Expert-Guided Class-Conditional Goodness-of-Fit Scores for Interpretable Classification with Informative Missingness: An Application to Seismic Monitoring
Pith reviewed 2026-05-10 10:20 UTC · model grok-4.3
The pith
A framework encodes expert knowledge into class-conditional goodness-of-fit features that yield interpretable classifications even with pervasive informative missingness and can outperform standard machine-learning methods when training is
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that prior expert knowledge can be encoded in a class-conditional model whose goodness-of-fit scores, together with transparent auxiliary summaries, produce an accurate yet fully inspectable classifier that handles informative missingness; simulations isolating the framework show this expert-guided method can outperform standard machine-learning classifiers, especially when training samples are small.
What carries the argument
Expert-guided class-conditional goodness-of-fit scores that quantify agreement of both observed and missing data components with the expert model for each class.
If this is right
- Decision rules can be inspected and justified component by component because each feature has a direct interpretation as agreement with an expert model.
- Analyst workload in seismic monitoring is reduced by using the scores as an initial transparent filter before human review.
- Performance holds or improves relative to black-box methods when labeled training data are limited because expert knowledge supplies the missing structure.
- The framework isolates contributions from observed data, missing data patterns, and auxiliary summaries, allowing targeted diagnosis of classification errors.
Where Pith is reading between the lines
- The same feature-construction step could be tested in medical triage tasks where laboratory results are frequently absent and domain models of normal versus diseased states already exist.
- Because the scores remain meaningful even with high missingness, the method may offer a route to more robust classifiers in any domain where missingness itself carries class information.
- Extending the auxiliary summaries to include domain-specific constraints (for example, physical bounds on seismic amplitudes) would be a direct next step that keeps the decision rule transparent.
Load-bearing premise
The expert-specified class-conditional model is accurate and complete enough that its goodness-of-fit scores capture the relevant class differences even when many values are missing.
What would settle it
A direct accuracy comparison between the proposed method and standard classifiers (random forests, neural nets) on a large labeled seismic dataset, repeated across training-set sizes from tens to thousands of examples.
Figures







read the original abstract
We study a classification problem with three key challenges: pervasive informative missingness, the integration of partial prior expert knowledge into the learning process, and the need for interpretable decision rules. We propose a framework that encodes prior knowledge through an expert-guided class-conditional model for one or more classes, and use this model to construct a small set of interpretable goodness-of-fit features. The features quantify how well the observed data agree with the expert model, isolating the contributions of different aspects of the data, including both observed and missing components. These features are combined with a few transparent auxiliary summaries in a simple discriminative classifier, resulting in a decision rule that is easy to inspect and justify. We develop and apply the framework in the context of seismic monitoring used to assess compliance with the Comprehensive Nuclear-Test-Ban Treaty. We show that the method has strong potential as a transparent screening tool, reducing workload for expert analysts. A simulation designed to isolate the contribution of the proposed framework shows that this interpretable expert-guided method can even outperform strong standard machine-learning classifiers, particularly when training samples are small.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a framework for interpretable classification with pervasive informative missingness. Prior expert knowledge is encoded via a class-conditional model for one or more classes; this model is used to construct a small set of goodness-of-fit features that quantify agreement between observed (and missing) data and the expert specification. These features are combined with transparent auxiliary summaries inside a simple discriminative classifier. The approach is developed and applied to seismic monitoring for CTBT compliance verification; a simulation is reported to show that the resulting interpretable method can outperform standard machine-learning classifiers, especially at small training-sample sizes.
Significance. If the simulation result is shown to hold when the expert model is only approximately correct, the framework would supply a practical, inspectable screening tool for domains that combine expert knowledge, missingness, and the need for justifiable decisions. The emphasis on isolating contributions of observed versus missing components and on low-data regimes is a genuine strength.
major comments (2)
- [Simulation section] Simulation section: the description of the data-generating process used to isolate the framework's contribution is insufficient. It is not stated whether the synthetic observations (including the missingness pattern) are drawn exactly from the expert-specified class-conditional densities. If they are, the GOF features are informative by construction while black-box classifiers must discover the same structure from few samples; this setup does not test the misspecification case flagged by the weakest assumption and required for the seismic-monitoring claim.
- [Abstract] Abstract and results presentation: the central performance claim is asserted without any numerical values, confidence intervals, sample sizes, or description of how the expert model was elicited or validated. This leaves the outperformance statement unsupported by visible evidence and prevents assessment of whether the advantage survives realistic departures from the expert model.
minor comments (1)
- [Method section] Notation for the goodness-of-fit features and the auxiliary summaries could be introduced more explicitly with a single table or equation block to improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major comment point by point below, indicating the revisions we will make to improve clarity and evidentiary support.
read point-by-point responses
-
Referee: Simulation section: the description of the data-generating process used to isolate the framework's contribution is insufficient. It is not stated whether the synthetic observations (including the missingness pattern) are drawn exactly from the expert-specified class-conditional densities. If they are, the GOF features are informative by construction while black-box classifiers must discover the same structure from few samples; this setup does not test the misspecification case flagged by the weakest assumption and required for the seismic-monitoring claim.
Authors: We agree that the simulation section requires a more explicit description of the data-generating process. In the revised manuscript, we will state that the synthetic observations and missingness patterns are generated directly from the expert-specified class-conditional densities. This controlled setup isolates the benefit of embedding expert knowledge as goodness-of-fit features, showing their value for interpretable classification when training data are scarce. We acknowledge that the simulation assumes an exactly correct expert model and therefore does not evaluate performance under misspecification. We will add a discussion paragraph addressing the implications of approximate expert models for the seismic application, where the class-conditional specification derives from physical domain knowledge, and will note that sensitivity checks could be explored in future work. revision: partial
-
Referee: Abstract and results presentation: the central performance claim is asserted without any numerical values, confidence intervals, sample sizes, or description of how the expert model was elicited or validated. This leaves the outperformance statement unsupported by visible evidence and prevents assessment of whether the advantage survives realistic departures from the expert model.
Authors: We accept the need for greater specificity. We will revise the abstract to report key quantitative results from the simulation (e.g., classification accuracy or AUC values with confidence intervals at the small sample sizes examined) and will briefly indicate that the expert model was constructed from established seismic monitoring principles. These additions will make the outperformance claim directly verifiable from the abstract. We will also expand the results section to include the requested details on expert-model elicitation and validation, while adding a short note on the dependence of performance on the fidelity of the expert specification. revision: yes
Circularity Check
No significant circularity; framework uses external expert prior and simulation is presented as isolating contribution
full rationale
The paper encodes prior expert knowledge via a class-conditional model to build GOF features that quantify agreement with that model (including missingness), then feeds the features plus auxiliary summaries into a simple classifier. This structure does not reduce the output to the inputs by construction because the expert model is supplied externally rather than fitted to the classification data. The simulation claim is framed as isolating the framework's contribution and demonstrating outperformance (especially at small n), with no quoted equations or self-citation chains showing that the synthetic data generation forces the GOF features to be informative tautologically. The method is therefore self-contained against its stated external benchmark and prior-knowledge assumption.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption An expert can specify a class-conditional model that captures the relevant statistical structure for at least one class
invented entities (1)
-
Expert-guided class-conditional goodness-of-fit features
no independent evidence
Reference graph
Works this paper leans on
-
[1]
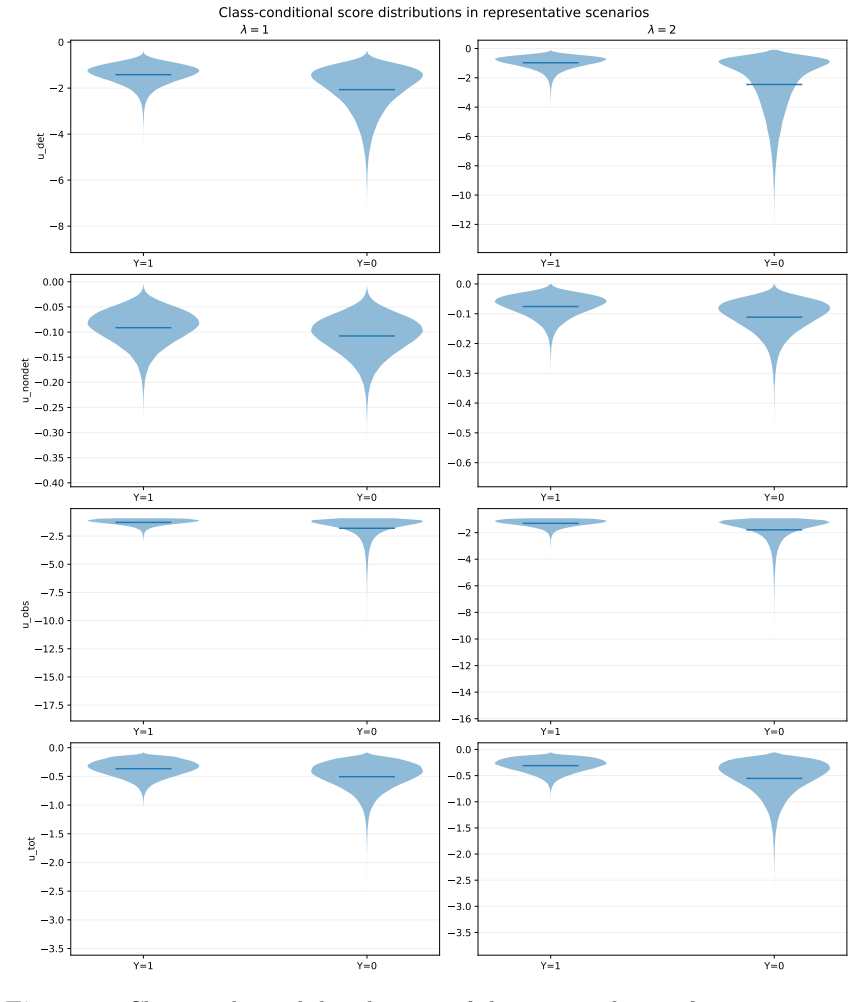
If ¯ℓ(1) i,det≤−1.81, predictY= 0, except in the narrow region Mˆ≤7.674,−2.997< ¯ℓ(1) i,det≤−1.81,¯ℓ(1) i,obs >−1.772, where the tree predictsY= 1
-
[2]
If ¯ℓ(1) i,det >−1.81and¯ℓ(1) i,obs≤−1.871, predictY= 0
-
[3]
If ¯ℓ(1) i,det >−1.81,¯ℓ(1) i,obs >−1.871, and¯Ri≤0.134, predictY= 1
-
[4]
If ¯ℓ(1) i,det >−1.81, ¯ℓ(1) i,obs >−1.871, and ¯Ri > 0.134, then use ¯ℓ(1) i,nondet: predict Y= 0if ¯ℓ(1) i,nondet≤−0.133, andY= 1otherwise. In the representative simulation setting considered here, the learned tree is shallow and its top-level splits are dominated by the detection-fit score¯ℓ(1) i,det and the observed- value fit score¯ℓ(1) i,obs. In par...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.