments that preserve the δ-dependence.
If this is right
- The bounds apply uniformly over all tested n when the current difference is small.
- Empirical coverage on held-out trajectories matches the nominal probability levels for every n from 3 to 2000.
- A single dimension exhibits a higher extreme tail not predicted by asymptotics.
- The bounds capture finite expansions that are invisible under local linearization of the iteration.
Where Pith is reading between the lines
- The same quantile construction could be applied to derive explicit finite-time guarantees on total convergence distance.
- Similar state-dependent bounds might be obtainable for other iterated matrix maps used in multivariate statistics.
- The observed dimension-specific tail discontinuity invites exact analysis of the distribution of ρ for that particular n.
- Testing the bounds under non-uniform or structured initial matrices would check their sensitivity to the uniform-start assumption.
Load-bearing premise
Empirical conditional quantiles computed from i.i.d. uniform initializations under logarithmic binning accurately represent the true probabilities of the Pearson update ratios for every tested matrix size.
What would settle it
New independent trajectories with fresh initializations or larger n in which the fraction of steps violating the claimed 0.95 coverage at small δ exceeds 5 percent would falsify the bounds.
Figures







read the original abstract
We establish finite-step probabilistic upper bounds on the contraction ratios $\rho_k = \Delta_{k+1}/\Delta_k$ for iterated Pearson correlation dynamics. Let $(P_k)_{k\ge 0}$ be the sequence generated by the Pearson update. Define $\Delta_k := \|P_{k+1}-P_k\|_F$, $\rho_k := \Delta_{k+1}/\Delta_k$ for $\Delta_k > 0$, and $\delta_k := \Delta_k/n$. Although $\Delta_k \to 0$ along convergent trajectories, the ratios $\rho_k$ may exceed unity in finitely many steps. This behavior is invisible to local linearization. Our main contribution is a probabilistic bounding framework that captures these finite-step expansions. We initialize $P_0$ with i.i.d. $\mathcal{U}[-1,1]$ entries and let $\mathbb{P}$ be the induced measure. For $k \ge 2$, we construct state-dependent bounds $B_p : \mathbb{R}_+ \to \mathbb{R}_+$ satisfying $\mathbb{P}(\rho_k \le B_p(\delta_k)) \ge p$. The functions $B^{\mathrm{q}}_p(\delta)$ are empirical conditional $p$-quantiles of $\log \rho_k$ given $\delta_k$ under logarithmic binning. Larger families $B^{\mathrm{TC}}_{p,\tau}(\delta)$ and $B^{\mathrm{tol}}_{p,\tau}(\delta)$ are obtained via multiplicative adjustments, yielding pointwise larger bounds that preserve the $\delta$-dependence. Validation on held-out trajectories confirms the bounds hold with empirical coverage matching nominal levels for all $n \in [3,2000]$. The baseline $0.95$-quantile bound $B^{\mathrm{q}}_{0.95}(\delta)$ yields two concrete results: $\mathbb{P}(\rho \le 1 \mid \delta \le 0.03) \ge 0.95$ uniformly in $n$, and $\mathbb{P}(\rho \le 1.7) \ge 0.95$ for 21 of 22 dimensions. The exception $n = 69$ attains $2.35$, revealing a rare extreme upper tail discontinuity not captured by asymptotic analysis. These are the first finite-step probabilistic bounds for Pearson correlation dynamics. The framework is fully reproducible with provided code and data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a probabilistic framework for bounding the finite-step contraction ratios ρ_k = Δ_{k+1}/Δ_k in iterated Pearson correlation matrix updates. Starting from i.i.d. uniform initializations, it constructs state-dependent bounds B_p(δ) as empirical conditional p-quantiles of log ρ_k given δ_k = Δ_k/n using logarithmic binning from Monte Carlo simulations. These bounds are validated on held-out trajectories, yielding P(ρ_k ≤ B_p(δ_k)) ≥ p, with specific results such as P(ρ ≤ 1 | δ ≤ 0.03) ≥ 0.95 uniformly over n ∈ [3,2000] and P(ρ ≤ 1.7) ≥ 0.95 for 21 out of 22 tested dimensions.
Significance. If the empirical bounds hold as stated, the paper provides the first finite-step probabilistic upper bounds on the expansion ratios in Pearson correlation dynamics, addressing a gap left by asymptotic and local analyses. The extensive simulation study across dimensions up to 2000, combined with held-out validation and full reproducibility via provided code and data, makes this a valuable contribution to the study of iterative matrix processes and convergence behavior in high-dimensional statistics.
major comments (2)
- [Section on bound construction and the δ ≤ 0.03 claim] The baseline bound B^q_0.95(δ) is defined as the empirical conditional 0.95-quantile of log ρ_k given δ_k under logarithmic binning. For the key regime δ ≤ 0.03, bin occupancy is necessarily limited even with many trajectories, which can cause the sample quantile to underestimate the true 0.95-quantile. The held-out validation confirms coverage only under the same sampling distribution and does not rule out systematic undercoverage due to sparsity. This is load-bearing for the central claim of a verified probabilistic guarantee. Report bin sample sizes for δ ≤ 0.03 and consider bootstrap variability or a minimum occupancy threshold.
- [Results on dimension-specific bounds and n=69 exception] The reported exception at n=69 where the bound reaches 2.35 instead of 1.7 suggests possible dimension-dependent tail discontinuities not fully captured by the uniform binning approach. This warrants further investigation into whether the logarithmic binning resolution or simulation length is adequate for rare events in higher dimensions.
minor comments (2)
- The manuscript should specify the exact parameters used for logarithmic binning (e.g., number of bins, bin edges) and the values of the multiplicative adjustment τ in the extended families B^TC and B^tol.
- Include a table or figure caption detailing the number of Monte Carlo trajectories used for fitting and validation separately.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments on our manuscript. We address each major comment point by point below, indicating the revisions we will make to strengthen the presentation of the empirical bounds.
read point-by-point responses
-
Referee: The baseline bound B^q_0.95(δ) is defined as the empirical conditional 0.95-quantile of log ρ_k given δ_k under logarithmic binning. For the key regime δ ≤ 0.03, bin occupancy is necessarily limited even with many trajectories, which can cause the sample quantile to underestimate the true 0.95-quantile. The held-out validation confirms coverage only under the same sampling distribution and does not rule out systematic undercoverage due to sparsity. This is load-bearing for the central claim of a verified probabilistic guarantee. Report bin sample sizes for δ ≤ 0.03 and consider bootstrap variability or a minimum occupancy threshold.
Authors: We acknowledge that limited sample sizes in logarithmic bins for small δ may affect the precision of empirical quantile estimates. While the held-out validation on independent trajectories empirically confirms coverage at or above the nominal level, we agree this does not fully address potential sparsity effects. In the revision we will add a table reporting the number of observations per bin for δ ≤ 0.03 across the simulated dimensions. We will also compute and report bootstrap standard errors for the 0.95-quantile estimates in this regime to quantify variability. These additions will be placed in the section on bound construction and do not change the main claims, which rest on the validated coverage. revision: yes
-
Referee: The reported exception at n=69 where the bound reaches 2.35 instead of 1.7 suggests possible dimension-dependent tail discontinuities not fully captured by the uniform binning approach. This warrants further investigation into whether the logarithmic binning resolution or simulation length is adequate for rare events in higher dimensions.
Authors: The n=69 exception is deliberately reported in the manuscript to demonstrate the existence of rare, dimension-specific tail discontinuities that are invisible to asymptotic analysis. The held-out validation already verifies that the stated probabilistic guarantees hold for this dimension as well. We agree that fixed logarithmic binning has inherent limitations for extremely rare events, and we will add a concise discussion of this point in the results section. However, we do not believe the current simulation length or binning resolution requires further expansion for the scope of this work, as the framework is designed to surface rather than eliminate such dimension-dependent behaviors. revision: partial
Circularity Check
No significant circularity in derivation chain
full rationale
The paper defines the bounding functions explicitly as empirical conditional p-quantiles of log ρ_k given δ_k, computed from finite simulation trajectories under logarithmic binning. These constructed B functions are then subjected to separate validation on held-out independent trajectories, where empirical coverage is reported to match nominal levels. No equation or central claim reduces the asserted probabilistic inequalities to a tautology by construction, nor does any step rely on self-citation chains, imported uniqueness theorems, or ansatzes smuggled from prior work. The framework is presented as an empirical bounding procedure whose guarantees rest on the reproducibility of the simulation and validation pipeline rather than definitional equivalence.
Axiom & Free-Parameter Ledger
free parameters (3)
- quantile level p
- logarithmic binning parameters
- multiplicative adjustment τ
axioms (2)
- domain assumption The Pearson update generates a well-defined sequence of symmetric matrices with entries in [-1,1]
- domain assumption Δ_k → 0 along convergent trajectories
Reference graph
Works this paper leans on
-
[1]
I. Alhajj Hassan. Empirical laws for iterated correlation matrices.arXiv preprint arXiv:2512.15421, 2025. https://arxiv.org/abs/2512.15421
-
[2]
I. Alhajj Hassan. Finite-Step Conditional Bounds for Iterated Pearson Correlation. Zenodo, v2.0.0, 2026. https://doi.org/10.5281/zenodo.19224989
-
[3]
I. Alhajj Hassan. Computational Framework for Experiments on Iterated Correlation Matrices. Zenodo, v1.0.0, 2025. https://doi.org/10.5281/zenodo.17794063
-
[4]
R. L. Breiger, S. A. Boorman, and P. Arabie. An algorithm for clustering relational data with applications to social network analysis and comparison with multidimensional scaling. Journal of Mathematical Psychology, 12(3):328–383, 1975. https://doi.org/10.1016/0022-249 6(75)90028-0
-
[5]
C.-C. Chen. Generalized association plots: Information visualization via iteratively generated correlation matrices.Statistica Sinica, 12(1):7–29, 2002. http://www3.stat.sinica.edu.tw/st atistica/. 24
work page 2002
-
[6]
L. Huang, D. Yang, and B. Lang. Iterative normalization: Beyond standardization towards efficient whitening. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 4874–4883, 2019. https://openaccess.thecvf.com/content_CV PR_2019/html/Huang_Iterative_Normalization_Beyond_Standardization_Towards_ Efficient_Whitening_C...
work page 2019
-
[7]
J. B. Kruskal. A theorem about CONCOR. Technical Report MH 2C–571, Bell Laboratories, Murray Hill, NJ, 1978
work page 1978
-
[8]
L. L. McQuitty. Multiple clustering revisited: Comments, comparisons, new approaches. Multivariate Behavioral Research, 3(4):431–479, 1968. https://doi.org/10.1207/s15327906m br0304_1
-
[9]
M. H. Schneider. Matrix scaling, entropy minimization, and conjugate duality.Linear Algebra and its Applications, 151:1–23, 1991. https://doi.org/10.1016/0024-3795(91)90352-E
-
[10]
N. N. Taleb and P. Cirillo. The regress of uncertainty and the forecasting paradox.Risks, 13(12):247, 2025. https://doi.org/10.3390/risks13120247
-
[11]
A. W. van der Vaart.Asymptotic Statistics. Cambridge University Press, 1998. 25
work page 1998
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.