Recognition: unknown
AutoPKG: An Automated Framework for Dynamic E-commerce Product-Attribute Knowledge Graph Construction
Pith reviewed 2026-05-10 07:06 UTC · model grok-4.3
The pith
A multi-agent LLM framework automatically induces product types and attributes to build and maintain a consistent e-commerce knowledge graph from multimodal data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
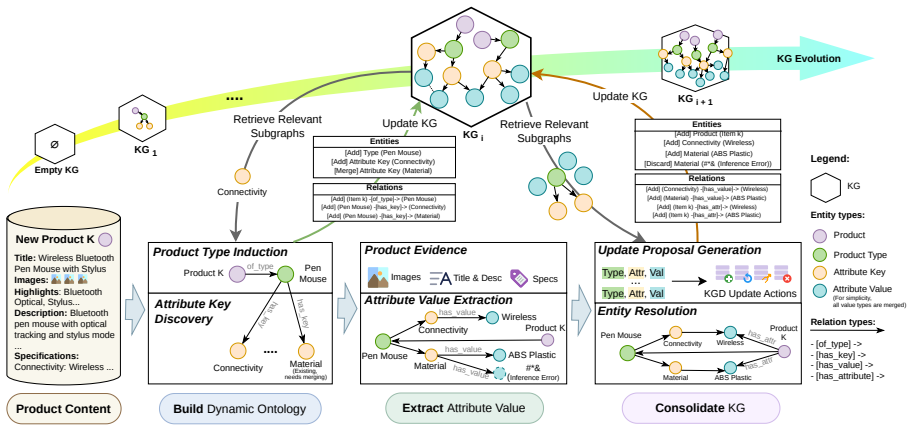
AutoPKG induces product types and type-specific attribute keys on demand, extracts attribute values from text and images, and consolidates updates through a centralized decision agent that maintains a globally consistent canonical graph. On a large marketplace catalog it reaches 0.953 weighted knowledge efficiency for types and 0.724 for keys, with 0.531 edge-level F1 for multimodal extraction. The same method raises edge-level exact-match F1 by 0.152 across public benchmarks and increases gross merchandise value in production A/B tests.
What carries the argument
The multi-agent LLM architecture with on-demand induction agents, multimodal extraction agents, and a single consolidation agent that enforces global consistency on the evolving product-attribute knowledge graph.
If this is right
- Product types and attribute keys can be added to the graph without manual ontology engineering while preserving high weighted knowledge efficiency.
- Multimodal value extraction reaches usable accuracy after canonicalization, outperforming prior methods by 0.152 F1 on benchmarks.
- Attributes produced by the framework raise gross merchandise value when deployed in badge, search, and recommendation surfaces.
- The dynamic construction process supports evolving catalogs without repeated full rebuilds.
Where Pith is reading between the lines
- The same consolidation mechanism could be tested on non-e-commerce domains where entities and relations must be induced from unstructured multimodal sources.
- If the central agent generalizes, it might reduce the need for periodic manual audits of knowledge graphs in other commercial settings.
- The reported gains suggest that downstream systems could be retrained on the auto-generated graph rather than on static labels.
Load-bearing premise
The central consolidation agent can reliably detect and correct inconsistencies introduced by the other agents across noisy, multimodal, and continually changing product descriptions without letting systematic errors accumulate in the canonical graph.
What would settle it
Running the full AutoPKG pipeline on a fresh e-commerce catalog for several months and observing either a drop in downstream task precision below the level of a static hand-curated ontology or an increase in contradictory attribute values would falsify the claim.
Figures
read the original abstract
Product attribute extraction in e-commerce is bottlenecked by ontologies that are inconsistent, incomplete, and costly to maintain. We present AutoPKG, a multi-agent Large Language Model (LLM) framework that automatically constructs a Product-attribute Knowledge Graph (PKG) from multimodal product content. AutoPKG induces product types and type-specific attribute keys on demand, extracts attribute values from text and images, and consolidates updates through a centralized decision agent that maintains a globally consistent canonical graph. We also propose an evaluation protocol for dynamic PKGs that measures type and key validity, consolidation quality, and edge-level accuracy for value assertions after canonicalization. On a large real-world marketplace catalog dataset from Lazada (Alibaba), AutoPKG achieves up to 0.953 Weighted Knowledge Efficiency (WKE) for product types, 0.724 WKE for attribute keys, and 0.531 edge-level F1 for multimodal value extraction. Across three public benchmarks, our method improves edge-level exact-match F1 by 0.152 and yields a precision gain of 0.208 on the attribute extraction application. Online A/B tests show that AutoPKG-derived attributes increase Gross Merchandise Value (GMV) in Badge by 3.81 percent, in Search by 5.32 percent, and in Recommendation by 7.89 percent, supporting the practical value of AutoPKG in production.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents AutoPKG, a multi-agent LLM framework for dynamically constructing a Product-Attribute Knowledge Graph (PKG) from multimodal e-commerce product content. It induces product types and type-specific attribute keys on demand, extracts values from text and images, and consolidates updates via a centralized decision agent to maintain a globally consistent canonical graph. An evaluation protocol for dynamic PKGs is proposed, with results on a large Lazada marketplace dataset showing WKE up to 0.953 (types) and 0.724 (keys), edge-level F1 of 0.531, benchmark improvements of 0.152 F1 and 0.208 precision, and GMV lifts of 3.81-7.89% in online A/B tests.
Significance. If the results hold under scrutiny, AutoPKG could meaningfully advance automated, scalable KG construction for e-commerce by reducing reliance on manual ontologies and delivering measurable business value through improved product attributes in search, recommendation, and badges.
major comments (3)
- [Abstract and §4] Abstract and §4 (Evaluation): The reported aggregate WKE (0.953/0.724) and edge-level F1 (0.531) scores, along with benchmark and A/B gains, do not include targeted breakdowns, ablations, or isolation of the consolidation agent's override decisions; this leaves unaddressed whether systematic biases from modalities, LLM agents, or product categories propagate into the canonical graph.
- [§3] §3 (Framework, Consolidation Agent): The central claim that the consolidation agent reliably resolves inconsistencies to produce a globally consistent canonical graph without systematic errors is load-bearing for the dynamic PKG contribution, yet no specific mechanisms, conflict-resolution rules, or validation experiments against multimodal noise or evolving types are detailed.
- [Abstract] Abstract: No information is provided on LLM agent prompts, error-handling procedures, data splits, or statistical significance testing for the GMV lifts (3.81%, 5.32%, 7.89%), which are required to substantiate the superiority claims and reproducibility of the empirical results.
minor comments (2)
- The definition and weighting scheme for Weighted Knowledge Efficiency (WKE) should be stated explicitly with a formula or pseudocode in the main text rather than referenced only in the abstract.
- Figure captions and table headers could more clearly distinguish between offline benchmark results and online A/B test conditions.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive suggestions. We address each of the major comments below and indicate the revisions we plan to make to improve the manuscript.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Evaluation): The reported aggregate WKE (0.953/0.724) and edge-level F1 (0.531) scores, along with benchmark and A/B gains, do not include targeted breakdowns, ablations, or isolation of the consolidation agent's override decisions; this leaves unaddressed whether systematic biases from modalities, LLM agents, or product categories propagate into the canonical graph.
Authors: We agree that providing breakdowns and ablations would offer greater insight into potential biases. The current evaluation focuses on aggregate performance across the Lazada dataset to demonstrate scalability. In the revised manuscript, we will include category-specific WKE and F1 scores, as well as an ablation study that isolates the consolidation agent's override decisions by comparing performance with and without it. This will help confirm that biases do not systematically propagate. revision: yes
-
Referee: [§3] §3 (Framework, Consolidation Agent): The central claim that the consolidation agent reliably resolves inconsistencies to produce a globally consistent canonical graph without systematic errors is load-bearing for the dynamic PKG contribution, yet no specific mechanisms, conflict-resolution rules, or validation experiments against multimodal noise or evolving types are detailed.
Authors: The manuscript describes the consolidation agent as using a centralized decision process to ensure global consistency. However, we acknowledge that more explicit details on the mechanisms are needed to fully support the claim. We will revise §3 to include specific conflict-resolution rules (such as priority based on source confidence and recency), pseudocode for the agent's logic, and additional experiments validating against multimodal inconsistencies and type evolution. revision: yes
-
Referee: [Abstract] Abstract: No information is provided on LLM agent prompts, error-handling procedures, data splits, or statistical significance testing for the GMV lifts (3.81%, 5.32%, 7.89%), which are required to substantiate the superiority claims and reproducibility of the empirical results.
Authors: The abstract is constrained by length, but detailed information on LLM prompts, error-handling, and data splits is included in the appendix and §4. We will add a reference to these sections in the abstract. For the GMV lifts from online A/B tests, we will include statistical significance testing in the revised version to substantiate the reported improvements. revision: partial
Circularity Check
No circularity: purely empirical framework with direct measurements
full rationale
The paper introduces a multi-agent LLM framework for dynamic product-attribute KG construction and evaluates it solely through empirical metrics (WKE for types/keys, edge-level F1, precision gains on benchmarks, and GMV lifts in A/B tests) on held-out real-world data. No equations, derivations, fitted parameters, or predictions appear; the consolidation agent is described as an operational component whose outputs are measured rather than defined into the results. All claims rest on external dataset performance and live experiments, remaining self-contained without reduction to inputs or self-citations.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM agents can induce valid product types and attributes from multimodal content with sufficient consistency for downstream consolidation
Reference graph
Works this paper leans on
-
[1]
InProceedings of the Fif- teenth ACM International Conference on Web Search and Data Mining, WSDM ’22, page 1256–1265, New York, NY , USA
Mave: A product dataset for multi-source attribute value extraction. InProceedings of the Fif- teenth ACM International Conference on Web Search and Data Mining, WSDM ’22, page 1256–1265, New York, NY , USA. Association for Computing Machin- ery. Changlong Yu, Xin Liu, Jefferson Maia, Yang Li, Tianyu Cao, Yifan Gao, Yangqiu Song, Rahul Goutam, Haiyang Zha...
-
[2]
COSMO: A large-scale e-commerce common sense knowledge generation and serving system at amazon. InCompanion of the 2024 International Conference on Management of Data, SIGMOD ’24, page 148–160, New York, NY , USA. Association for Computing Machinery. Changlong Yu, Weiqi Wang, Xin Liu, Jiaxin Bai, Yangqiu Song, Zheng Li, Yifan Gao, Tianyu Cao, and Bing Yin...
-
[3]
AliCG: Fine-grained and evolvable conceptual graph construction for semantic search at Alibaba. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, KDD ’21, page 3895–3905, New York, NY , USA. Association for Computing Machinery. Guineng Zheng, Subhabrata Mukherjee, Xin Luna Dong, and Feifei Li. 2018. OpenTag: Open attri...
-
[4]
Evaluate candidate validity and relevance to Node Type
-
[5]
Check each relevant KG node for strict synonymy using the STRICT SYNONYM POLICY
-
[6]
If a strict synonym match exists: • If existing name preferred→MERGE with that node_id • If candidate name preferred→REPLACE that node_id
-
[7]
Chair" instead of
If no strict synonym match exists→ADD Output format: • For ADD: output onlyADD • For MERGE or REPLACE: output the action in uppercase, followed by a space, then thenode_idof the matched existing node Example outputs: • MERGE 1749 • REPLACE 3943 • ADD Example output:MERGE 4587 Figure K.3: KGD prompt example (remove discard version). The DISCARD option has ...
2048
-
[8]
grey" ], brand:
Real Product Image and the Product Description you need to use: Product Description: [Title] Tommy Hilfiger Big Boys’ Short Sleeve 85 Shirt Product image 1 (if have): 2.Hypotheses list of attributes and specifications under review, it is provided for your reference: Attribute name 1: Neckline Attribute value 1: Henley Rest of attributes: - Brand (71009): ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.