CIG: Measuring Conversational Information Gain in Deliberative Dialogues with Semantic Memory Dynamics
Pith reviewed 2026-05-10 08:58 UTC · model grok-4.3
The pith
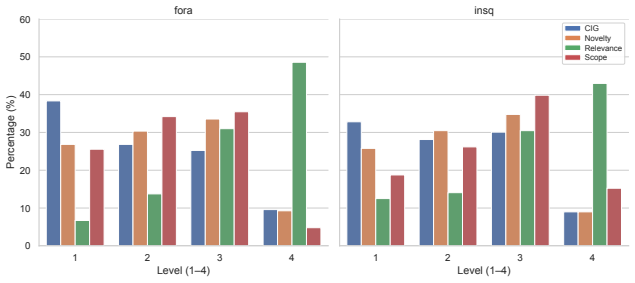
CIG scores utterances using novelty, relevance, and implication scope derived from a dynamic semantic memory model, outperforming traditional heuristics in correlating with human judgments on deliberative segments.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
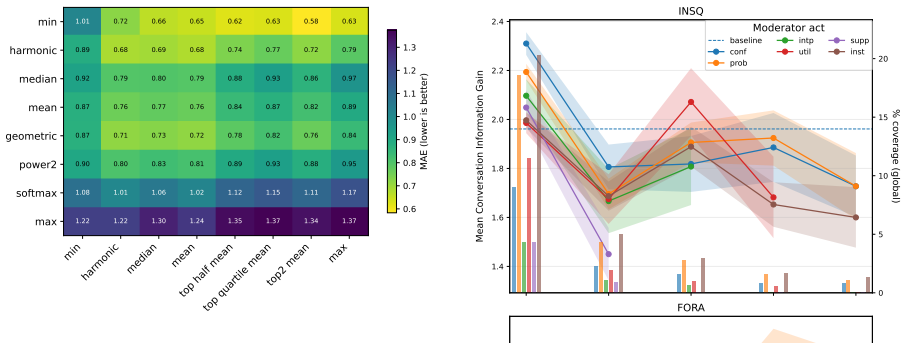
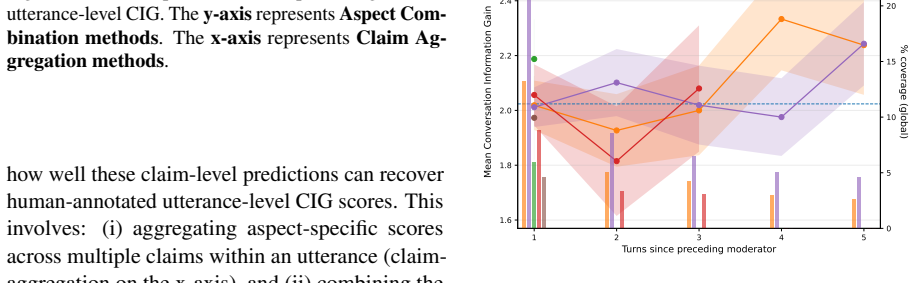
memory-derived dynamics (e.g., the number of claim updates) correlate more strongly with human-perceived CIG than traditional heuristics such as utterance length or TF--IDF.
Load-bearing premise
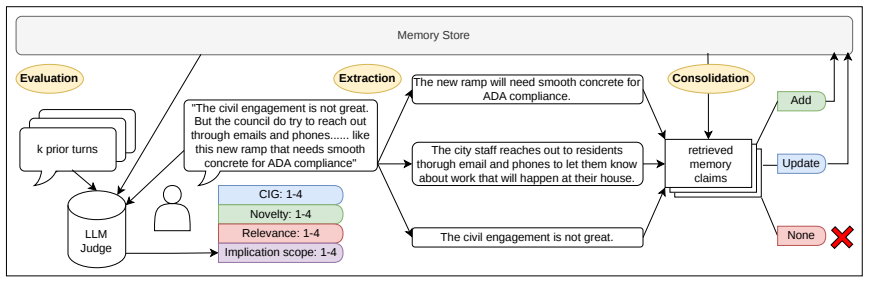
The assumption that extracting atomic claims and consolidating them into a structured memory accurately reflects the advancement of collective understanding in the conversation.
Figures

read the original abstract
Measuring the quality of public deliberation requires evaluating not only civility or argument structure, but also the informational progress of a conversation. We introduce a framework for Conversational Information Gain (CIG) that evaluates each utterance in terms of how it advances collective understanding of the target topic. To operationalize CIG, we model an evolving semantic memory of the discussion: the system extracts atomic claims from utterances and incrementally consolidates them into a structured memory state. Using this memory, we score each utterance along three interpretable dimensions: Novelty, Relevance, and Implication Scope. We annotate 80 segments from two moderated deliberative settings (TV debates and community discussions) with these dimensions and show that memory-derived dynamics (e.g., the number of claim updates) correlate more strongly with human-perceived CIG than traditional heuristics such as utterance length or TF--IDF. We develop effective LLM-based CIG predictors paving the way for information-focused conversation quality analysis in dialogues and deliberative success.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a framework for Conversational Information Gain (CIG) that models the informational progress of deliberative dialogues via an evolving semantic memory: atomic claims are extracted from utterances and incrementally consolidated into a structured state. Utterances are then scored along three dimensions (Novelty, Relevance, Implication Scope) derived from memory dynamics such as claim-update counts. The authors annotate 80 segments from TV debates and community discussions, report that these memory-derived metrics correlate more strongly with human-perceived CIG than baselines like utterance length or TF-IDF, and present LLM-based predictors for automated CIG assessment.
Significance. If the semantic memory faithfully captures collective understanding without distortion from claim extraction or consolidation, the work provides a novel, interpretable approach to quantifying informational advancement in public deliberation, extending beyond civility or argument-structure metrics. The reported correlations and LLM predictors could enable scalable, information-focused evaluation in dialogue systems and deliberative analysis.
major comments (2)
- [Abstract and Evaluation] Abstract and Evaluation section: The 80-segment annotation study is presented without details on segment selection, annotation guidelines, inter-annotator agreement, or statistical significance of the correlations. This is load-bearing because human CIG judgments serve as the external benchmark for validating that memory dynamics outperform length/TF-IDF; without these, the strength of the headline result cannot be assessed.
- [Framework] Framework section on semantic memory construction: The premise that atomic claim extraction plus consolidation produces a lossless representation of collective understanding advancement is untested. If segmentation splits propositions inconsistently or consolidation drops implications, then metrics like claim-update counts become parser artifacts rather than genuine CIG measures; the 80-segment study cannot distinguish these cases from true informational progress.
minor comments (2)
- [Framework] Provide explicit formulas or pseudocode for computing the three scoring dimensions (Novelty, Relevance, Implication Scope) from the memory state to improve reproducibility.
- [Implementation] Clarify how the LLM pipeline for claim extraction and consolidation is prompted and whether any post-processing rules are applied, as these choices directly affect the derived dynamics.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment below and specify the revisions we will incorporate.
read point-by-point responses
-
Referee: [Abstract and Evaluation] Abstract and Evaluation section: The 80-segment annotation study is presented without details on segment selection, annotation guidelines, inter-annotator agreement, or statistical significance of the correlations. This is load-bearing because human CIG judgments serve as the external benchmark for validating that memory dynamics outperform length/TF-IDF; without these, the strength of the headline result cannot be assessed.
Authors: We agree that these details are necessary to properly evaluate the annotation study and the strength of our correlations. In the revised manuscript we will expand the Evaluation section with: (i) explicit criteria and sources used to select the 80 segments from the TV debates and community discussions, (ii) the complete annotation guidelines and rating scales provided to annotators, (iii) inter-annotator agreement statistics (e.g., Fleiss’ kappa), and (iv) statistical significance tests (p-values and confidence intervals) for all reported correlations against the baselines. These elements were collected during the study but omitted for space; they will now be reported transparently. revision: yes
-
Referee: [Framework] Framework section on semantic memory construction: The premise that atomic claim extraction plus consolidation produces a lossless representation of collective understanding advancement is untested. If segmentation splits propositions inconsistently or consolidation drops implications, then metrics like claim-update counts become parser artifacts rather than genuine CIG measures; the 80-segment study cannot distinguish these cases from true informational progress.
Authors: We acknowledge that claim extraction and consolidation are imperfect approximations and that the current study does not directly test their fidelity against a gold-standard memory state. The stronger human correlations relative to length and TF-IDF baselines provide supporting evidence that the derived metrics track perceived informational gain, yet this does not rule out parser artifacts. In the revision we will add a dedicated limitations paragraph in the Framework section that (a) discusses known failure modes of the extraction and consolidation steps with illustrative examples, (b) reports any available extraction-error statistics from our pipeline, and (c) outlines future work on human validation of memory states. This will not change the reported results but will present the modeling assumptions more cautiously. revision: partial
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Atomic claims can be reliably extracted from utterances and consolidated into a structured memory state.
invented entities (1)
-
Semantic memory state
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav
Whow: A cross-domain approach for analysing conversation moderation.arXiv preprint arXiv:2410.15551. Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav. 2025. Mem0: Building production-ready ai agents with scalable long-term memory.arXiv preprint arXiv:2504.19413. Michelene TH Chi. 2009. Three types of conceptual change: Belief r...
-
[2]
Tirthankar Ghosal, Tanik Saikh, Tameesh Biswas, Asif Ekbal, and Pushpak Bhattacharyya
Topic-conversation relevance (tcr) dataset and benchmarks.Advances in Neural Information Pro- cessing Systems, 37:140159–140174. Tirthankar Ghosal, Tanik Saikh, Tameesh Biswas, Asif Ekbal, and Pushpak Bhattacharyya. 2022. Novelty detection: A perspective from natural language pro- cessing.Computational Linguistics, 48(1):77–117. Mario Giulianelli, Arabell...
work page 2022
-
[3]
Evaluating human-language model interaction.arXiv preprint arXiv:2212.09746,
Hearing personal experiences improves so- cial evaluations compared to personal opinions, espe- cially for polarized parties.Especially for Polarized Parties (December 05, 2023). Julia Kruk, Michela Marchini, Rijul Magu, Caleb Ziems, David Muchlinski, and Diyi Yang. 2024. Silent sig- nals, loud impact: Llms for word-sense disambigua- tion of coded dog whi...
-
[4]
Six attributes of unhealthy conversations. In Proceedings of the Fourth Workshop on Online Abuse and Harms, pages 114–124. Kun Qian, Maximillian Chen, Siyan Li, Arpit Sharma, and Zhou Yu. 2025. Bottom-up synthesis of knowledge-grounded task-oriented dialogues with iteratively self-refined prompts. InProceedings of the 2025 Conference of the Nations of the...
-
[5]
Speaker 1: I hope my kids own guns
- [6]
-
[7]
Speaker 3: When I look at the statistics about how that adds to the risk of suicide, the risk of being misused, the risk of it being stolen, used in a domestic quarrel, I think it’s just too much of a risk. Output: {"memories":[ {"speaker":"Speaker 3","target_speaker":"Everyone","claim":"Having a gun increases the risk of suicide.","turn_id":"3"}, {"speak...
-
[8]
same speaker &equivalent
-
[9]
same speaker &backward_entail
-
[10]
same speaker & (contradictionorforward_entail)
-
[11]
different speaker & any non-neutral relation Else: no eligibleB→treat as neutral (ADD, target=null). Ties within a rung: pick the highest confidence (or highest similarity). Action mapping Same speaker: equivalent,backward_entail → NONE;forward_entail,contradiction → UPDATE;neu- tral→ADD. Different speaker: always ADD. UPDATE semantics Ifcontradiction: re...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.