Learning to traverse convective flows at moderate to high Rayleigh numbers
Pith reviewed 2026-05-10 10:45 UTC · model grok-4.3
The pith
A reinforcement learning agent learns to navigate convective turbulence by crossing repelling barriers and riding attracting pathways.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
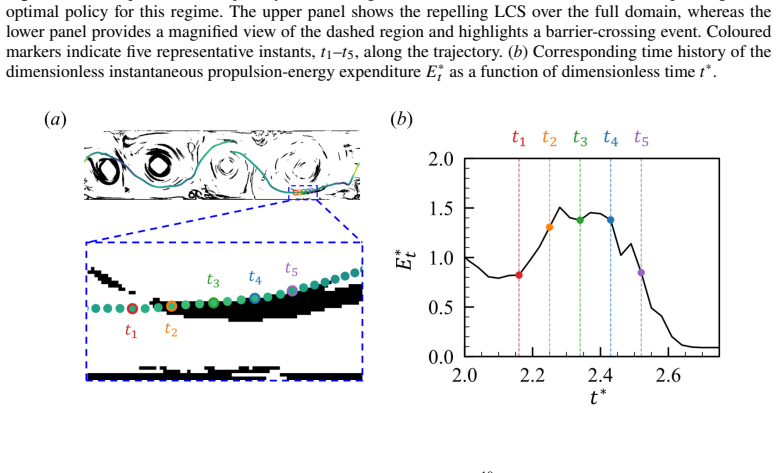
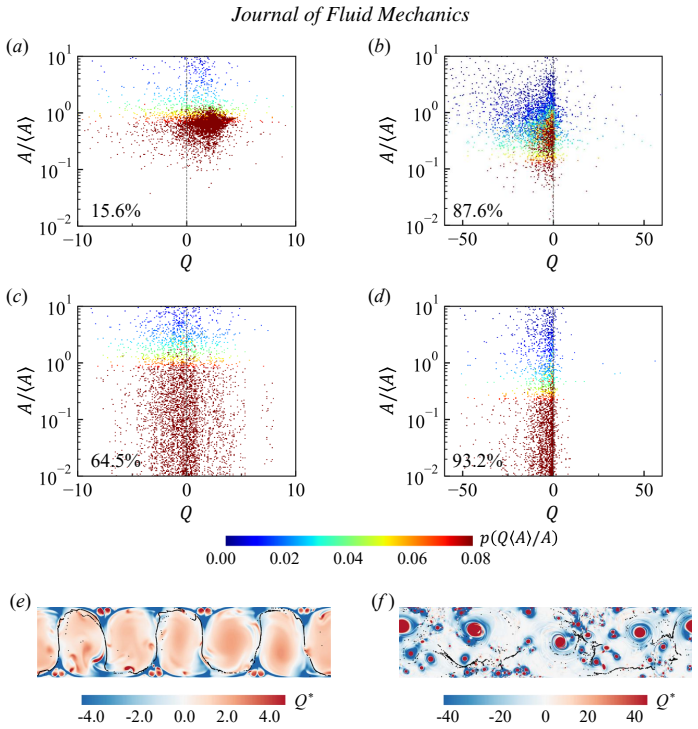
In 2D Rayleigh-Bénard convection the RL agent inherently learns to cross repelling Lagrangian barriers and surf along attracting pathways. Proper orthogonal decomposition shows that performance differences arise from reorganization of the carrier flow: at moderate Ra dominant large-scale circulation partitions the domain through robust barriers, while at higher Ra energy spreads across many modes, barriers fragment, and plume-assisted pathways emerge. Mapping the observed behaviors onto local Eulerian flow topology with Voronoi tessellation and the Q-criterion distils an interpretable heuristic strategy that achieves robust navigability with lower energy than constant-heading baselines.
What carries the argument
The bounded-acceleration reinforcement-learning policy whose actions are interpreted through Lagrangian coherent structure analysis, proper orthogonal decomposition of the velocity field, and Eulerian topology measures (Voronoi tessellation and Q-criterion).
If this is right
- Success rate increases abruptly with maximum acceleration at moderate Ra but shifts to larger values and becomes more gradual at high Ra.
- Although completion time grows with Ra, the propulsion energy required for successful traversal decreases because of flow reorganization.
- The learned policy consumes significantly less energy than constant-heading control by aligning with local currents.
- At higher Ra, transient plume-assisted pathways emerge as transport barriers fragment.
- A simple heuristic distilled from local Eulerian flow topology achieves comparable robust navigability.
Where Pith is reading between the lines
- The same controller might transfer to 3D convection or laboratory cells if the key topological features (barrier crossing and plume riding) persist across dimensionality.
- The distilled heuristic could guide design of energy-efficient autonomous vehicles in other turbulent flows such as ocean currents or atmospheric convection.
- Testing whether the RL-discovered behaviors survive changes in Prandtl number or cell aspect ratio would reveal how sensitive the strategy is to the carrier flow details.
- The observed drop in required energy at high Ra suggests similar navigation advantages may appear in other high-Ra regimes once barriers fragment.
Load-bearing premise
The navigation behaviors learned in this fixed 2D incompressible setup at Pr=0.71 and aspect ratio 4 remain useful when the same controller is placed in 3D convection or laboratory experiments.
What would settle it
If the distilled heuristic strategy fails to produce robust horizontal navigation when implemented in a 3D Rayleigh-Bénard simulation at the same range of Rayleigh numbers, the claim that the learned behaviors generalize would be falsified.
Figures


















read the original abstract
We study the navigation of a self-propelled inertial particle in two-dimensional Rayleigh--B\'enard convection at Prandtl number $Pr = 0.71$ and cell aspect ratio $\Gamma = 4$ for Rayleigh numbers $Ra$ ranging from $10^{7}$ to $10^{11}$. A reinforcement-learning (RL) controller selects the propulsive acceleration, subject to an upper bound $\mathcal{A}_{\max}$, to achieve a prescribed horizontal displacement. We find that the success rate increases abruptly with $\mathcal{A}_{\max}$ at moderate $Ra$, whereas at higher $Ra$ the transition becomes more gradual and shifts to larger $\mathcal{A}_{\max}$. Moreover, although the completion time increases with $Ra$, the propulsion energy required for successful traversal decreases. Proper orthogonal decomposition (POD) reveals that these performance differences arise from reorganisation of the carrier flow. At moderate $Ra$, the dominant large-scale circulation partitions the domain through robust transport barriers, requiring a finite thrust surplus to cross them; at higher $Ra$, energy is distributed across many modes, the barriers fragment, and transient plume-assisted pathways emerge. Compared with a constant-heading baseline, the learned policy aligns with local currents and consumes significantly less energy. Lagrangian coherent structure (LCS) analysis further shows that the RL agent inherently learns to cross repelling barriers and surf along attracting pathways. Finally, by mapping these behaviours onto the local Eulerian flow topology using Voronoi tessellation and the $Q$-criterion, we distil an interpretable, physics-based heuristic strategy that achieves robust navigability. These results connect turbulent-flow organisation with autonomous navigation under bounded actuation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper studies reinforcement learning control of a self-propelled inertial particle navigating horizontal displacement in 2D Rayleigh-Bénard convection (Pr=0.71, Γ=4, Ra=10^7 to 10^11). It reports that success rate transitions with A_max become more gradual and shift higher at larger Ra, while required propulsion energy decreases despite longer completion times. POD shows flow reorganization from robust large-scale barriers at moderate Ra to fragmented barriers and plume pathways at high Ra. LCS analysis indicates the RL policy crosses repelling structures and follows attracting ones; mapping these behaviors via Voronoi tessellation and the Q-criterion is claimed to yield an interpretable heuristic that itself achieves robust navigability. Comparisons to constant-heading control are also presented.
Significance. If substantiated, the work is significant for linking RL-derived navigation strategies to concrete Lagrangian and Eulerian flow structures in high-Ra convection. The combination of POD, LCS, and topology-based heuristic extraction provides a template for interpreting data-driven controllers in turbulent flows and could inform bounded-actuation navigation in convective environments. The observation that energy cost decreases with Ra while success improves via transient pathways is a potentially useful physical insight.
major comments (2)
- [Abstract / heuristic distillation section] Abstract and the section describing the heuristic extraction: the claim that the Voronoi/Q-criterion mapping 'distils an interpretable, physics-based heuristic strategy that achieves robust navigability' is not supported by direct evidence. The manuscript presents a post-hoc correlation between RL trajectories and local Eulerian topology but does not report results from deploying the extracted rule (e.g., a Q-sign and Voronoi-cell-based policy) as a standalone controller and comparing its success rates, energy, and barrier-crossing statistics to the RL agent across the Ra range.
- [Results (RL performance metrics)] Results section on RL performance: the reported abrupt/gradual transitions in success rate, the decrease in propulsion energy with Ra, and the superiority over constant-heading control are presented without error bars, statistics from multiple independent training runs, or ablation checks on state representation, reward formulation, or network architecture. This makes it impossible to assess whether the trends are robust or sensitive to training stochasticity.
minor comments (2)
- [Throughout] The notation for the actuation bound (A_max vs script A_max) should be unified for clarity.
- [Figures showing LCS and topology] Figure captions for the LCS and Voronoi visualizations would benefit from explicit arrows or annotations linking specific RL trajectory segments to the identified repelling/attracting structures.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments highlight important points on evidence strength and statistical robustness, which we address below with planned revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract / heuristic distillation section] Abstract and the section describing the heuristic extraction: the claim that the Voronoi/Q-criterion mapping 'distils an interpretable, physics-based heuristic strategy that achieves robust navigability' is not supported by direct evidence. The manuscript presents a post-hoc correlation between RL trajectories and local Eulerian topology but does not report results from deploying the extracted rule (e.g., a Q-sign and Voronoi-cell-based policy) as a standalone controller and comparing its success rates, energy, and barrier-crossing statistics to the RL agent across the Ra range.
Authors: We agree that the current wording overstates the direct validation of the extracted heuristic. The mapping was performed post-hoc to interpret the RL policy's observed behaviors (crossing repelling LCS and following attracting ones), and its consistency with successful navigation is supported by the LCS and POD analyses. However, we did not implement or benchmark the rule-based policy as a standalone controller. In revision we will modify the abstract and heuristic section to state that the mapping 'yields a candidate interpretable heuristic whose alignment with the RL trajectories suggests it may support robust navigability,' and we will add a short discussion of how the rule could be implemented. We will also include a limited comparison of a simple Q/Voronoi-based policy against the RL agent for one or two Ra values if computational resources allow. revision: partial
-
Referee: [Results (RL performance metrics)] Results section on RL performance: the reported abrupt/gradual transitions in success rate, the decrease in propulsion energy with Ra, and the superiority over constant-heading control are presented without error bars, statistics from multiple independent training runs, or ablation checks on state representation, reward formulation, or network architecture. This makes it impossible to assess whether the trends are robust or sensitive to training stochasticity.
Authors: We concur that the absence of error bars and multi-seed statistics limits assessment of robustness. In the revised manuscript we will rerun the RL training for each Ra with at least five independent random seeds, report mean success rates, energy, and completion times with standard-deviation error bars, and add a short subsection on sensitivity to state representation and reward weights. These additions will appear in the main Results section and supplementary material. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper trains an RL controller on direct numerical simulations of 2D Rayleigh-Bénard convection, then applies post-processing (POD, LCS, Voronoi tessellation, Q-criterion) to interpret the learned policy and distill a heuristic. No central result is obtained by fitting a parameter to data and then re-using that same parameter as a 'prediction'; no self-definitional loop exists where a quantity is defined in terms of itself; and no load-bearing premise reduces to a self-citation chain. All performance metrics (success rate, energy, completion time) are computed from independent forward simulations of the RL policy and the constant-heading baseline. The mapping to Eulerian topology is descriptive analysis, not a redefinition that forces the claimed navigability.
Axiom & Free-Parameter Ledger
free parameters (1)
- A_max
axioms (2)
- domain assumption Two-dimensional incompressible flow governed by Boussinesq approximation
- domain assumption Reinforcement-learning policy converges to a stable navigation strategy
Reference graph
Works this paper leans on
-
[1]
, " * write output.state after.block = add.period write newline
ENTRY address author booktitle chapter edition editor howpublished institution journal key month note number organization pages publisher school series title type volume year eprint label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block FUNCTION init.state.consts #0 'before.all := #1 'mid.sentence ...
-
[2]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[3]
, Nagy, M
Akos, Z. , Nagy, M. & Vicsek, T. 2008 Comparing bird and human soaring strategies . Proc. Natl Acad. Sci. USA 105 , 4139--4143
2008
-
[4]
, Di Leonardo, R
Bechinger, C. , Di Leonardo, R. , Löwen, H. , Reichhardt, C. , Volpe, G. & Volpe, G. 2016 Active particles in complex and crowded environments . Rev. Mod. Phys. 88 , 045006
2016
-
[5]
Bellemare, M. G. , Candido, S. , Castro, P. S. , Gong, J. , Machado, M. C. , Moitra, S. , Ponda, S. S. & Wang, Z. 2020 Autonomous navigation of stratospheric balloons using reinforcement learning . Nature 588 , 77--82
2020
-
[6]
, Bonaccorso, F
Biferale, L. , Bonaccorso, F. , Buzzicotti, M. , Clark di Leoni, P. & Gustavsson, K. 2019 Zermelo’s problem: Optimal point-to-point navigation in 2D turbulent flows using reinforcement learning . Chaos 29 , 103138
2019
-
[7]
, Biferale, L
Borra, F. , Biferale, L. , Cencini, M. & Celani, A. 2022 Reinforcement learning for pursuit and evasion of microswimmers at low Reynolds number . Phys. Rev. Fluids 7 , 023103
2022
-
[8]
Brunton, S. L. , Noack, B. R. & Koumoutsakos, P. 2020 Machine learning for fluid mechanics . Annu. Rev. Fluid Mech. 52 , 477--508
2020
-
[9]
, Sergent, A
Castillo-Castellanos, A. , Sergent, A. , Podvin, B. & Rossi, M. 2019 Cessation and reversals of large-scale structures in square Rayleigh--Bénard cells . J. Fluid Mech. 877 , 922--954
2019
-
[10]
& Schumacher, J
Chillà, F. & Schumacher, J. 2012 New perspectives in turbulent Rayleigh--Bénard convection . Eur. Phys. J. E 35 , 58
2012
-
[11]
, Gustavsson, K
Cichos, F. , Gustavsson, K. , Mehlig, B. & Volpe, G. 2020 Machine learning for active matter . Nat. Mach. Intell. 2 (2), 94--103
2020
-
[12]
, Mahault, B
Cocconi, L. , Mahault, B. & Piro, L. 2025 Dissipation-accuracy tradeoffs in autonomous control of smart active matter . New J. Phys. 27 (1), 013002
2025
-
[13]
, Gustavsson, K
Colabrese, S. , Gustavsson, K. , Celani, A. & Biferale, L. 2017 Flow navigation by smart microswimmers via reinforcement learning . Phys. Rev. Lett. 118 , 158004
2017
-
[14]
Emran, M. S. & Schumacher, J. 2010 Lagrangian tracer dynamics in a closed cylindrical turbulent convection cell . Phys. Rev. E 82 , 016303
2010
-
[15]
Fischer, P. F. 1997 An overlapping Schwarz method for spectral element solution of the incompressible Navier--Stokes equations . J. Comput. Phys. 133 (1), 84--101
1997
-
[16]
, Tao, X
Gao, Z.-Y. , Tao, X. , Huang, S.-D. , Bao, Y. & Xie, Y.-C. 2024 Flow state transition induced by emergence of orbiting satellite eddies in two-dimensional turbulent Rayleigh--B \'e nard convection . J. Fluid Mech. 997 , A54
2024
-
[17]
, Mandralis, I
Gunnarson, P. , Mandralis, I. , Novati, G. , Koumoutsakos, P. & Dabiri, J. O. 2021 Learning efficient navigation in vortical flow fields . Nat. Commun. 12 , 7143
2021
-
[18]
, Berglund, F
Gustavsson, K. , Berglund, F. , Jonsson, P. R. & Mehlig, B. 2016 Preferential sampling and small-scale clustering of gyrotactic microswimmers in turbulence . Phys. Rev. Lett. 116 , 108104
2016
-
[19]
, Biferale, L
Gustavsson, K. , Biferale, L. , Celani, A. & Colabrese, S. 2017 Finding efficient swimming strategies in a three-dimensional chaotic flow by reinforcement learning . Eur. Phys. J. E 40 , 110
2017
-
[20]
, Zhou, A
Haarnoja, T. , Zhou, A. , Abbeel, P. & Levine, S. 2018 Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor . In Proc. Int. Conf. Mach. Learn. (ICML)\/ , pp. 1861--1870 . PMLR
2018
-
[21]
2015 Lagrangian coherent structures
Haller, G. 2015 Lagrangian coherent structures . Annu. Rev. Fluid Mech. 47 , 137--162
2015
-
[22]
Hang, Haotian , Jiao, Yusheng , Merel, Josh & Kanso, Eva 2026 Flow currents support simple and versatile trail-tracking strategies . Phys. Rev. Res. 8 (1), 013019
2026
-
[23]
, Bao, Y
He, J.-C. , Bao, Y. & Chen, X. 2024 Turbulent boundary layers in thermal convection at moderately high Rayleigh numbers . Phys. Fluids 36 (2), 025140
2024
-
[24]
Heinonen, R. A. , Biferale, L. , Celani, A. & Vergassola, M. 2025 Exploring Bayesian olfactory search in realistic turbulent flows . Phys. Rev. Fluids 10 (6), 064614
2025
-
[25]
2025 Transport phenomena in microswimmer suspensions: migration, collective motion, diffusion and rheology
Ishikawa, T. 2025 Transport phenomena in microswimmer suspensions: migration, collective motion, diffusion and rheology . J. Fluid Mech. 1016 , P1
2025
-
[26]
, Hang, H
Jiao, Y. , Hang, H. , Merel, J. & Kanso, E. 2025 Sensing flow gradients is necessary for learning autonomous underwater navigation . Nat. Commun. 16 (1), 3044
2025
-
[27]
Kooij, G. L. , Botchev, M. A. , Frederix, E. M. , Geurts, B. J. , Horn, S. , Lohse, D. , van der Poel, E. P. , Shishkina, O. , Stevens, R. J. & Verzicco, R. 2018 Comparison of computational codes for direct numerical simulations of turbulent Rayleigh--B \'e nard convection . Comput. Fluids 166 , 1--8
2018
-
[28]
IEEE Access 11 , 118916--118930
Krishna, Kartik , Brunton, Steven L & Song, Zhuoyuan 2023 Finite time lyapunov exponent analysis of model predictive control and reinforcement learning . IEEE Access 11 , 118916--118930
2023
-
[29]
, Song, Z
Krishna, K. , Song, Z. & Brunton, S. L. 2022 Finite-horizon, energy-efficient trajectories in unsteady flows . Proc. R. Soc. A 478 (2258), 20210255
2022
-
[30]
& Powers, T
Lauga, E. & Powers, T. R. 2009 The hydrodynamics of swimming microorganisms . Rep. Prog. Phys. 72 (9), 096601
2009
-
[31]
Laurent, K. M. , Fogg, B. , Ginsburg, T. , Halverson, C. , Lanzone, M. J. , Miller, T. A. , Winkler, D. W. & Bewley, G. P. 2021 Turbulence explains the accelerations of an eagle in natural flight . Proc. Natl Acad. Sci. USA 118 (23), e2102588118
2021
-
[32]
& Shishkina, O
Lohse, D. & Shishkina, O. 2023 Ultimate turbulent thermal convection . Phys. Today 76 (11), 26--32
2023
-
[33]
& Shishkina, O
Lohse, D. & Shishkina, O. 2024 Ultimate Rayleigh--B \'e nard turbulence . Rev. Mod. Phys. 96 (3), 035001
2024
-
[34]
& Xia, K
Lohse, D. & Xia, K. Q. 2010 Small-scale properties of turbulent Rayleigh--B \'e nard convection . Annu. Rev. Fluid Mech. 42 , 335--364
2010
-
[35]
& Eloy, C
Loisy, A. & Eloy, C. 2022 Searching for a source without gradients: how good is infotaxis and how to beat it . Proc. R. Soc. A 478 (2262), 20220118
2022
-
[36]
, Martin, M
Masmitja, I. , Martin, M. , O’Reilly, T. , Kieft, B. , Palomeras, N. , Navarro, J. & Katija, K. 2023 Dynamic robotic tracking of underwater targets using reinforcement learning . Sci. Robot. 8 (80), eade7811
2023
-
[37]
, Bukov, M
Mehta, P. , Bukov, M. , Wang, C. H. , Day, A. G. R. , Richardson, C. , Fisher, C. K. & Schwab, D. J. 2019 A high-bias, low-variance introduction to Machine Learning for physicists . Phys. Rep. 810 , 1--124
2019
-
[38]
, Loisy, A
Monthiller, R. , Loisy, A. , Koehl, M. A. , Favier, B. & Eloy, C. 2022 Surfing on turbulence: a strategy for planktonic navigation . Phys. Rev. Lett. 129 (6), 064502
2022
-
[39]
, Fischer, A
Mui \ n os-Landin, S. , Fischer, A. , Holubec, V. & Cichos, F. 2021 Reinforcement learning with artificial microswimmers . Sci. Robot. 6 (52), eabd9285
2021
-
[40]
& Liebchen, B
Nasiri, M. & Liebchen, B. 2022 Reinforcement learning of optimal active particle navigation . New J. Phys. 24 (7), 073042
2022
-
[41]
, Scheel, J
Pandey, A. , Scheel, J. D. & Schumacher, J. 2018 Turbulent superstructures in Rayleigh--B \'e nard convection . Nat. Commun. 9 , 2118
2018
-
[42]
, Heinonen, R
Piro, L. , Heinonen, R. A. , Cencini, M. & Biferale, L. 2025 Many wrong models approach to localise an odour source in turbulence with static sensors . J. Turbul. 26 (5), 153--173
2025
-
[43]
, Vilfan, A
Piro, L. , Vilfan, A. , Golestanian, R. & Mahault, B. 2024 Energetic cost of microswimmer navigation: The role of body shape . Phys. Rev. Res. 6 (1), 013274
2024
-
[44]
& Sergent, A
Podvin, B. & Sergent, A. 2015 A large-scale investigation of wind reversal in a square Rayleigh--B \'e nard cell . J. Fluid Mech. 766 , 172--201
2015
-
[45]
, Marchioli, C
Qiu, J. , Marchioli, C. & Zhao, L. 2022 a\/ A review on gyrotactic swimmers in turbulent flows . Acta Mech. Sin. 38 (8), 722323
2022
-
[46]
, Mousavi, N
Qiu, J. , Mousavi, N. , Gustavsson, K. , Xu, C. , Mehlig, B. & Zhao, L. 2022 b\/ Navigation of micro-swimmers in steady flow: the importance of symmetries . J. Fluid Mech. 932 , A10
2022
-
[47]
, Mousavi, N
Qiu, J. , Mousavi, N. , Zhao, L. & Gustavsson, K. 2022 c\/ Active gyrotactic stability of microswimmers using hydromechanical signals . Phys. Rev. Fluids 7 (1), 014311
2022
-
[48]
, Celani, A
Reddy, G. , Celani, A. , Sejnowski, T. J. & Vergassola, M. 2016 Learning to soar in turbulent environments . Proc. Natl. Acad. Sci. U.S.A. 113 (33), E4877--E4884
2016
-
[49]
, Wong-Ng, J
Reddy, G. , Wong-Ng, J. , Celani, A. , Sejnowski, T. J. & Vergassola, M. 2018 Glider soaring via reinforcement learning in the field . Nature 562 (7726), 236--239
2018
-
[50]
, Magnoli, N
Rigolli, N. , Magnoli, N. , Rosasco, L. & Seminara, A. 2022 Learning to predict target location with turbulent odor plumes . eLife 11 , e72196
2022
-
[51]
, Samtaney, R
Samuel, R. , Samtaney, R. & Verma, M. K. 2022 Large-eddy simulation of Rayleigh--B \'e nard convection at extreme Rayleigh numbers . Phys. Fluids 34 (7), 075133
2022
-
[52]
, Stahn, M
Schneide, C. , Stahn, M. , Pandey, A. , Junge, O. , Koltai, P. , Padberg-Gehle, K. & Schumacher, J. 2019 Lagrangian coherent sets in turbulent Rayleigh--B \'e nard convection . Phys. Rev. E 100 (5), 053103
2019
-
[53]
& Stark, H
Schneider, E. & Stark, H. 2019 Optimal steering of a smart active particle . EPL 127 (6), 64003
2019
-
[54]
, Carrara, F
Sengupta, A. , Carrara, F. & Stocker, R. 2017 Phytoplankton can actively diversify their migration strategy in response to turbulent cues . Nature 543 (7646), 555--558
2017
-
[55]
& Lohse, D
Shishkina, O. & Lohse, D. 2024 Ultimate Regime of Rayleigh-B \'e nard Turbulence: Subregimes and Their Scaling Relations for the Nusselt vs Rayleigh and Prandtl Numbers . Phys. Rev. Lett. 133 (14), 144001
2024
-
[56]
Simons, A. M. 2004 Many wrongs: the advantage of group navigation . Trends Ecol. Evol. 19 (9), 453--455
2004
-
[57]
, Podvin, B
Soucasse, L. , Podvin, B. , Rivi \`e re, P. & Soufiani, A. 2019 Proper orthogonal decomposition analysis and modelling of large-scale flow reorientations in a cubic Rayleigh--B \'e nard cell . J. Fluid Mech. 881 , 23--50
2019
-
[58]
, Villermaux, E
Vergassola, M. , Villermaux, E. & Shraiman, B. I. 2007 Infotaxis as a strategy for searching without gradients . Nature 445 (7126), 406--409
2007
-
[59]
, Novati, G
Verma, S. , Novati, G. & Koumoutsakos, P. 2018 Efficient collective swimming by harnessing vortices through deep reinforcement learning . Proc. Natl. Acad. Sci. U.S.A. 115 (23), 5849--5854
2018
-
[60]
Wang, B. F. , Zhou, Q. & Sun, C. 2020 a\/ Vibration-induced boundary-layer destabilization achieves massive heat-transport enhancement . Sci. Adv. 6 (21), eaaz8239
2020
-
[61]
, Verzicco, R
Wang, Q. , Verzicco, R. , Lohse, D. & Shishkina, O. 2020 b\/ Multiple states in turbulent large-aspect-ratio thermal convection: what determines the number of convection rolls? Phys. Rev. Lett. 125 (7), 074501
2020
-
[62]
, Bishop, C
Weimerskirch, H. , Bishop, C. , Jeanniard-du Dot, T. , Prudor, A. & Sachs, G. 2016 Frigate birds track atmospheric conditions over months-long transoceanic flights . Science 353 (6294), 74--78
2016
-
[63]
Xia, K. Q. , Chong, K. L. , Ding, G. Y. & Zhang, L. 2025 Some fundamental issues in buoyancy-driven flows with implications for geophysical and astrophysical systems . Acta Mech. Sin. 41 (1), 324287
2025
-
[64]
Xia, K. Q. , Huang, S. D. , Xie, Y. C. & Zhang, L. 2023 Tuning heat transport via coherent structure manipulation: recent advances in thermal turbulence . Natl. Sci. Rev. p. nwad012
2023
-
[65]
, Shi, L
Xu, A. , Shi, L. & Zhao, T. S. 2017 Accelerated lattice Boltzmann simulation using GPU and OpenACC with data management . Int. J. Heat Mass Transf. 109 , 577--588
2017
-
[66]
Xu, A. , Wu, H. L. & Xi, H. D. 2022 Migration of self-propelling agent in a turbulent environment with minimal energy consumption . Phys. Fluids 34 (3), 035117
2022
-
[67]
Xu, A. , Wu, H. L. & Xi, H. D. 2023 Long-distance migration with minimal energy consumption in a thermal turbulent environment . Phys. Rev. Fluids 8 (2), 023502
2023
-
[68]
, Davoodiianidalik, M
Yang, J. , Davoodiianidalik, M. , Xia, H. , Punzmann, H. , Shats, M. & Francois, N. 2019 Passive propulsion in turbulent flows . Phys. Rev. Fluids 4 (10), 104608
2019
-
[69]
, Zhou, Q
Zhang, Y. , Zhou, Q. & Sun, C. 2017 Statistics of kinetic and thermal energy dissipation rates in two-dimensional turbulent Rayleigh--B \'e nard convection . J. Fluid Mech. 814 , 165--184
2017
-
[70]
, Fang, W
Zhu, G. , Fang, W. Z. & Zhu, L. 2022 Optimizing low-Reynolds-number predation via optimal control and reinforcement learning . J. Fluid Mech. 944 , A3
2022
-
[71]
, Mathai, V
Zhu, X. , Mathai, V. , Stevens, R. J. , Verzicco, R. & Lohse, D. 2018 Transition to the ultimate regime in two-dimensional Rayleigh--B \'e nard convection . Phys. Rev. Lett. 120 (14), 144502
2018
-
[72]
, Kang, L
Zhu, Y. , Kang, L. , Tong, X. , Ma, J. , Tian, F. & Fan, D. 2025 Intermittent swimmers optimize energy expenditure with flick-to-flick motor control . J. Fluid Mech. 1006 , A27
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.