Multi-objective Reinforcement Learning With Augmented States Requires Rewards After Deployment
Pith reviewed 2026-05-10 09:34 UTC · model grok-4.3
The pith
Multi-objective RL agents using augmented states for non-linear utilities must retain access to reward signals after deployment.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
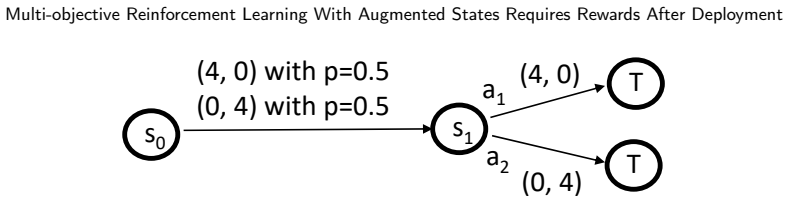
The optimal policy for an MORL agent with a non-linear utility function must be conditioned on both the current environmental state and some measure of the previously accrued reward. When this conditioning is implemented via state augmentation with the discounted sum of rewards, the agent requires continued access to the reward signal after deployment, even if no further learning occurs.
What carries the argument
Augmented state created by concatenating the observed environmental state with the discounted sum of previous rewards, enabling the policy to condition on accrued rewards for non-linear utilities.
If this is right
- Agents cannot be deployed in settings that provide no reward information after training without losing optimality.
- Fixed policies still require reward access at every time step to compute the correct augmented state.
- Real-world applications must either supply ongoing rewards or use alternative conditioning mechanisms.
- Deployment costs increase when rewards are expensive or unavailable post-training.
Where Pith is reading between the lines
- Alternative conditioning approaches that do not embed rewards directly in the state could remove the post-deployment requirement.
- The same issue would arise in any RL setting that augments states with internal signals the agent cannot observe at test time.
- This constraint may favor linear scalarization methods in domains where reward access cannot be guaranteed after deployment.
Load-bearing premise
The standard implementation of conditioning on accrued reward uses state augmentation with the discounted sum, and this augmentation is required to achieve optimality under non-linear utilities.
What would settle it
An explicit optimal policy for a non-linear-utility MORL task that matches the performance of the augmented-state policy while making decisions without any reward signal after deployment.
Figures

read the original abstract
This research note identifies a previously overlooked distinction between multi-objective reinforcement learning (MORL), and more conventional single-objective reinforcement learning (RL). It has previously been noted that the optimal policy for an MORL agent with a non-linear utility function is required to be conditioned on both the current environmental state and on some measure of the previously accrued reward. This is generally implemented by concatenating the observed state of the environment with the discounted sum of previous rewards to create an augmented state. While augmented states have been widely-used in the MORL literature, one implication of their use has not previously been reported -- namely that they require the agent to have continued access to the reward signal (or a proxy thereof) after deployment, even if no further learning is required. This note explains why this is the case, and considers the practical repercussions of this requirement.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that in multi-objective reinforcement learning (MORL) with non-linear utility functions, the standard practice of augmenting the state with the discounted sum of accrued rewards (to condition the policy on past returns) implies that the deployed agent must retain access to the reward signal or a proxy, even without further learning; this is presented as an overlooked distinction from single-objective RL, with discussion of practical deployment repercussions.
Significance. If the implication holds, the note usefully flags a deployment constraint for the widely adopted state-augmentation approach in MORL, which could affect real-world applications where post-deployment reward access is unavailable or costly. The observation is a direct logical consequence of existing MORL constructions rather than a new empirical result, so its value lies in surfacing an unremarked practical consequence.
minor comments (2)
- The abstract states that augmented states 'have been widely-used in the MORL literature' but does not cite specific representative papers or implementations; adding 1-2 canonical references would strengthen the grounding of the 'generally implemented' claim.
- The note would benefit from a brief concrete example (e.g., a simple two-objective environment) illustrating why the augmented state must be updated from observed rewards at test time, to make the requirement more tangible for readers unfamiliar with MORL.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of the manuscript and for recommending acceptance. The note's core observation—that state augmentation in MORL with non-linear utilities requires post-deployment reward access—is indeed a direct logical consequence of standard constructions, and we appreciate the referee's recognition of its practical relevance for deployment scenarios.
Circularity Check
No significant circularity
full rationale
The paper is a short research note that identifies an unreported deployment consequence of the standard state-augmentation technique already used throughout the MORL literature for conditioning policies on accrued vector returns under non-linear scalarization. The argument proceeds by direct implication from the definition of augmented states (concatenating the environmental state with the discounted sum of observed rewards) and does not introduce any new equations, fitted parameters, predictions, or uniqueness theorems. No self-citations appear as load-bearing premises, no ansatz is smuggled, and no known result is merely renamed. The central claim is therefore an observation about existing practice rather than a derivation that reduces to its own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
D.M.Roijers,P.Vamplew,S.Whiteson,R.Dazeley, Asurveyofmulti-objectivesequentialdecision-making, JournalofArtificialIntelligence Research 48 (2013) 67–113
work page 2013
-
[2]
C. F. Hayes, R. Rădulescu, E. Bargiacchi, J. Källström, M. Macfarlane, M. Reymond, T. Verstraeten, L. M. Zintgraf, R. Dazeley, F. Heintz, et al., A practical guide to multi-objective reinforcement learning and planning, Autonomous Agents and Multi-Agent Systems 36 (2022)
work page 2022
-
[3]
F. Felten, E.-G. Talbi, G. Danoy, Multi-objective reinforcement learning based on decomposition: A taxonomy and framework, Journal of Artificial Intelligence Research 79 (2024) 679–723
work page 2024
-
[4]
Y.Cao,H.Zhan, Efficientmulti-objectivereinforcementlearningviamultiple-gradientdescentwithiterativelydiscoveredweight-vectorsets, Journal of Artificial Intelligence Research 70 (2021) 319–349
work page 2021
- [5]
-
[6]
Q.Bai,M.Agarwal,V.Aggarwal, Jointoptimizationofconcavescalarizedmulti-objectivereinforcementlearningwithpolicygradientbased algorithm, Journal of Artificial Intelligence Research 74 (2022) 1565–1597. P. Vamplew and C. Foale:Preprint submitted to ElsevierPage 5 of 6 Multi-objective Reinforcement Learning With Augmented States Requires Rewards After Deployment
work page 2022
-
[7]
P. Vamplew, C. Foale, R. Dazeley, The impact of environmental stochasticity on value-based multiobjective reinforcement learning, Neural Computing and Applications 34 (2022) 1783–1799
work page 2022
-
[8]
P. Geibel, Reinforcement learning for mdps with constraints, in: European conference on machine learning, Springer, 2006, pp. 646–653
work page 2006
-
[9]
R.Issabekov,P.Vamplew, Anempiricalcomparisonoftwocommonmultiobjectivereinforcementlearningalgorithms, in:AustralasianJoint Conference on Artificial Intelligence (AJCAI), Springer, 2012, pp. 626–636
work page 2012
-
[10]
M.Reymond,C.F.Hayes,D.Steckelmacher,D.M.Roijers,A.Nowé, Actor-criticmulti-objectivereinforcementlearningfornon-linearutility functions, Autonomous Agents and Multi-Agent Systems 37 (2023) 23
work page 2023
-
[11]
G. Yu, U. Siddique, P. Weng, Fair deep reinforcement learning with generalized gini welfare functions, in: International Conference on Autonomous Agents and Multiagent Systems, Springer, 2023, pp. 3–29
work page 2023
-
[12]
F.Chouaki,A.Beynier,N.Maudet,P.Viappiani,Fairnessincooperativemulti-agentmulti-objectivereinforcementlearningusingtheexpected scalarizedreturn, in:Proceedingsofthe24thInternationalConferenceonAutonomousAgentsandMultiagentSystems,2025,pp.2469–2471
work page 2025
-
[13]
K. Ding, P. Vamplew, C. Foale, R. Dazeley, An empirical investigation of value-based multi-objective reinforcement learning for stochastic environments, The Knowledge Engineering Review 40 (2025)
work page 2025
-
[14]
G. Peng, E. Pauwels, H. Baier, Multi-objective utility actor critic with utility critic for nonlinear utility function, in: Eighteenth European Workshop on Reinforcement Learning, 2025
work page 2025
-
[15]
N. Peng, M. Tian, B. Fain, Multi-objective reinforcement learning with nonlinear preferences: Provable approximation for maximizing expected scalarized return, in: Proceedings of the 24th International Conference on Autonomous Agents and Multiagent Systems, 2025, pp. 1632–1640
work page 2025
-
[16]
S.Zhao,S.Fu,L.Bai,H.Liang,Q.Zhao,T.Li, Adaptivemulti-objectivereinforcementlearningfornon-linearandimplicitutilityfunctions, IEICE Transactions on Information and Systems (2025)
work page 2025
-
[17]
P. R. Wurman, S. Barrett, K. Kawamoto, J. MacGlashan, K. Subramanian, T. J. Walsh, R. Capobianco, A. Devlic, F. Eckert, F. Fuchs, et al., Outracing champion gran turismo drivers with deep reinforcement learning, Nature 602 (2022) 223–228
work page 2022
-
[18]
Z. Li, Q. Ji, X. Ling, Q. Liu, A comprehensive review of multi-agent reinforcement learning in video games, IEEE Transactions on Games (2025)
work page 2025
-
[19]
L. Avramelou, P. Nousi, N. Passalis, A. Tefas, Deep reinforcement learning for financial trading using multi-modal features, Expert Systems with Applications 238 (2024) 121849
work page 2024
-
[20]
A. Singh, L. Yang, C. Finn, S. Levine, End-to-end robotic reinforcement learning without reward engineering, in: Proceedings of Robotics: Science and Systems, FreiburgimBreisgau, Germany, 2019. doi:10.15607/RSS.2019.XV.073
- [21]
- [22]
-
[23]
W. Luo, P. Sun, F. Zhong, W. Liu, T. Zhang, Y. Wang, End-to-end active object tracking and its real-world deployment via reinforcement learning, IEEE transactions on pattern analysis and machine intelligence 42 (2019) 1317–1332
work page 2019
- [24]
-
[25]
T. Kaufmann, P. Weng, V. Bengs, E. Hüllermeier, A survey of reinforcement learning from human feedback, CoRR (2023)
work page 2023
-
[26]
A. Baisero, B. Daley, C. Amato, Asymmetric dqn for partially observable reinforcement learning, in: Uncertainty in Artificial Intelligence, PMLR, 2022, pp. 107–117
work page 2022
-
[27]
A. Eberhard, H. Metni, G. Fahland, A. Stroh, P. Friederich, Actively learning costly reward functions for reinforcement learning, Machine Learning: Science and Technology 5 (2024) 015055
work page 2024
-
[28]
A.Wang,A.C.Li,T.Q.Klassen,R.T.Icarte,S.A.McIlraith, Learningbeliefrepresentationsforpartiallyobservabledeeprl, in:International Conference on Machine Learning, PMLR, 2023, pp. 35970–35988
work page 2023
-
[29]
Y. Cai, X. Liu, A. Oikonomou, K. Zhang, Provable partially observable reinforcement learning with privileged information, Advances in Neural Information Processing Systems 37 (2024) 63790–63857
work page 2024
-
[30]
J.Li,E.Zhao,T.Wei,J.Xing,S.Xiang, Leveragingprivilegedinformationforpartiallyobservablereinforcementlearning, IEEETransactions on Games (2025). P. Vamplew and C. Foale:Preprint submitted to ElsevierPage 6 of 6
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.