How to Approximate Inference with Subtractive Mixture Models
Pith reviewed 2026-05-10 08:16 UTC · model grok-4.3
The pith
Subtractive mixture models can be used for variational inference and importance sampling by designing special expectation estimators and learning schemes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Subtractive mixture models become practical for variational inference and importance sampling once several tailored expectation estimators and learning schemes are introduced to handle the lack of latent-variable semantics.
What carries the argument
Expectation estimators for IS and learning schemes for VI that operate directly on SMM parameters without requiring latent-variable sampling.
If this is right
- SMMs can serve as more expressive proposals than classical mixtures in both IS and VI.
- The new estimators allow unbiased or reduced-variance expectation estimates under negative coefficients.
- Learning procedures enable direct optimization of SMM parameters for variational objectives.
- Proposed fixes address instability in estimation and slower convergence during learning.
- Empirical results on distribution approximation demonstrate practical feasibility.
Where Pith is reading between the lines
- These techniques might extend to other inference settings that currently avoid negative-weight models, such as certain particle filters.
- Combining SMMs with gradient-based sampling could further reduce the computational overhead of the new estimators.
- Theoretical analysis of approximation error bounds under the proposed schemes would strengthen guarantees for high-dimensional use.
- The stability fixes might generalize to other mixture variants that include sign changes.
Load-bearing premise
Suitably designed estimators and schemes can produce stable, efficient approximations even though SMMs lack the latent-variable structure that classical mixtures use for sampling.
What would settle it
A controlled experiment on standard benchmarks where the proposed SMM estimators produce consistently higher variance or divergent learning compared to classical mixture baselines would show the methods do not overcome the missing latent semantics.
Figures












read the original abstract
Classical mixture models (MMs) are widely used tractable proposals for approximate inference settings such as variational inference (VI) and importance sampling (IS). Recently, mixture models with negative coefficients, called subtractive mixture models (SMMs), have been proposed as a potentially more expressive alternative. However, how to effectively use SMMs for VI and IS is still an open question as they do not provide latent variable semantics and therefore cannot use sampling schemes for classical MMs. In this work, we study how to circumvent this issue by designing several expectation estimators for IS and learning schemes for VI with SMMs, and we empirically evaluate them for distribution approximation. Finally, we discuss the additional challenges in estimation stability and learning efficiency that they carry and propose ways to overcome them. Code is available at: https://github.com/april-tools/delta-vi.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper addresses the challenge of using subtractive mixture models (SMMs) for approximate inference in variational inference (VI) and importance sampling (IS). Unlike classical mixture models, SMMs lack latent-variable semantics and thus cannot rely on standard sampling schemes. The authors propose several expectation estimators for IS and learning schemes for VI with SMMs, empirically evaluate these on distribution approximation tasks, and discuss associated challenges in estimation stability and learning efficiency along with mitigation strategies. Code is provided for reproducibility.
Significance. If the proposed estimators and schemes can be shown to deliver stable, low-variance inference on realistic targets, the work would meaningfully expand the set of tractable yet expressive proposal distributions available for VI and IS. The explicit treatment of stability and efficiency issues, together with open-source code, strengthens the contribution's practical value.
major comments (2)
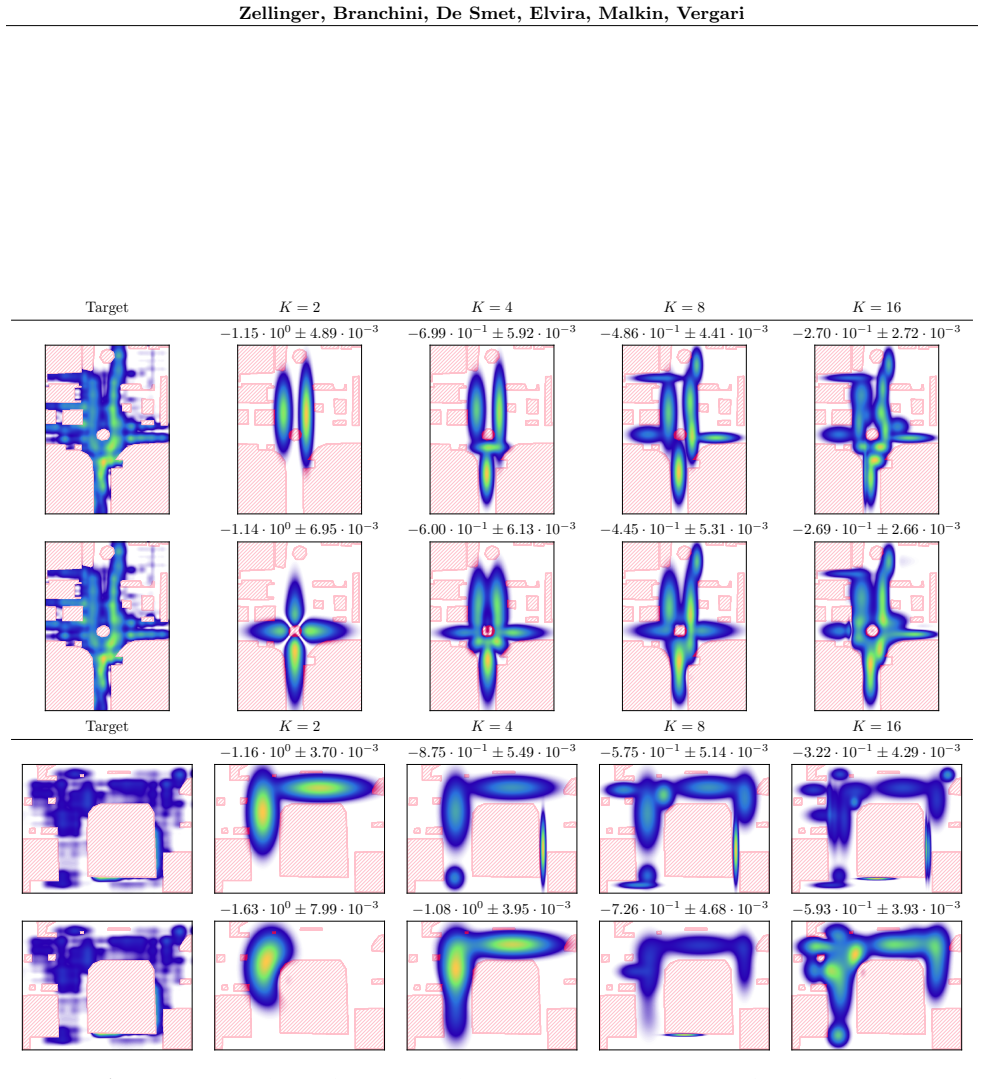
- [Abstract, §5] Abstract and empirical evaluation section: the central claim is that the designed estimators and learning schemes make SMMs 'usable' for VI and IS. However, the reported experiments are restricted to distribution approximation of simple target densities. No results are shown on downstream tasks such as posterior approximation, low-variance IS weight estimation, or convergence of VI on latent-variable models, leaving the usability claim untested.
- [§3] §3 (expectation estimators for IS): the paper notes 'additional challenges in estimation stability' but does not provide quantitative comparisons (e.g., effective sample size or variance of the estimators) against standard MM baselines on the same targets, making it difficult to judge whether the new estimators actually circumvent the lack of latent-variable semantics.
minor comments (2)
- [§2] Notation for the subtractive coefficients and the resulting density could be clarified with an explicit normalization step or a short derivation showing how the mixture remains a valid density.
- [§4] The discussion of learning schemes for VI would benefit from a concise pseudocode listing the gradient estimator and any variance-reduction techniques employed.
Simulated Author's Rebuttal
We thank the referee for the constructive review and positive assessment of the work's potential significance. We address each major comment below and will revise the manuscript to incorporate the suggested improvements.
read point-by-point responses
-
Referee: [Abstract, §5] Abstract and empirical evaluation section: the central claim is that the designed estimators and learning schemes make SMMs 'usable' for VI and IS. However, the reported experiments are restricted to distribution approximation of simple target densities. No results are shown on downstream tasks such as posterior approximation, low-variance IS weight estimation, or convergence of VI on latent-variable models, leaving the usability claim untested.
Authors: We agree that the experiments focus exclusively on distribution approximation of simple targets and do not demonstrate performance on downstream tasks such as posterior approximation or VI convergence on latent-variable models. The manuscript's abstract and §5 explicitly frame the evaluation as testing the estimators and learning schemes for distribution approximation, which directly validates the core mechanisms for handling the absence of latent-variable semantics. This was intended as a foundational step before more complex applications. To strengthen the usability claim, we will revise the manuscript by adding a new experiment on a simple posterior approximation task using SMMs within a VI framework, reporting convergence behavior and IS weight variance. We will also update the abstract to more precisely describe the scope of the current empirical results. revision: yes
-
Referee: [§3] §3 (expectation estimators for IS): the paper notes 'additional challenges in estimation stability' but does not provide quantitative comparisons (e.g., effective sample size or variance of the estimators) against standard MM baselines on the same targets, making it difficult to judge whether the new estimators actually circumvent the lack of latent-variable semantics.
Authors: The referee correctly identifies that while stability challenges are noted in §3, the manuscript lacks direct quantitative comparisons (such as estimator variance or effective sample size) against standard mixture model baselines on identical targets. Such metrics would better illustrate whether the proposed estimators address the limitations from missing latent-variable semantics. We will revise §3 and the empirical section to include these comparisons, adding tables and plots of variance and ESS for our estimators versus MM baselines on the same target densities used in the paper. revision: yes
Circularity Check
No circularity detected; estimators and schemes are independently designed
full rationale
The paper proposes new expectation estimators for IS and learning schemes for VI tailored to SMMs, then evaluates them empirically on distribution approximation tasks. No equations, derivations, or self-citations in the abstract or described content reduce any claimed result to a fitted parameter or prior input by construction. The approach extends standard VI/IS techniques to a new model class without redefining inputs in terms of outputs or relying on load-bearing self-citations for uniqueness. The derivation chain remains self-contained and externally falsifiable via the reported experiments.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
URLhttps: //doi.org/10.1093/imamat/8.1.80
doi: 10.1093/imamat/8.1.80. URLhttps: //doi.org/10.1093/imamat/8.1.80. Christopher M Bishop and Nasser M Nasrabadi.Pat- tern recognition and machine learning, volume 4. Springer, 2006. Denis Blessing, Xiaogang Jia, Johannes Esslinger, Francisco Vargas, and Gerhard Neumann. Be- yond elbos: A large-scale evaluation of variational methods for sampling. InFor...
-
[2]
Nicola Branchini and V´ ıctor Elvira
URLhttps://openreview.net/forum?id= fVg9YrSllr. Nicola Branchini and V´ ıctor Elvira. An adaptive mix- ture view of particle filters.Foundations of Data Science, 7(4), 2025. doi: 10.3934/fods.2024017. Monica F Bugallo, Victor Elvira, Luca Martino, David Luengo, Joaquin Miguez, and Petar M Djuric. Adaptive importance sampling: The past, the present, and th...
-
[3]
Statistical Science , author =
doi: 10.1214/18-STS668. Matteo Fasiolo, Fl´ avio Eler de Melo, and Simon Maskell. Langevin incremental mixture importance sampling.Statistics and Computing, 28(3):549–561, 2018. Axel Finke and Alexandre H Thiery. On importance- weighted autoencoders. 2019. URLhttps:// arxiv.org/abs/1907.10477. Michael B Giles. Multilevel monte carlo methods.Acta numerica,...
-
[5]
Oskar Kviman, Harald Melin, Hazal Koptagel, Vic- tor Elvira, and Jens Lagergren
URLhttps://arxiv.org/abs/2503.19466. Oskar Kviman, Harald Melin, Hazal Koptagel, Vic- tor Elvira, and Jens Lagergren. Multiple im- portance sampling ELBO and deep ensembles of variational approximations. In Gustau Camps- Valls, Francisco J. R. Ruiz, and Isabel Valera, edi- tors,International Conference on Artificial Intelli- gence and Statistics, AISTATS ...
-
[6]
Thomas M¨ uller, Brian McWilliams, Fabrice Rousselle, Markus Gross, and Jan Nov´ ak
URLhttp://proceedings.mlr.press/ v130/morningstar21b.html. Thomas M¨ uller, Brian McWilliams, Fabrice Rousselle, Markus Gross, and Jan Nov´ ak. Neural importance sampling.ACM Transactions on Graphics (ToG), 38(5):1–19, 2019. Radford M Neal. Slice sampling.The annals of statis- tics, 31(3):705–767, 2003. Art Owen and Yi Zhou. Safe and effective importance ...
-
[7]
Baibo Zhang and Changshui Zhang
URLhttp://proceedings.mlr.press/v80/ yao18a.html. Baibo Zhang and Changshui Zhang. Finite mixture models with negative components. In4th Interna- tional Conference on Machine Learning and Data Mining in Pattern Recognition (MLDM), pages 31–
- [8]
-
[9]
Yes, provided throughout the paper, primar- ily§2 and§3,§A,§B
For all models and algorithms presented, check if you include: (a) A clear description of the mathematical set- ting, assumptions, algorithm, and/or model. Yes, provided throughout the paper, primar- ily§2 and§3,§A,§B. (b) An analysis of the properties and complexity (time, space, sample size) of any algorithm. Yes, see§A.5. (c) (Optional) Anonymized sour...
-
[10]
For any theoretical claim, check if you include: (a) Statements of the full set of assumptions of all theoretical results. Yes, see Theorem 1, Prop. 1, and§B. (b) Complete proofs of all theoretical results. Yes, see§B. (c) Clear explanations of any assumptions. Yes, see Theorem 1, Prop. 1, and§B
-
[11]
Yes, seehttps://github.com/ april-tools/delta-vi
For all figures and tables that present empirical results, check if you include: (a) The code, data, and instructions needed to reproduce the main experimental results (either in the supplemental material or as a URL). Yes, seehttps://github.com/ april-tools/delta-vi. (b) All the training details (e.g., data splits, hy- perparameters, how they were chosen...
-
[12]
If you are using existing assets (e.g., code, data, models) or curating/releasing new assets, check if you include: (a) Citations of the creator If your work uses ex- isting assets. Yes, see§C. (b) The license information of the assets, if ap- plicable. Yes, see§C. (c) New assets either in the supplemental material or as a URL, if applicable. Yes, seehttp...
-
[13]
f(x(s) + ) p(x(s) + ) q(x(s) + ) # − Z− Z 1 S− S−X s=1 Eq−
If you used crowdsourcing or conducted research with human subjects, check if you include: (a) The full text of instructions given to partici- pants and screenshots. Not Applicable. (b) Descriptions of potential participant risks, with links to Institutional Review Board (IRB) approvals if applicable. Not Applica- ble. (c) The estimated hourly wage paid t...
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.