PolicyGapper: Automated Detection of Inconsistencies Between Google Play Data Safety Sections and Privacy Policies Using LLMs
Pith reviewed 2026-05-10 08:06 UTC · model grok-4.3
The pith
PolicyGapper uses LLMs to detect 2,689 inconsistencies between Google Play Data Safety Sections and privacy policies.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
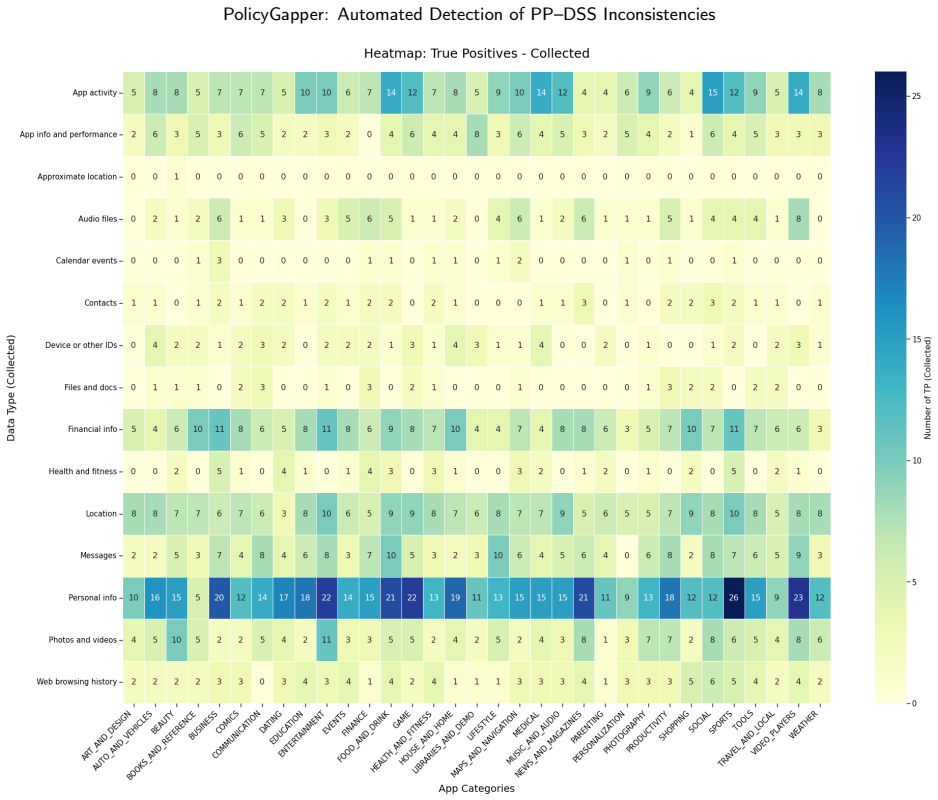
PolicyGapper is an LLM-based methodology with four stages of scraping, pre-processing, analysis, and post-processing that automatically detects discrepancies between Data Safety Sections and privacy policies, identifying 2,689 omitted disclosures including 2,040 related to data collection and 649 to data sharing in 330 apps, with manual validation yielding average Precision of 0.75, Recall of 0.77, Accuracy of 0.69, and F1-score of 0.76.
What carries the argument
PolicyGapper's four-stage pipeline that scrapes DSS and PP text, preprocesses it, applies LLMs to identify inconsistencies in data practices, and post-processes results to count collection and sharing omissions.
If this is right
- The approach scales to large app sets because it uses only public text and requires no binaries.
- Developers could run similar checks to align their own Data Safety Sections with privacy policies before release.
- Marketplaces might incorporate automated flagging to reduce incomplete disclosures.
- Releasing the dataset, prompts, and code allows direct reproduction and extension of the evaluation.
Where Pith is reading between the lines
- High omission counts suggest developers face practical difficulty translating detailed legal policies into concise summaries.
- The method could extend to other app stores that require standardized data disclosures.
- LLM accuracy might increase with prompts tuned specifically for privacy-law ambiguities.
- Repeated validation runs indicate the results are stable enough for preliminary compliance screening.
Load-bearing premise
That LLM comparison of scraped policy text can reliably identify true omissions despite ambiguous legal phrasing that might require domain expertise.
What would settle it
A full manual expert review of the Data Safety Sections and privacy policies for all 330 apps to confirm whether the reported omissions match actual inconsistencies.
Figures



read the original abstract
Mobile application developers are required to disclose how they collect, use, and share user data in compliance with privacy regulations. To support transparency, major app marketplaces have introduced standardized disclosure mechanisms. In 2022, Google mandated the Data Safety Section (DSS) on Google Play, requiring developers to summarize their data practices. However, compiling accurate DSS disclosures is challenging, as they must remain consistent with the corresponding privacy policy (PP), and no automated tool currently verifies this alignment. Prior studies indicate that nearly 80% of popular apps contain incomplete or misleading DSS declarations. We present PolicyGapper, an LLM-based methodology for automatically detecting discrepancies between DSS disclosures and privacy policies. PolicyGapper operates in four stages: scraping, pre-processing, analysis, and post-processing, without requiring access to application binaries. We evaluate PolicyGapper on a dataset of 330 top-ranked apps spanning all 33 Google Play categories, collected in Q3 2025. The approach identifies 2,689 omitted disclosures, including 2,040 related to data collection and 649 to data sharing. Manual validation on a stratified 10% subset, repeated across three independent runs, yields an average Precision of 0.75, Recall of 0.77, Accuracy of 0.69, and F1-score of 0.76. To support reproducibility, we release a complete replication package, including the dataset, prompts, source code, and results available at https://github.com/Mobile-IoT-Security-Lab/PolicyGapper and https://doi.org/10.5281/zenodo.19628493.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces PolicyGapper, an LLM-based four-stage pipeline (scraping, pre-processing, analysis, post-processing) to detect inconsistencies between Google Play Data Safety Sections (DSS) and privacy policies (PP) without requiring app binaries. Evaluated on 330 top-ranked apps across all 33 categories collected in Q3 2025, the system identifies 2,689 omitted disclosures (2,040 data collection, 649 data sharing). Manual validation on a stratified 10% subset, repeated over three runs, reports average precision 0.75, recall 0.77, accuracy 0.69, and F1 0.76. The replication package (dataset, prompts, code, results) is released publicly.
Significance. If the detection reliability holds, the work provides a practical, scalable automated method to audit privacy disclosure compliance at marketplace scale, directly addressing documented gaps where most apps have incomplete DSS. The no-binary-access design and full public release of artifacts (including prompts and results) are clear strengths that enable independent verification and extension.
major comments (2)
- Evaluation section (manual validation paragraph): The headline count of 2,689 omitted disclosures rests on LLM interpretation of privacy-policy text, yet the paper provides no information on annotator expertise, inter-annotator agreement (e.g., Cohen’s kappa), or explicit resolution rules for ambiguous legal phrasing such as conditional clauses (“may share with partners”) or broad terms. The reported average F1 of 0.76 on the 10% stratified sample therefore supplies only moderate reassurance; without these details the precision/recall figures and the overall omission tally cannot be fully trusted.
- Dataset and collection description: The 330-app corpus is described as “top-ranked apps spanning all 33 categories,” but the exact ranking metric, selection window within Q3 2025, and handling of policy updates during scraping are not specified. This information is load-bearing for assessing whether the 2,689 omissions generalize beyond the sampled set.
minor comments (2)
- Abstract: The collection period “Q3 2025” appears forward-dated; please confirm the actual calendar window or correct the typo.
- Reproducibility: While the GitHub/Zenodo links are welcome, the main text should include at least one representative prompt template so readers can assess how the LLM is instructed to map policy statements to DSS categories without consulting the external package.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, indicating where revisions will be made to the manuscript.
read point-by-point responses
-
Referee: Evaluation section (manual validation paragraph): The headline count of 2,689 omitted disclosures rests on LLM interpretation of privacy-policy text, yet the paper provides no information on annotator expertise, inter-annotator agreement (e.g., Cohen’s kappa), or explicit resolution rules for ambiguous legal phrasing such as conditional clauses (“may share with partners”) or broad terms. The reported average F1 of 0.76 on the 10% stratified sample therefore supplies only moderate reassurance; without these details the precision/recall figures and the overall omission tally cannot be fully trusted.
Authors: We agree that the current description of the manual validation is insufficiently detailed. The three independent runs were performed by the authors, who have domain expertise in privacy and security research. Ambiguous phrasing was handled by applying a conservative rule: any conditional or broad language suggesting possible data practices was treated as requiring explicit DSS disclosure. However, no formal inter-annotator agreement metric was computed. In the revised manuscript we will add a dedicated paragraph (or subsection) describing the annotators’ backgrounds, the exact resolution guidelines for legal ambiguities, and the observed consistency across the three runs. This will allow readers to better assess the reliability of the 0.76 F1 score and the 2,689 omission count. revision: yes
-
Referee: Dataset and collection description: The 330-app corpus is described as “top-ranked apps spanning all 33 categories,” but the exact ranking metric, selection window within Q3 2025, and handling of policy updates during scraping are not specified. This information is load-bearing for assessing whether the 2,689 omissions generalize beyond the sampled set.
Authors: We concur that greater precision on corpus construction is required. The 330 apps were the top-ranked free applications in each of the 33 Google Play categories according to the store’s official popularity rankings at the start of Q3 2025. Scraping took place over a three-week window in July–August 2025; any privacy-policy change detected during this period triggered an immediate re-scrape of the affected app. We will expand the dataset section with an explicit description of the ranking source, the precise collection dates, and the update-handling protocol to support reproducibility and external assessment of generalizability. revision: yes
Circularity Check
No significant circularity in empirical pipeline
full rationale
The paper's core output consists of counts of omitted disclosures produced by applying an LLM-based comparison pipeline (scraping, preprocessing, analysis, post-processing) directly to a fresh dataset of 330 apps. These counts are not derived from any fitted parameters, self-referential definitions, or equations that reduce outputs to inputs by construction. The reported precision/recall figures rest on independent manual labeling of a stratified 10% subset across three runs, which constitutes external validation rather than a self-citation chain or renamed prior result. No load-bearing step invokes a uniqueness theorem, ansatz smuggled via citation, or self-definitional mapping. The methodology is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs can accurately detect omissions between short-form disclosures and full privacy policies when given appropriate prompts
Reference graph
Works this paper leans on
-
[1]
Akinotcho,F.,Wei,L.,Rubin,J.,2025. Mobileapplicationcoverage:The30%curseandwaysforward,in:2025IEEE/ACM47thInternational Conference on Software Engineering (ICSE), IEEE Computer Society. pp. 679–679
work page 2025
-
[2]
Alecci, M., Sannier, N., Ceci, M., Abualhaija, S., Samhi, J., Bianculli, D., BISSYANDE, T.F.d.A., Klein, J., 2025. Toward llm-driven gdpr compliance checking for android apps, in: 33rd ACM International Conference on the Foundations of Software Engineering (FSE Companion’25)
work page 2025
-
[3]
Altpeter, B., 2022-09-18. Worrying confessions: A look at data safety labels on Android.https://www.datarequests.org/blog/ android-data-safety-labels-analysis/
work page 2022
-
[4]
Andow, B., Mahmud, S.Y., Wang, W., Whitaker, J., Enck, W., Reaves, B., Singh, K., Xie, T., 2019. PolicyLint: Investigating internal privacy policycontradictionsongoogleplay,in:28thUSENIXSecuritySymposium(USENIXSecurity19),USENIXAssociation,SantaClara,CA. pp. 585–602. URL:https://www.usenix.org/conference/usenixsecurity19/presentation/andow
work page 2019
-
[5]
Arkalakis, I., Diamantaris, M., Moustakas, S., Ioannidis, S., Polakis, J., Ilia, P., 2024. Abandon all hope ye who enter here: A dynamic, longitudinal investigation of android’s data safety section, in: 33rd USENIX Security Symposium (USENIX Security 24), pp. 5645–5662
work page 2024
-
[6]
Baalous,R.,Althobaiti,A.,Alyoubi,D.,Alzahrani,R.,Aljohani,M.,2025. Detectingtheinconsistencybetweenandroidapps’datacollection and google play’s data safety using static analysis. Cybernetics and Information Technologies 25
work page 2025
-
[7]
The Limits of Notice and Choice
Cate, F.H., 2010. The Limits of Notice and Choice . IEEE Security & Privacy 8, 59–62. URL:https://doi.ieeecomputersociety. org/10.1109/MSP.2010.84, doi:10.1109/MSP.2010.84
-
[8]
Checks.https://checks.google.com/
Developers, A., 2026a. Checks.https://checks.google.com/
-
[9]
Policy status.https://play.google.com/console/about/policystatus/
Developers, A., 2026b. Policy status.https://play.google.com/console/about/policystatus/
-
[10]
Fan, M., Shi, J., Wang, Y., Yu, L., Zhang, X., Wang, H., Jin, W., Liu, T., 2024. Giving without notifying: Assessing compliance of data transmission in android apps, in: Proceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering, pp. 1595–1606
work page 2024
-
[11]
Detecting hallucinations in large language models using semantic entropy
Farquhar, S., Kossen, J., Kuhn, L., Gal, Y., 2024. Detecting hallucinations in large language models using semantic entropy. Nature 630, 625–630
work page 2024
-
[12]
Gluck,J.,Schaub,F.,Friedman,A.,Habib,H.,Sadeh,N.,Cranor,L.F.,Agarwal,Y.,2016. Howshortistooshort?implicationsoflengthand framingontheeffectivenessofprivacynotices,in:ProceedingsoftheTwelfthUSENIXConferenceonUsablePrivacyandSecurity,USENIX Association, USA. p. 321–340. Ferrari et al.:Preprint submitted to ElsevierPage 18 of 22 PolicyGapper: Automated Detec...
work page 2016
-
[13]
Google, 2026a. Gemini API Document Understanding.http://docs.cloud.google.com/vertex-ai/generative-ai/docs/ multimodal/document-understanding
-
[14]
Long context.https://ai.google.dev/gemini-api/docs/long-context
Google, 2026b. Long context.https://ai.google.dev/gemini-api/docs/long-context
-
[15]
Google, 2026c. My app has been removed from Google Play.https://support.google.com/googleplay/android-developer/ answer/2477981?hl=en#zippy=%2Cremovals%2Csuspensions
-
[16]
Google, 2026d. Provide information for Google Play’s Data safety section .https://support.google.com/googleplay/ android-developer/answer/10787469?hl=en
-
[17]
Google,2026e.Userdata–playconsolehelp.https://support.google.com/googleplay/android-developer/answer/10144311. Accessed: 2026-02-03
-
[18]
Harkous,H.,Fawaz,K.,Lebret,R.,Schaub,F.,Shin,K.G.,Aberer,K.,2018. Polisis:Automatedanalysisandpresentationofprivacypolicies using deep learning, in: 27th USENIX Security Symposium (USENIX Security 18), USENIX Association, Baltimore, MD. pp. 531–548. URL:https://www.usenix.org/conference/usenixsecurity18/presentation/harkous
work page 2018
-
[19]
Huang, L., Yu, W., Ma, W., Zhong, W., Feng, Z., Wang, H., Chen, Q., Peng, W., Feng, X., Qin, B., et al., 2025. A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions. ACM Transactions on Information Systems 43, 1–55
work page 2025
-
[20]
iubenda, 2026. The Biggest GDPR Fines to Date [2024].https://www.iubenda.com/en/blog/ the-biggest-gdpr-fines-to-date/
work page 2026
-
[21]
Kelley, P.G., Bresee, J., Cranor, L.F., Reeder, R.W., 2009. A "nutrition label" for privacy, in: Proceedings of the 5th Symposium on Usable PrivacyandSecurity,AssociationforComputingMachinery,NewYork,NY,USA.URL:https://doi.org/10.1145/1572532.1572538, doi:10.1145/1572532.1572538
-
[22]
Khandelwal, R., Nayak, A., Chung, P., Fawaz, K., 2023a. Comparing privacy labels of applications in android and ios, in: Proceedings of the 22nd Workshop on Privacy in the Electronic Society, Association for Computing Machinery, New York, NY, USA. p. 61–73. URL: https://doi.org/10.1145/3603216.3624967, doi:10.1145/3603216.3624967
-
[23]
Theoverviewofprivacylabelsandtheircompatibilitywithprivacypolicies
Khandelwal,R.,Nayak,A.,Chung,P.,Fawaz,K.,2023b. Theoverviewofprivacylabelsandtheircompatibilitywithprivacypolicies. URL: https://arxiv.org/abs/2303.08213,arXiv:2303.08213
-
[24]
Khandelwal, R., Nayak, A., Chung, P., Fawaz, K., 2024. Unpacking privacy labels: A measurement and developer perspective on google’s data safety section, in: 33rd USENIX Security Symposium (USENIX Security 24), pp. 2831–2848
work page 2024
-
[25]
Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang
Liu, N.F., Lin, K., Hewitt, J., Paranjape, A., Bevilacqua, M., Petroni, F., Liang, P., 2024. Lost in the middle: How language models use long contexts. TransactionsoftheAssociationforComputationalLinguistics12,157–173. URL:https://aclanthology.org/2024.tacl-1. 9/, doi:10.1162/tacl_a_00638
-
[26]
Mozilla, 23 Feb 2023. Mozilla Study: Data Privacy Labels for Most Top Apps in Google Play Store are False or Misleading .https: //www.mozillafoundation.org/en/campaigns/googles-data-safety-labels/
work page 2023
-
[27]
Newnowsecureresearchtargetsmobileappprivacyrisks:Whatyoudon’tseeishurtingyou
NowSecure,2025. Newnowsecureresearchtargetsmobileappprivacyrisks:Whatyoudon’tseeishurtingyou. https://www.nowsecure.com/
work page 2025
-
[28]
An empirical study of the non-determinism of chatgpt in code generation
Ouyang, S., Zhang, J.M., Harman, M., Wang, M., 2025. An empirical study of the non-determinism of chatgpt in code generation. ACM Transactions on Software Engineering and Methodology 34, 1–28
work page 2025
-
[29]
Verderame, L., Caputo, D., Romdhana, A., Merlo, A., 2020. On the (un) reliability of privacy policies in android apps, in: 2020 international joint conference on neural networks (IJCNN), IEEE. pp. 1–9
work page 2020
-
[30]
Xie, Q., Ramakrishnan, K., Li, F., 2025. Evaluating privacy policies under modern privacy laws at scale: An{LLM-Based}automated approach, in: 34th USENIX Security Symposium (USENIX Security 25), pp. 5797–5816
work page 2025
-
[31]
How usable are ios app privacy labels? Proceedings on Privacy Enhancing Technologies
Zhang, S., Feng, Y., Yao, Y., Cranor, L.F., Sadeh, N., 2022. How usable are ios app privacy labels? Proceedings on Privacy Enhancing Technologies
work page 2022
-
[32]
Zhou, X., Cao, S., Sun, X., Lo, D., 2025. Large language model for vulnerability detection and repair: Literature review and the road ahead. ACM Transactions on Software Engineering and Methodology 34, 1–31. A. LLM Analysis Prompt Templates This appendix reports the prompt templates used by PolicyGapper across the different stages of the analysis. Listing...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.