Multimodal Fusion of Histopathology Images and Electronic Health Records for Early Breast Cancer Diagnosis
Pith reviewed 2026-05-10 06:33 UTC · model grok-4.3
The pith
Intermediate fusion of histopathology images and EHR data reaches 0.997 macro AUC for breast cancer diagnosis.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors demonstrate that an intermediate-fusion model, formed by concatenating latent vectors from a ResNet-18 convolutional network processing histopathology patches and from tabular models on electronic health records, achieves a macro-average AUC of 0.997 on breast cancer classification tasks. This exceeds the performance of unimodal image models like ResNet-18 and unimodal EHR models like XGBoost. The largest gains appear in the mitosis category, which is class-imbalanced yet diagnostically important, reaching an AUC of 0.994. Interpretability via Grad-CAM and SHAP confirms alignment with pathological and clinical standards.
What carries the argument
The intermediate fusion step that concatenates latent representations extracted separately from the image CNN and the EHR tabular model before feeding them into a final classifier.
Load-bearing premise
The latent representations from the image and tabular models are complementary and that their simple concatenation captures joint information without introducing redundancy or noise from mismatched data distributions.
What would settle it
An independent test set where the intermediate fusion model shows no AUC improvement over the best unimodal baseline on the mitosis category would falsify the claim of meaningful multimodal gains.
Figures







read the original abstract
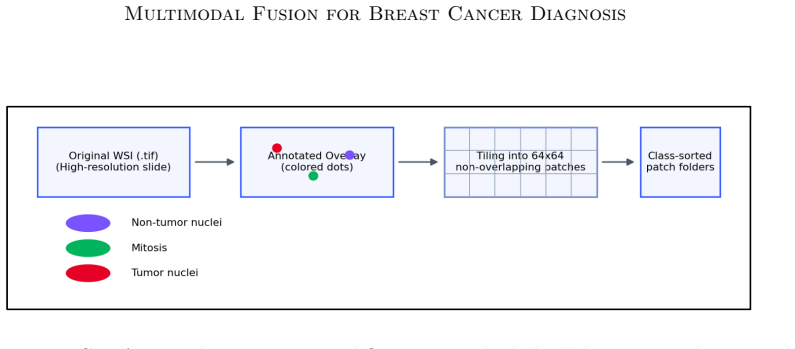
Breast cancer is a leading cause of cancer-related mortality worldwide, and timely accurate diagnosis is critical to improving survival outcomes. While convolutional neural networks (CNNs) have demonstrated strong performance on histopathology image classification, and machine learning models on structured electronic health records (EHR) have shown utility for clinical risk stratification, most existing work treats these modalities in isolation. This paper presents a systematic multimodal framework that integrates patch-level histopathology features from the BreCaHAD dataset with structured clinical data from MIMIC-IV. We train and evaluate unimodal image models (a simple CNN baseline and ResNet-18 with transfer learning), unimodal tabular models (XGBoost and a multilayer perceptron), and an intermediate-fusion model that concatenates latent representations from both modalities. ResNet-18 achieves near-perfect accuracy (1.000) and AUC (1.000) on three-class patch-level classification, while XGBoost achieves 98% accuracy on the EHR prediction task. The intermediate fusion model yields a macro-average AUC of 0.997, outperforming all unimodal baselines and delivering the largest improvements on the diagnostically critical but class-imbalanced mitosis category (AUC 0.994). Grad-CAM and SHAP interpretability analyses validate that model decisions align with established pathological and clinical criteria. Our results demonstrate that multimodal integration delivers meaningful improvements in both predictive performance and clinical transparency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a multimodal framework for early breast cancer diagnosis that integrates patch-level histopathology images from the BreCaHAD dataset with structured EHR data from MIMIC-IV. It evaluates unimodal baselines (CNN and ResNet-18 on images; XGBoost and MLP on tabular data) and an intermediate-fusion model that concatenates latent representations from both modalities, reporting a macro-average AUC of 0.997 for fusion (with AUC 0.994 on the mitosis class) that outperforms unimodal models, along with Grad-CAM and SHAP interpretability analyses.
Significance. If the results hold on properly aligned multimodal patient data, the work would demonstrate the value of intermediate fusion for boosting performance on diagnostically critical but imbalanced classes and for providing clinically aligned interpretability. The systematic comparison of unimodal and fusion strategies on public datasets is a strength that could guide future multimodal medical imaging research.
major comments (1)
- [Abstract and dataset description] Abstract and dataset description: the intermediate-fusion model concatenates latents from a ResNet-18 trained on BreCaHAD patches and an XGBoost/MLP trained on MIMIC-IV records, yet these source datasets derive from completely disjoint patient cohorts with no shared identifiers, slide-level metadata, or alignment procedure described anywhere in the manuscript. Consequently the concatenated vectors do not correspond to real clinical instances, so the reported performance gains (macro AUC 0.997, mitosis AUC 0.994) cannot be interpreted as evidence of genuine cross-modal interaction learning.
minor comments (1)
- [Results section] Results section: the perfect accuracy/AUC of 1.000 on the image task and 0.997 on fusion are reported without error bars, confidence intervals, explicit train-test split ratios, class-balancing details, or leakage checks; these omissions make the unusually high figures difficult to evaluate even if the pairing issue were resolved.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive review. We address the single major comment below and describe the revisions that will be made to the manuscript.
read point-by-point responses
-
Referee: [Abstract and dataset description] Abstract and dataset description: the intermediate-fusion model concatenates latents from a ResNet-18 trained on BreCaHAD patches and an XGBoost/MLP trained on MIMIC-IV records, yet these source datasets derive from completely disjoint patient cohorts with no shared identifiers, slide-level metadata, or alignment procedure described anywhere in the manuscript. Consequently the concatenated vectors do not correspond to real clinical instances, so the reported performance gains (macro AUC 0.997, mitosis AUC 0.994) cannot be interpreted as evidence of genuine cross-modal interaction learning.
Authors: We agree with the referee that BreCaHAD and MIMIC-IV are drawn from completely disjoint patient cohorts and that the manuscript contains no alignment procedure or shared identifiers. The original work concatenated independently extracted latent vectors without any patient-level matching, which means the reported fusion results do not reflect genuine cross-modal interaction on aligned clinical cases. We will revise the abstract, methods, results, and discussion sections to explicitly state this limitation, remove any implication of clinical multimodal fusion, and reframe the contribution as a controlled proof-of-concept study of feature-level concatenation across two public datasets. The unimodal baselines and interpretability analyses will remain, but all performance claims will be qualified accordingly. These changes will be reflected in the next manuscript version. revision: yes
Circularity Check
No circularity; results are measured empirical outcomes on public datasets
full rationale
The paper reports directly measured performance metrics (AUC, accuracy) from training CNN/ResNet on BreCaHAD patches and XGBoost/MLP on MIMIC-IV records, followed by standard latent concatenation for fusion. No equations, predictions, or derivations reduce to inputs by construction. No self-citations, uniqueness theorems, or ansatzes are invoked as load-bearing steps. The central claims rest on external benchmark evaluation rather than self-referential fitting or renaming.
Axiom & Free-Parameter Ledger
free parameters (2)
- latent dimension for each modality before concatenation
- class weighting or decision threshold for mitosis category
axioms (2)
- domain assumption Patch-level histopathology images from BreCaHAD contain sufficient information for reliable three-class classification
- domain assumption Structured fields in MIMIC-IV are relevant and aligned with breast cancer diagnostic labels
Reference graph
Works this paper leans on
-
[1]
Lundberg, Gabriel Erion, Hugh Chen, Alex DeGrave, Jordan M
doi: 10.1038/s42256-019-0138-9. Riccardo Miotto, Li Li, Brian A. Kidd, and Joel T. Dudley. Deep patient: An unsuper- vised representation to predict the future of patients from the electronic health records. Scientific Reports, 6:26094, 2016. doi: 10.1038/srep26094. 17 Multimodal Fusion for Breast Cancer Diagnosis Pooya Mobadersany, Safoora Yousefi, Moham...
-
[2]
doi: 10.1145/2939672.2939778. Ramprasaath R. Selvaraju, Michael Cogswell, Abhishek Das, et al. Grad-CAM: Visual explanations from deep networks via gradient-based localization. InProceedings of the IEEE International Conference on Computer Vision (ICCV), pages 618–626, 2017. Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-s...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.