Recognition: unknown
Better with Less: Tackling Heterogeneous Multi-Modal Image Joint Pretraining via Conditioned and Degraded Masked Autoencoder
Pith reviewed 2026-05-10 06:51 UTC · model grok-4.3
The pith
CoDe-MAE shows that high-resolution optical and SAR images can be jointly pretrained more effectively by using less rigid alignment between modalities.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
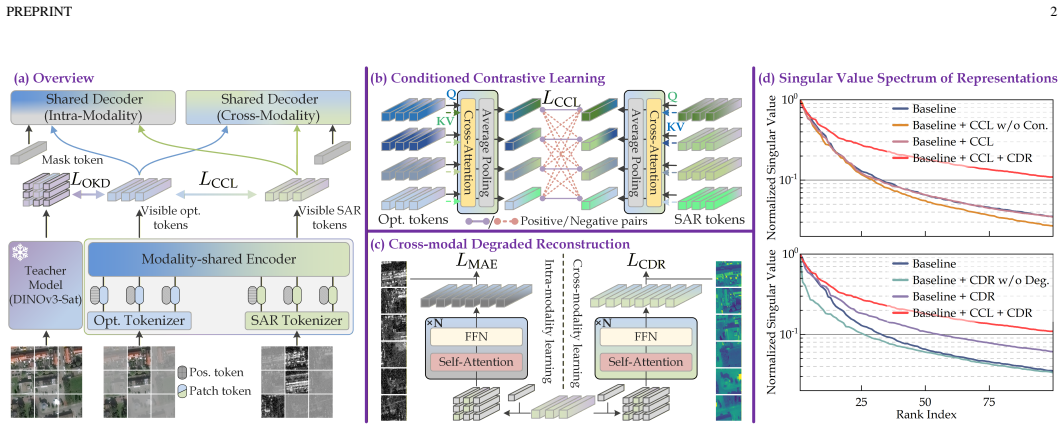
CoDe-MAE pioneers a better synergy with less alignment approach for heterogeneous multi-modal image joint pretraining. By mapping SAR into a pure semantic manifold via OKD, aligning shared consensus safely via CCL with gradient buffering, and stripping non-homologous features via CDR, it overcomes the Heterogeneity-Resolution Paradox and enables effective pretraining without representation degradation.
What carries the argument
CoDe-MAE, a masked autoencoder using Optical-anchored Knowledge Distillation (OKD), Conditioned Contrastive Learning (CCL), and Cross-Modal Degraded Reconstruction (CDR) to achieve modality synergy with reduced alignment.
Load-bearing premise
The three proposed components can reliably separate shared semantics from modality-specific physical signatures without introducing new suppression or contamination effects at high resolution.
What would settle it
Demonstrating that CoDe-MAE fails to prevent degradation or underperforms rigid alignment methods on a high-resolution optical-SAR dataset with different characteristics would falsify the central claim.
Figures





read the original abstract
Learning robust representations across extremely heterogeneous modalities remains a fundamental challenge in multi-modal vision. As a critical and profound instantiation of this challenge, high-resolution (HR) joint optical and synthetic aperture radar (SAR) pretraining seeks modality synergy to mutually enhance single-source representations; its potential is severely hindered by the Heterogeneity-Resolution Paradox: finer spatial scales drastically amplify the physical divergence between complex radar geometries and non-homologous optical textures. Consequently, migrating medium-resolution-oriented rigid alignment paradigms to HR scenarios triggers either severe feature suppression to force equivalence, or feature contamination driven by extreme epistemic uncertainty. Both extremes inevitably culminate in profound representation degradation and negative transfer. To overcome this bottleneck, we propose CoDe-MAE, pioneering a \textit{better synergy with less alignment} philosophy. First, Optical-anchored Knowledge Distillation (OKD) implicitly regularizes SAR's speckle noise by mapping it into a pure semantic manifold. Building on this, Conditioned Contrastive Learning (CCL) utilizes a gradient buffering mechanism to align shared consensus while safely preserving divergent physical signatures. Concurrently, Cross-Modal Degraded Reconstruction (CDR) deliberately strips non-homologous spectral pseudo-features, truncating the inherently ill-posed mapping to capture true structural invariants. Extensive analyses validate our theoretical claims. Pretrained on 1M samples, CoDe-MAE demonstrates remarkable data efficiency, successfully preventing representation degradation and establishing new state-of-the-art performance across diverse single- and bi-modal downstream tasks, substantially outperforming foundation models scaled on vastly larger datasets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CoDe-MAE, a conditioned and degraded masked autoencoder for joint pretraining on high-resolution optical and SAR images. It identifies the Heterogeneity-Resolution Paradox as the core obstacle to modality synergy at fine scales and introduces three components: Optical-anchored Knowledge Distillation (OKD) to map SAR speckle into a semantic manifold, Conditioned Contrastive Learning (CCL) that uses gradient buffering to align shared consensus while preserving physical divergence, and Cross-Modal Degraded Reconstruction (CDR) that strips non-homologous features to capture structural invariants. The central claim is that this 'better synergy with less alignment' approach, when pretrained on only 1M samples, prevents representation degradation and achieves new state-of-the-art results on diverse single- and bi-modal downstream tasks, substantially outperforming foundation models trained on much larger datasets.
Significance. If the empirical results hold, the work would be significant for multi-modal vision and remote-sensing applications. It offers a concrete alternative to rigid alignment and massive scaling by showing that targeted conditioning and deliberate degradation can yield data-efficient pretraining without negative transfer, potentially lowering the barrier to high-resolution multi-modal models where large aligned corpora are unavailable.
major comments (2)
- Abstract: the assertions of 'extensive analyses,' 'remarkable data efficiency,' and 'new state-of-the-art performance' across downstream tasks are unsupported by any quantitative numbers, ablation tables, or error bars in the provided text. This is load-bearing for the central claim that the three components enable SOTA results on 1M samples while outperforming larger-scale models.
- Method section (OKD/CCL/CDR descriptions): no equations, algorithmic pseudocode, or loss formulations are supplied to show how OKD maps speckle to a 'pure semantic manifold,' how CCL's gradient buffering avoids forced equivalence, or how CDR truncates the ill-posed mapping without introducing new epistemic uncertainty. These mechanisms are load-bearing for the claim that representation degradation is prevented at high resolution.
minor comments (1)
- Abstract: the phrase 'Heterogeneity-Resolution Paradox' is introduced without a concise definition or citation, which reduces immediate clarity for readers.
Simulated Author's Rebuttal
Thank you for the constructive feedback on our manuscript. We have reviewed the major comments carefully and provide point-by-point responses below. We agree that the abstract and method sections can be strengthened with additional quantitative support and formal details, and we will revise the manuscript accordingly.
read point-by-point responses
-
Referee: Abstract: the assertions of 'extensive analyses,' 'remarkable data efficiency,' and 'new state-of-the-art performance' across downstream tasks are unsupported by any quantitative numbers, ablation tables, or error bars in the provided text. This is load-bearing for the central claim that the three components enable SOTA results on 1M samples while outperforming larger-scale models.
Authors: We acknowledge that the abstract, as a concise summary, does not include specific numbers. The full manuscript contains extensive quantitative results, ablation studies, and performance tables with error bars in the experiments section, demonstrating the claimed data efficiency and SOTA outcomes on 1M samples versus larger-scale models. To make the abstract self-contained and directly address this point, we will revise it to incorporate key quantitative highlights such as specific mIoU gains and efficiency metrics. revision: yes
-
Referee: Method section (OKD/CCL/CDR descriptions): no equations, algorithmic pseudocode, or loss formulations are supplied to show how OKD maps speckle to a 'pure semantic manifold,' how CCL's gradient buffering avoids forced equivalence, or how CDR truncates the ill-posed mapping without introducing new epistemic uncertainty. These mechanisms are load-bearing for the claim that representation degradation is prevented at high resolution.
Authors: The current descriptions provide conceptual explanations of the components. To rigorously substantiate the mechanisms and support the claims about preventing representation degradation, we will add the formal loss formulations for OKD, CCL (including the gradient buffering term), and CDR, along with algorithmic pseudocode, in the revised method section. revision: yes
Circularity Check
No significant circularity in the derivation chain.
full rationale
The paper proposes CoDe-MAE with three novel components (OKD, CCL, CDR) to address the Heterogeneity-Resolution Paradox in high-resolution optical-SAR pretraining. No equations, derivations, or self-referential reductions appear in the provided text; the components are presented as independent mechanisms whose effectiveness is claimed to be validated by extensive analyses rather than by construction from the inputs. No fitted parameters are renamed as predictions, no uniqueness theorems are imported via self-citation, and no ansatzes are smuggled in. The central claims of data efficiency and SOTA performance rest on empirical results, not tautological equivalence to the problem statement.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption A pure semantic manifold exists for SAR images that can be reached via optical-anchored mapping without loss of useful signal.
- domain assumption Shared consensus between modalities can be aligned while safely preserving divergent physical signatures.
Reference graph
Works this paper leans on
-
[1]
Croma: Remote sensing representa- tions with contrastive radar-optical masked autoencoders,
A. Fuller, K. Millard, and J. Green, “Croma: Remote sensing representa- tions with contrastive radar-optical masked autoencoders,” inAdv. Neural Inform. Process. Syst., vol. 36, 2023, pp. 5506–5538
2023
-
[2]
Learning transferable visual models from natural language supervision,
A. Radfordet al., “Learning transferable visual models from natural language supervision,” inInt. Conf. Mach. Learn., 2021, pp. 8748–8763
2021
-
[3]
Skysense: A multi-modal remote sensing foundation model towards universal interpretation for earth observation imagery,
X. Guoet al., “Skysense: A multi-modal remote sensing foundation model towards universal interpretation for earth observation imagery,” inIEEE Conf. Comput. Vis. Pattern Recog., 2024, pp. 27 672–27 683
2024
-
[4]
Foundation models in remote sensing: Evolving from unimodality to multimodality,
D. Hong, C. Li, X. Li, G. Camps-Valls, and J. Chanussot, “Foundation models in remote sensing: Evolving from unimodality to multimodality,” IEEE Geosci. Remote Sens. Mag., 2026
2026
-
[5]
Mars: A multi-modality very-high-resolution remote sensing foundation model with cross-granularity meta-modality learning,
R. Yanget al., “Mars: A multi-modality very-high-resolution remote sensing foundation model with cross-granularity meta-modality learning,” inAAAI Conf. Artif. Intell., vol. 40, 2026, pp. 11 685–11 693
2026
-
[6]
BRIGHT: a globally distributed multimodal building dam- age assessment dataset with very-high-resolution for all-weather disaster response,
H. Chenet al., “BRIGHT: a globally distributed multimodal building dam- age assessment dataset with very-high-resolution for all-weather disaster response,”Earth Syst. Sci. Data, vol. 17, no. 11, pp. 6217–6253, 2025
2025
-
[7]
Spacenet 6: Multi-sensor all weather mapping dataset,
J. Shermeyeret al., “Spacenet 6: Multi-sensor all weather mapping dataset,” inIEEE Conf. Comput. Vis. Pattern Recog. Worksh., 2020
2020
-
[8]
Scale-mae: A scale-aware masked autoencoder for multiscale geospatial representation learning,
C. J. Reedet al., “Scale-mae: A scale-aware masked autoencoder for multiscale geospatial representation learning,” inInt. Conf. Comput. Vis., 2023
2023
-
[9]
Sen12ms–a curated dataset of georeferenced multi-spectral sentinel-1/2 imagery for deep learning and data fusion,
M. Schmitt, L. Hughes, C. Qiu, and X. Zhu, “Sen12ms–a curated dataset of georeferenced multi-spectral sentinel-1/2 imagery for deep learning and data fusion,”ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci., vol. 4, pp. 153–160, 2019
2019
-
[10]
Ssl4eo-s12: A large-scale multimodal, multitemporal dataset for self-supervised learning in earth observation [software and data sets],
Y . Wang, N. A. A. Braham, Z. Xiong, C. Liu, C. M. Albrecht, and X. X. Zhu, “Ssl4eo-s12: A large-scale multimodal, multitemporal dataset for self-supervised learning in earth observation [software and data sets],” IEEE Geosci. Remote Sens. Mag., vol. 11, no. 3, pp. 98–106, 2023
2023
-
[11]
Self-supervised vision transformers for land-cover segmentation and classification,
L. Scheibenreif, J. Hanna, M. Mommert, and D. Borth, “Self-supervised vision transformers for land-cover segmentation and classification,” in IEEE Conf. Comput. Vis. Pattern Recog. Worksh., 2022, pp. 1422–1431
2022
-
[12]
Self-supervised vision transformers for joint sar-optical representation learning,
Y . Wang, C. M. Albrecht, and X. X. Zhu, “Self-supervised vision transformers for joint sar-optical representation learning,” inIEEE Int. Geosci. Remote Sens. Symp., 2022, pp. 139–142
2022
-
[13]
Bridging remote sensors with multisensor geospatial foundation models,
B. Han, S. Zhang, X. Shi, and M. Reichstein, “Bridging remote sensors with multisensor geospatial foundation models,” inIEEE Conf. Comput. Vis. Pattern Recog., 2024, pp. 27 852–27 862
2024
-
[14]
What makes for good views for contrastive learning?
Y . Tian, C. Sun, B. Poole, D. Krishnan, C. Schmid, and P. Isola, “What makes for good views for contrastive learning?” inAdv. Neural Inform. Process. Syst., vol. 33, 2020, pp. 6827–6839
2020
-
[15]
Masked autoencoders are scalable vision learners,
K. He, X. Chen, S. Xie, Y . Li, P. Doll ´ar, and R. Girshick, “Masked autoencoders are scalable vision learners,” inIEEE Conf. Comput. Vis. Pattern Recog., 2022, pp. 16 000–16 009
2022
-
[16]
A simple framework for contrastive learning of visual representations,
T. Chen, S. Kornblith, M. Norouzi, and G. Hinton, “A simple framework for contrastive learning of visual representations,” inInt. Conf. Mach. Learn., 2020, pp. 1597–1607
2020
-
[17]
O. Sim ´eoniet al., “Dinov3,”arXiv preprint:2508.10104, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Integrally pre-trained transformer pyramid networks,
Y . Tianet al., “Integrally pre-trained transformer pyramid networks,” in IEEE Conf. Comput. Vis. Pattern Recog., 2023, pp. 18 610–18 620
2023
-
[19]
Flair: Vlm with fine-grained language-informed image representations,
R. Xiao, S. Kim, M.-I. Georgescu, Z. Akata, and S. Alaniz, “Flair: Vlm with fine-grained language-informed image representations,” inIEEE Conf. Comput. Vis. Pattern Recog., 2025, pp. 24 884–24 894
2025
-
[20]
Decoupling common and unique representations for multimodal self-supervised learning,
Y . Wang, C. M. Albrecht, N. A. A. Braham, C. Liu, Z. Xiong, and X. X. Zhu, “Decoupling common and unique representations for multimodal self-supervised learning,” inEur. Conf. Comput. Vis., 2024, pp. 286–303
2024
-
[21]
Sarmae: Masked autoencoder for sar representation learn- ing,
D. Liuet al., “Sarmae: Masked autoencoder for sar representation learn- ing,”arXiv preprint:2512.16635, 2025
-
[22]
The qxs-saropt dataset for deep learning in sar-optical data fusion,
M. Huanget al., “The qxs-saropt dataset for deep learning in sar-optical data fusion,”arXiv preprint:2103.08259, 2021
-
[23]
A dual-stream high resolution network: Deep fusion of gf-2 and gf-3 data for land cover classification,
B. Renet al., “A dual-stream high resolution network: Deep fusion of gf-2 and gf-3 data for land cover classification,”Int. J. Appl. Earth Obs. Geoinf., vol. 112, p. 102896, 2022
2022
-
[24]
Mcanet: A joint semantic segmentation framework of optical and sar images for land use classification,
X. Liet al., “Mcanet: A joint semantic segmentation framework of optical and sar images for land use classification,”Int. J. Appl. Earth Obs. Geoinf., vol. 106, p. 102638, 2022
2022
-
[25]
2023 ieee grss data fusion contest: Large-scale fine- grained building classification for semantic urban reconstruction [technical committees],
C. Perselloet al., “2023 ieee grss data fusion contest: Large-scale fine- grained building classification for semantic urban reconstruction [technical committees],”IEEE Geosci. Remote Sens. Mag., 2023
2023
-
[26]
Cross-modal gaussian local- ization distillation for optical information guided sar object detection,
C. Wang, L. Luo, W. Fang, and J. Yang, “Cross-modal gaussian local- ization distillation for optical information guided sar object detection,” in IEEE Int. Conf. Acoust. Speech Signal Process., 2025
2025
-
[27]
Rmso-convnext: A lightweight cnn network for robust sar and optical image matching under strong noise interference,
C. Yang, G. Gong, C. Liu, J. Deng, and Y . Ye, “Rmso-convnext: A lightweight cnn network for robust sar and optical image matching under strong noise interference,”IEEE Trans. Geosci. Remote Sens., vol. 63, 2025
2025
-
[28]
J. Xia, H. Chen, C. Broni-Bediako, Y . Wei, J. Song, and N. Yokoya, “Openearthmap-sar: A benchmark synthetic aperture radar dataset for global high-resolution land cover mapping,”arXiv preprint:2501.10891, 2025
-
[29]
Remote sensing meta modal representation for missing modality land cover mapping: From earthmiss dataset to metars method,
Y . Zhou, A. Ma, J. Wang, Z. Chen, and Y . Zhong, “Remote sensing meta modal representation for missing modality land cover mapping: From earthmiss dataset to metars method,”Remote Sens. Environ., vol. 333, p. 115132, 2026
2026
-
[30]
Osdataset2.0: Sar-optical image matching dataset and evaluation benchmark,
Y . Xianget al., “Osdataset2.0: Sar-optical image matching dataset and evaluation benchmark,”Journal of Radars, 2025
2025
-
[31]
Accurate object localization in remote sensing images based on convolutional neural networks,
Y . Long, Y . Gong, Z. Xiao, and Q. Liu, “Accurate object localization in remote sensing images based on convolutional neural networks,”IEEE Trans. Geosci. Remote Sens., vol. 55, no. 5, pp. 2486–2498, 2017
2017
-
[32]
Fair1m: A benchmark dataset for fine-grained object recog- nition in high-resolution remote sensing imagery,
X. Sunet al., “Fair1m: A benchmark dataset for fine-grained object recog- nition in high-resolution remote sensing imagery,”ISPRS-J. Photogramm. Remote Sens., vol. 184, pp. 116–130, 2022
2022
-
[33]
Fair-csar: A benchmark dataset for fine-grained object detection and recognition based on single-look complex sar images,
Y . Wuet al., “Fair-csar: A benchmark dataset for fine-grained object detection and recognition based on single-look complex sar images,”IEEE Trans. Geosci. Remote Sens., vol. 63, 2024
2024
-
[34]
Saratr-x: Toward building a foundation model for sar target recognition,
W. Li, W. Yang, Y . Hou, L. Liu, Y . Liu, and X. Li, “Saratr-x: Toward building a foundation model for sar target recognition,”IEEE Trans. Image Process., vol. 34, pp. 869–884, 2025
2025
-
[35]
Atrnet-star: A large dataset and benchmark towards remote sensing object recognition in the wild,
Y . Liuet al., “Atrnet-star: A large dataset and benchmark towards remote sensing object recognition in the wild,”IEEE Trans. Pattern Anal. Mach. Intell., 2026
2026
-
[36]
Feature guided masked autoencoder for self-supervised learning in remote sens- ing,
Y . Wang, H. H. Hern ´andez, C. M. Albrecht, and X. X. Zhu, “Feature guided masked autoencoder for self-supervised learning in remote sens- ing,”IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens., vol. 18, pp. 321–336, 2025
2025
-
[37]
Sardet-100k: Towards open-source benchmark and toolkit for large-scale sar object detection,
Y . Liet al., “Sardet-100k: Towards open-source benchmark and toolkit for large-scale sar object detection,” inAdv. Neural Inform. Process. Syst., vol. 37, 2024, pp. 128 430–128 461
2024
-
[38]
Harnessing massive satellite imagery with efficient masked image modeling,
F. Wanget al., “Harnessing massive satellite imagery with efficient masked image modeling,” inInt. Conf. Comput. Vis., 2025, pp. 6935–6947
2025
-
[39]
Ringmo: A remote sensing foundation model with masked image modeling,
X. Sunet al., “Ringmo: A remote sensing foundation model with masked image modeling,”IEEE Trans. Geosci. Remote Sens., vol. 61, 2022. PREPRINT 10 (a) DIOR (b) SARDet-100K Fig. 5. CoDe-MAE prediction on detection task. PREPRINT 11 (a) LoveDA (b) BRIGHT Fig. 6. CoDe-MAE prediction on segmentation task. PREPRINT 12
2022
-
[40]
Hivit: A simpler and more efficient design of hierarchical vision transformer,
X. Zhanget al., “Hivit: A simpler and more efficient design of hierarchical vision transformer,” inInt. Conf. Learn. Represent., 2023
2023
-
[41]
UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction
L. McInnes, J. Healy, and J. Melville, “UMAP: Uniform Mani- fold Approximation and Projection for Dimension Reduction,”arXiv preprint:1802.03426, 2018
work page internal anchor Pith review arXiv 2018
-
[42]
Bigearthnet-mm: A large-scale, multimodal, multilabel benchmark archive for remote sensing image classification and retrieval [software and data sets],
G. Sumbulet al., “Bigearthnet-mm: A large-scale, multimodal, multilabel benchmark archive for remote sensing image classification and retrieval [software and data sets],”IEEE Geosci. Remote Sens. Mag., vol. 9, no. 3, pp. 174–180, 2021
2021
-
[43]
Satvit: Pretraining transformers for earth observation,
A. Fuller, K. Millard, and J. R. Green, “Satvit: Pretraining transformers for earth observation,”IEEE Geosci. Remote Sens. Lett., vol. 19, 2022
2022
-
[44]
Neural plasticity-inspired founda- tion model for observing the Earth crossing modalities
Z. Xionget al., “Neural plasticity-inspired multimodal foundation model for earth observation,”arXiv preprint:2403.15356, 2024
-
[45]
Asanet: Asymmetric semantic aligning network for rgb and sar image land cover classification,
P. Zhang, B. Peng, C. Lu, Q. Huang, and D. Liu, “Asanet: Asymmetric semantic aligning network for rgb and sar image land cover classification,” ISPRS-J. Photogramm. Remote Sens., vol. 218, pp. 574–587, 2024
2024
-
[46]
2020 ieee grss data fusion contest,
M. Schmitt, L. Hughes, P. Ghamisi, N. Yokoya, and R. H ¨ansch, “2020 ieee grss data fusion contest,”IEEE Dataport, 2019
2020
-
[47]
Dual- tasks siamese transformer framework for building damage assessment,
H. Chen, E. Nemni, S. Vallecorsa, X. Li, C. Wu, and L. Bromley, “Dual- tasks siamese transformer framework for building damage assessment,” in IEEE Int. Geosci. Remote Sens. Symp., 2022, pp. 1600–1603
2022
-
[48]
Satmae: Pre-training transformers for temporal and multi- spectral satellite imagery,
Y . Conget al., “Satmae: Pre-training transformers for temporal and multi- spectral satellite imagery,” inAdv. Neural Inform. Process. Syst., vol. 35, 2022, pp. 197–211
2022
-
[49]
Towards geospatial foundation models via continual pretraining,
M. Mendieta, B. Han, X. Shi, Y . Zhu, and C. Chen, “Towards geospatial foundation models via continual pretraining,” inInt. Conf. Comput. Vis., 2023, pp. 16 806–16 816
2023
-
[50]
Sat- laspretrain: A large-scale dataset for remote sensing image understanding,
F. Bastani, P. Wolters, R. Gupta, J. Ferdinando, and A. Kembhavi, “Sat- laspretrain: A large-scale dataset for remote sensing image understanding,” inInt. Conf. Comput. Vis., 2023, pp. 16 772–16 782
2023
-
[51]
Advancing plain vision transformer toward remote sensing foundation model,
D. Wanget al., “Advancing plain vision transformer toward remote sensing foundation model,”IEEE Trans. Geosci. Remote Sens., vol. 61, 2022
2022
-
[52]
Aid: A benchmark data set for performance evaluation of aerial scene classification,
G.-S. Xiaet al., “Aid: A benchmark data set for performance evaluation of aerial scene classification,”IEEE Trans. Geosci. Remote Sens., vol. 55, no. 7, pp. 3965–3981, 2017
2017
-
[53]
Remote sensing image scene classification: Benchmark and state of the art,
G. Cheng, J. Han, and X. Lu, “Remote sensing image scene classification: Benchmark and state of the art,”Proc. IEEE, 2017
2017
-
[54]
Object detection in optical remote sensing images: A survey and a new benchmark,
K. Li, G. Wan, G. Cheng, L. Meng, and J. Han, “Object detection in optical remote sensing images: A survey and a new benchmark,”ISPRS- J. Photogramm. Remote Sens., vol. 159, pp. 296–307, 2020
2020
-
[55]
Loveda: A remote sensing land-cover dataset for domain adaptive semantic segmentation,
J. Wang, Z. Zheng, A. Ma, X. Lu, and Y . Zhong, “Loveda: A remote sensing land-cover dataset for domain adaptive semantic segmentation,” inAdv. Neural Inform. Process. Syst., 2021
2021
-
[56]
Fusar-ship: Building a high-resolution sar-ais matchup dataset of gaofen-3 for ship detection and recognition,
X. Hou, W. Ao, Q. Song, J. Lai, H. Wang, and F. Xu, “Fusar-ship: Building a high-resolution sar-ais matchup dataset of gaofen-3 for ship detection and recognition,”Sci. China Inf. Sci., vol. 63, no. 4, p. 140303, 2020
2020
-
[57]
Scan: Scattering characteristics analysis network for few-shot aircraft classification in high-resolution sar images,
X. Sun, Y . Lv, Z. Wang, and K. Fu, “Scan: Scattering characteristics analysis network for few-shot aircraft classification in high-resolution sar images,”IEEE Trans. Geosci. Remote Sens., vol. 60, 2022
2022
-
[58]
Predicting gradient is better: Exploring self-supervised learning for sar atr with a joint-embedding predictive architecture,
W. Liet al., “Predicting gradient is better: Exploring self-supervised learning for sar atr with a joint-embedding predictive architecture,”ISPRS- J. Photogramm. Remote Sens., vol. 218, pp. 326–338, 2024
2024
-
[59]
Summit: A sar foundation model with multiple auxiliary tasks enhanced intrinsic characteristics,
Y . Du, Y . Chen, L. Huang, Y . Yang, P. Ghamisi, and Q. Du, “Summit: A sar foundation model with multiple auxiliary tasks enhanced intrinsic characteristics,”Int. J. Appl. Earth Obs. Geoinf., vol. 141, p. 104624, 2025
2025
-
[60]
Eurosat: A novel dataset and deep learning benchmark for land use and land cover classification,
P. Helber, B. Bischke, A. Dengel, and D. Borth, “Eurosat: A novel dataset and deep learning benchmark for land use and land cover classification,” IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens., 2019
2019
-
[61]
The Air Force Moving and Stationary Target Recognition Database
“The Air Force Moving and Stationary Target Recognition Database.” [Online]. Available: https://www.sdms.afrl.af.mil/datasets/mstar/
-
[62]
Faster r-cnn: Towards real-time object detection with region proposal networks,
S. Ren, K. He, R. Girshick, and J. Sun, “Faster r-cnn: Towards real-time object detection with region proposal networks,”NeurIPS, 2015
2015
-
[63]
Unified perceptual parsing for scene understanding,
T. Xiao, Y . Liu, B. Zhou, Y . Jiang, and J. Sun, “Unified perceptual parsing for scene understanding,” inEur. Conf. Comput. Vis., 2018
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.