Empirical Evaluation of Policy-Based Reinforcement Learning for Dynamic Service Control in an M/M/1 Queue
Pith reviewed 2026-05-10 12:10 UTC · model grok-4.3
The pith
Three policy-based RL algorithms learn to control service rates in an M/M/1 queue.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Three policy-based reinforcement learning algorithms, namely REINFORCE, Actor-Critic (A2C), and Proximal Policy Optimization (PPO), are trained in a simulated environment using two state representations: the instantaneous queue length and an augmented state that includes a one-step queue history. Performance is evaluated in terms of convergence speed, sampling efficiency, policy quality, and pseudo-regret relative to the steady-state optimum.
What carries the argument
The semi-Markov decision process (SMDP) in which the agent chooses a service rate from a finite set at the start of each new service to minimize an objective combining system congestion and energy costs.
If this is right
- The trained policies would achieve lower combined costs than any fixed service rate when arrival rates vary.
- An augmented state with queue history would allow policies to react to recent trends rather than only the present length.
- PPO is expected to require fewer samples than REINFORCE due to its clipped objective for stable updates.
- These methods could be used to manage resources in computing clusters or manufacturing lines without solving the full optimization problem analytically.
Where Pith is reading between the lines
- Extending the state to include more history or arrival rate estimates might further improve performance in non-stationary environments.
- Testing the approach on multi-server queues would show if the same algorithms scale without major changes.
- If the learned policies are deployed online, monitoring their regret in real time could provide a way to detect when retraining is needed.
Load-bearing premise
The assumption that decisions about service rates are made only when a new customer begins service and that the cost function properly balances congestion penalties with energy use.
What would settle it
If long-running simulations of the learned policies show average costs higher than those from the optimal steady-state service rate, the evaluation would indicate that the algorithms did not find better dynamic controls.
Figures
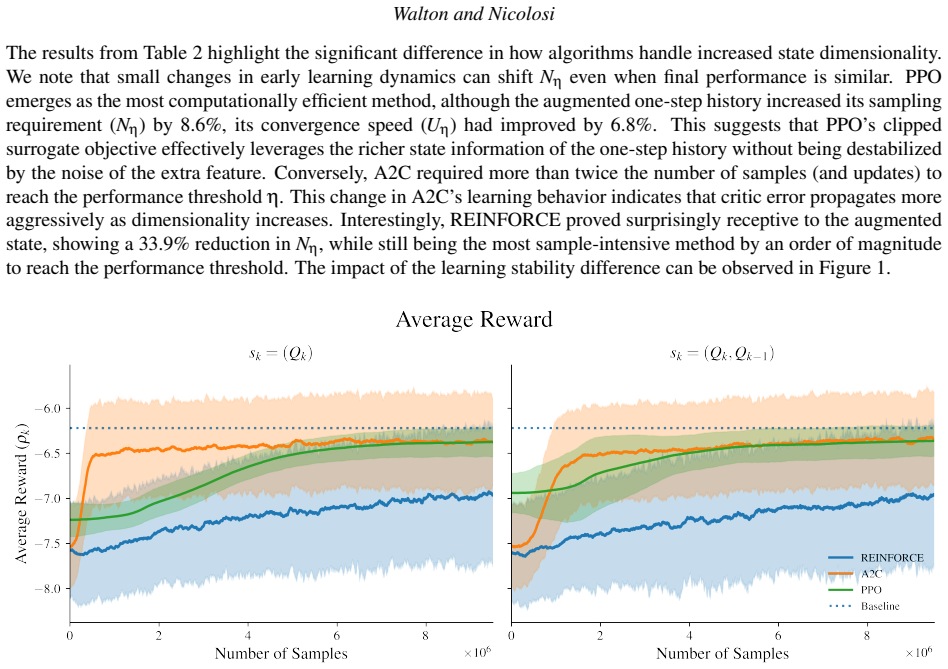
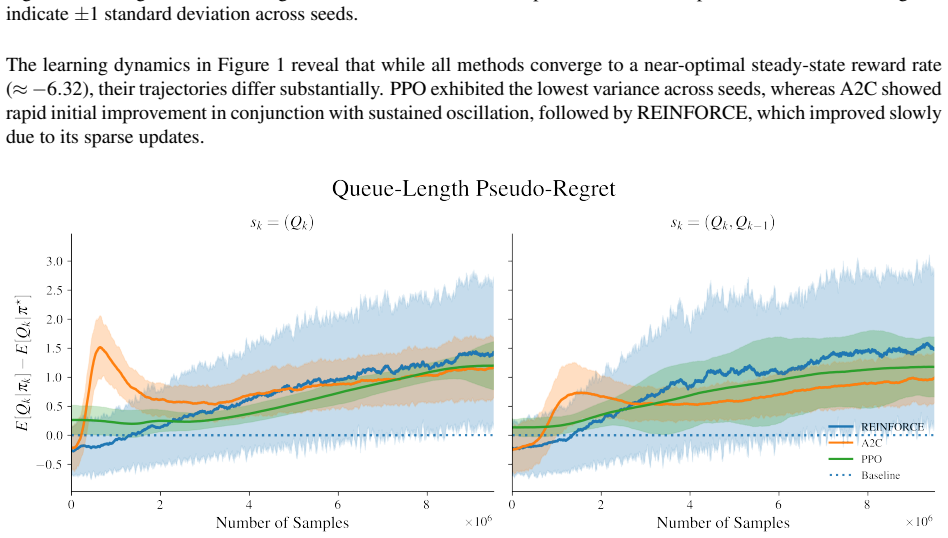
read the original abstract
While reinforcement learning has been increasingly applied to stochastic control, few studies have systematically examined policy-based methods in queuing environments modeled as a semi-Markov decision process (SMDP). To address this gap, we investigate how policy-based reinforcement learning (RL) algorithms perform when applied to the control of service rates in an M/M/1 queue, a common queuing model for manufacturing, computing, and service systems. The problem is formulated as an SMDP in which decisions occur at each new service, allowing an agent to select different service rates from a finite set of speeds, aiming to minimize an objective function that manages system congestion and energy costs. Three policy-based reinforcement learning algorithms, namely REINFORCE, Actor-Critic (A2C), and Proximal Policy Optimization (PPO), are trained in a simulated environment using two state representations: the instantaneous queue length and an augmented state that includes a one-step queue history. Performance is evaluated in terms of convergence speed, sampling efficiency, policy quality, and pseudo-regret relative to the steady-state optimum.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper empirically evaluates three policy-based RL algorithms (REINFORCE, A2C, and PPO) applied to dynamic service-rate control in an M/M/1 queue formulated as an SMDP. Decisions occur at service completions, with the agent selecting from a finite set of service rates to minimize a combined congestion-plus-energy cost. Two state representations are tested (instantaneous queue length and one-step history augmentation). Algorithms are trained via simulation and compared on convergence speed, sampling efficiency, policy quality, and pseudo-regret relative to a steady-state optimum.
Significance. If the reported performance differences hold under a correctly computed benchmark, the study supplies useful empirical guidance on the relative strengths of policy-gradient methods in a canonical stochastic control setting. The SMDP formulation and dual state representations are reasonable choices that align with standard practice in queueing control. The work is primarily incremental rather than foundational, as it applies known algorithms without new theoretical results or parameter-free derivations.
major comments (2)
- [Evaluation methodology] Evaluation methodology (implicit in abstract and results description): The pseudo-regret is reported relative to an unspecified 'steady-state optimum.' In an SMDP whose optimal long-run average cost is obtained by solving the optimality equations over the countable state space, it is essential to clarify whether the benchmark is (i) the optimal dynamic policy or (ii) merely the best fixed service rate. If the latter, the metric does not bound suboptimality of the learned policies and cannot support claims about policy quality.
- [Experimental design] Experimental design: No information is given on the number of independent runs, variance of the reported metrics, or statistical tests used to compare convergence speed and sampling efficiency across REINFORCE, A2C, and PPO. Without these, the comparative claims rest on single-run trajectories whose reliability cannot be assessed.
minor comments (2)
- [Abstract] Abstract: The phrase 'pseudo-regret relative to the steady-state optimum' should be accompanied by a brief definition or citation to the relevant RL literature (e.g., regret definitions in average-cost SMDPs).
- [Problem formulation] Notation: The objective function combining congestion and energy costs is described only qualitatively; an explicit mathematical expression (e.g., holding cost plus power cost) would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address the major comments point by point below, providing clarifications and indicating the revisions we will implement.
read point-by-point responses
-
Referee: [Evaluation methodology] Evaluation methodology (implicit in abstract and results description): The pseudo-regret is reported relative to an unspecified 'steady-state optimum.' In an SMDP whose optimal long-run average cost is obtained by solving the optimality equations over the countable state space, it is essential to clarify whether the benchmark is (i) the optimal dynamic policy or (ii) merely the best fixed service rate. If the latter, the metric does not bound suboptimality of the learned policies and cannot support claims about policy quality.
Authors: We agree that the benchmark must be explicitly defined. In the manuscript, the 'steady-state optimum' denotes the best fixed service rate: for each candidate rate we compute the long-run average cost under the M/M/1 steady-state distribution and retain the minimum. This is not the optimal dynamic policy, which would require solving the SMDP optimality equations over the countable state space. We acknowledge that the pseudo-regret therefore measures improvement relative to the best static policy rather than a bound on suboptimality to the true optimum. We will revise the abstract, Section 3, and the results discussion to state this definition clearly, explain its computation, note the computational difficulty of the dynamic optimum, and adjust all claims about policy quality accordingly. revision: yes
-
Referee: [Experimental design] Experimental design: No information is given on the number of independent runs, variance of the reported metrics, or statistical tests used to compare convergence speed and sampling efficiency across REINFORCE, A2C, and PPO. Without these, the comparative claims rest on single-run trajectories whose reliability cannot be assessed.
Authors: We accept this criticism. All reported curves and tables were obtained from 10 independent runs with distinct random seeds; means and standard deviations are shown in the figures, and pairwise Welch t-tests were used to assess statistical significance of differences in convergence speed and final performance. We will add a dedicated paragraph in the Experimental Setup section (and a short note in the caption of each results figure) that states the number of runs, how variance is reported, and the statistical procedure employed. revision: yes
Circularity Check
No circularity: purely empirical simulation study with independent benchmark
full rationale
The paper is an empirical evaluation of REINFORCE, A2C, and PPO on an M/M/1 queue formulated as an SMDP. It reports simulation-based metrics (convergence speed, sampling efficiency, policy quality, pseudo-regret) without any claimed mathematical derivations, fitted parameters presented as predictions, or self-citation chains. The steady-state optimum benchmark is computed separately (standard DP solution for the countable-state average-cost problem) and does not reduce to the RL training data or outputs by construction. No self-definitional steps, ansatzes, or renamings appear in the provided abstract or description.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The M/M/1 queue can be modeled as a semi-Markov decision process with decisions at service initiation points.
Reference graph
Works this paper leans on
-
[1]
Optimal Control of a Queue with variable Service Rates,
T. B. Crabill, “Optimal Control of a Queue with variable Service Rates,” Ph.D. dissertation, Cornell University, 1969
work page 1969
-
[2]
H. Sabeti, “Optimal Decision in Queueing,” California University, Berkeley, Operations Research Center, Tech. Rep., 1970
work page 1970
-
[3]
Dynamic Control of a Queue with Adjustable Service Rate,
J. M. George and J. M. Harrison, “Dynamic Control of a Queue with Adjustable Service Rate,”Operations Research, vol. 49, no. 5, pp. 720–731, 2001
work page 2001
-
[4]
T. B. Crabill, “Optimal Control of a Service Facility with Variable Exponential Service Times and Constant Arrival Rate,”Management Science, vol. 18, no. 9, pp. 560–566, 1972
work page 1972
-
[5]
M. L. Puterman,Markov Decision Processes: Discrete Stochastic Dynamic Programming, ser. Wiley Series in Probability and Statistics. John Wiley & Sons, Inc, 1994
work page 1994
-
[6]
Adaptive service rate control of an M/M/1 queue with server breakdowns,
Y . Zheng, J. Julaiti, and G. Pang, “Adaptive service rate control of an M/M/1 queue with server breakdowns,” Queueing Systems, vol. 106, no. 1-2, pp. 159–191, 2024
work page 2024
-
[7]
Queueing Network Controls via Deep Reinforcement Learning,
J. G. Dai and M. Gluzman, “Queueing Network Controls via Deep Reinforcement Learning,”Stochastic Systems, vol. 12, no. 1, pp. 30–67, 2022
work page 2022
-
[8]
Simple statistical gradient-following algorithms for connectionist reinforcement learning,
R. J. Williams, “Simple statistical gradient-following algorithms for connectionist reinforcement learning,”Ma- chine Learning, vol. 8, no. 3, pp. 229–256, 1992
work page 1992
-
[9]
V . R. Konda and J. N. Tsitsiklis, “Actor-Critic Algorithms,” inAdvances in Neural Information Processing Sys- tems, 1999
work page 1999
-
[10]
Proximal Policy Optimization Algorithms,
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal Policy Optimization Algorithms,” 2017
work page 2017
-
[11]
Regret Analysis of Stochastic and Nonstochastic Multi-armed Bandit Prob- lems,
S. Bubeck and N. Cesa-Bianchi, “Regret Analysis of Stochastic and Nonstochastic Multi-armed Bandit Prob- lems,”F oundations and Trends® in Machine Learning, vol. 5, no. 1, pp. 1–122, 2012
work page 2012
-
[12]
Learning Algorithms for Minimizing Queue Length Regret,
T. Stahlbuhk, B. Shrader, and E. Modiano, “Learning Algorithms for Minimizing Queue Length Regret,”IEEE Transactions on Information Theory, vol. 67, no. 3, pp. 1759–1781, 2021
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.