Recognition: unknown
OptiMVMap: Offline Vectorized Map Construction via Optimal Multi-vehicle Perspectives
Pith reviewed 2026-05-10 06:24 UTC · model grok-4.3
The pith
Selecting a compact set of helper vehicles based on uncertainty reduction produces more accurate offline vectorized maps than using all views or single-vehicle data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
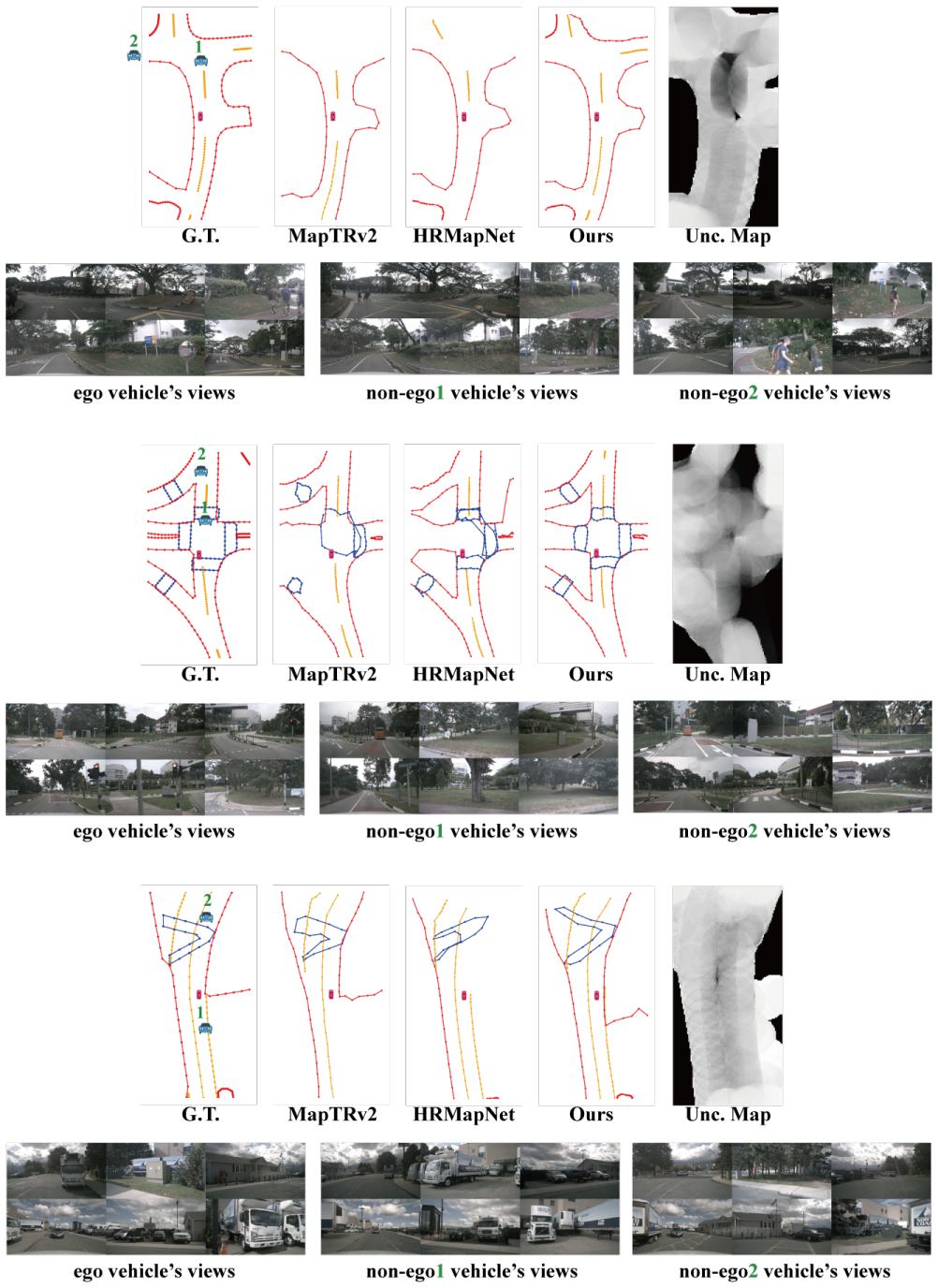
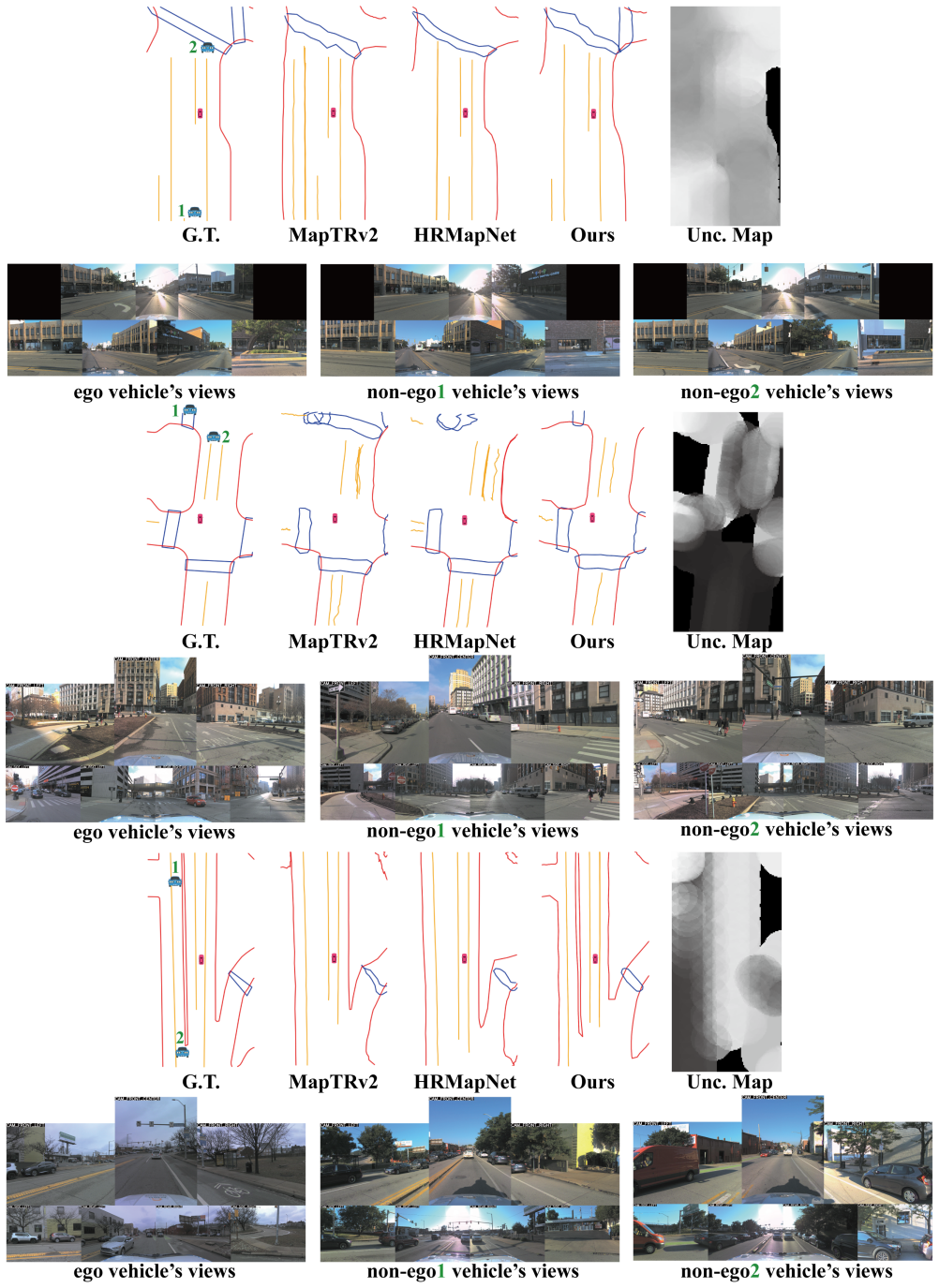
OptiMVMap reformulates multi-vehicle mapping as a select-then-fuse problem. An Optimal Vehicle Selection module identifies a compact subset of helper vehicles that maximally reduce ego-centric uncertainty in occluded regions. Cross-Vehicle Attention then performs pose-tolerant alignment and a Semantic-aware Noise Filter suppresses occlusion artifacts before BEV-level fusion, yielding more complete and topologically faithful maps with substantially fewer views than indiscriminate aggregation.
What carries the argument
Optimal Vehicle Selection (OVS) module, which identifies a compact subset of surrounding vehicles to cover occluded regions and reduce ego-centric uncertainty before fusion.
Load-bearing premise
The Optimal Vehicle Selection module can reliably identify a small set of helper vehicles whose views maximally reduce uncertainty in occluded areas, and the subsequent attention and filter steps can suppress noise without removing useful map information.
What would settle it
On nuScenes, replace the uncertainty-guided OVS with random vehicle selection or full aggregation and measure whether the reported mAP gains of +10.5 over MapTRv2 disappear or reverse.
Figures








read the original abstract
Offline vectorized maps constitute critical infrastructure for high-precision autonomous driving and mapping services. Existing approaches rely predominantly on single ego-vehicle trajectories, which fundamentally suffer from viewpoint insufficiency: while memory-based methods extend observation time by aggregating ego-trajectory frames, they lack the spatial diversity needed to reveal occluded regions. Incorporating views from surrounding vehicles offers complementary perspectives, yet naive fusion introduces three key challenges: computational cost from large candidate pools, redundancy from near-collinear viewpoints, and noise from pose errors and occlusion artifacts. We present OptiMVMap, which reformulates multi-vehicle mapping as a select-then-fuse problem to address these challenges systematically. An Optimal Vehicle Selection (OVS) module strategically identifies a compact subset of helpers that maximally reduce ego-centric uncertainty in occluded regions, addressing computation and redundancy challenges. Cross-Vehicle Attention (CVA) and Semantic-aware Noise Filter (SNF) then perform pose-tolerant alignment and artifact suppression before BEV-level fusion, addressing the noise challenge. This targeted pipeline yields more complete and topologically faithful maps with substantially fewer views than indiscriminate aggregation. On nuScenes and Argoverse2, OptiMVMap improves MapTRv2 by +10.5 mAP and +9.3 mAP, respectively, and surpasses memory-augmented baselines MVMap and HRMapNet by +6.2 mAP and +3.8 mAP on nuScenes. These results demonstrate that uncertainty-guided selection of helper vehicles is essential for efficient and accurate multi-vehicle vectorized mapping. The code is released at https://github.com/DanZeDong/OptiMVMap.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces OptiMVMap, a select-then-fuse pipeline for offline vectorized map construction from multi-vehicle data. It proposes an Optimal Vehicle Selection (OVS) module to identify a compact subset of helper vehicles that maximally reduce ego-centric uncertainty in occluded areas, followed by Cross-Vehicle Attention (CVA) for pose-tolerant alignment and Semantic-aware Noise Filter (SNF) for artifact suppression before BEV fusion. Experiments on nuScenes and Argoverse2 report gains of +10.5 mAP and +9.3 mAP over MapTRv2, plus +6.2 mAP and +3.8 mAP over memory-augmented baselines MVMap and HRMapNet on nuScenes, with code released.
Significance. If the reported gains hold under the provided ablations and controls, the work offers a practical advance for leveraging V2X data in high-definition mapping: it demonstrates that uncertainty-guided selection enables more complete, topologically faithful maps with far fewer views than indiscriminate aggregation or ego-only memory methods. The explicit algorithmic detail on OVS, CVA, and SNF plus code release are strengths that support reproducibility and potential adoption in autonomous driving pipelines.
minor comments (3)
- The abstract states that OVS addresses 'computation and redundancy challenges' by selecting a compact subset, but the main text should explicitly report the average number of selected helper vehicles (and total candidate pool size) across the test scenes to quantify the claimed efficiency gain.
- In the experimental section, the ablation studies on OVS, CVA, and SNF are referenced as supporting the gains; adding a table row that isolates the contribution of each module (with and without the others) would make the load-bearing role of the select-then-fuse design clearer.
- Figure captions for the qualitative results should include the exact number of views used in the OptiMVMap vs. baseline visualizations to allow direct visual comparison of the 'substantially fewer views' claim.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation, recognition of the practical advances in uncertainty-guided multi-vehicle selection for vectorized mapping, and the recommendation for minor revision. We appreciate the emphasis on reproducibility through code release and the strengths identified in the OVS, CVA, and SNF components.
Circularity Check
No significant circularity
full rationale
The paper presents an empirical engineering pipeline for multi-vehicle vectorized mapping, consisting of algorithmic modules (OVS for vehicle selection, CVA for alignment, SNF for noise filtering) that are described procedurally and validated via ablations and quantitative gains on external public datasets (nuScenes +10.5 mAP over MapTRv2, Argoverse2 +9.3 mAP). No equations, first-principles derivations, or predictions are given that reduce by construction to fitted parameters, self-definitions, or self-citation chains. The central claim rests on observable performance differences rather than tautological reformulations, making the approach self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Nuscenes: A multi- modal dataset for autonomous driving
Holger Caesar, Varun Bankiti, Alex H Lang, Sourabh V ora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Gi- ancarlo Baldan, and Oscar Beijbom. Nuscenes: A multi- modal dataset for autonomous driving. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020. 6
2020
-
[2]
Maptracker: Tracking with strided mem- ory fusion for consistent vector hd mapping
Jiacheng Chen, Yuefan Wu, Jiaqi Tan, Hang Ma, and Ya- sutaka Furukawa. Maptracker: Tracking with strided mem- ory fusion for consistent vector hd mapping. InProceedings of the European Conference on Computer Vision (ECCV),
-
[3]
Shaoyu Chen, Yunchi Zhang, Bencheng Liao, Jiafeng Xie, Tianheng Cheng, Wei Sui, Qian Zhang, Chang Huang, Wenyu Liu, and Xinggang Wang. VMA: Divide-and- conquer vectorized map annotation system for large-scale driving scene.arXiv preprint arXiv:2304.09807, 2023. 1, 3
-
[4]
Mask2map: Vectorized hd map construction using bird’s eye view segmentation masks
Sehwan Choi, Jungho Kim, Hongjae Shin, and Jun Won Choi. Mask2map: Vectorized hd map construction using bird’s eye view segmentation masks. InProceedings of the European Conference on Computer Vision (ECCV), 2024. 2, 3, 7
2024
-
[5]
Pivot- net: Vectorized pivot learning for end-to-end hd map con- struction
Wenjie Ding, Limeng Qiao, Xi Qiu, and Chi Zhang. Pivot- net: Vectorized pivot learning for end-to-end hd map con- struction. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023. 1, 2, 3, 7
2023
-
[6]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2016. 1
2016
-
[7]
Hdmapnet: An online hd map construction and evaluation framework
Qi Li, Yue Wang, Yilun Wang, and Hang Zhao. Hdmapnet: An online hd map construction and evaluation framework. InProceedings of the International Conference on Robotics and Automation (ICRA), 2022. 3, 6
2022
-
[8]
Maptr: Structured modeling and learning for online vectorized hd map construction
Bencheng Liao, Shaoyu Chen, Xinggang Wang, Tianheng Cheng, Qian Zhang, Wenyu Liu, and Chang Huang. Maptr: Structured modeling and learning for online vectorized hd map construction. InProceedings of the International Con- ference on Learning Representations (ICLR), 2023. 1, 3, 7
2023
-
[9]
Maptrv2: An end-to-end framework for online vectorized hd map construction.International Journal of Computer Vision (IJCV), pages 1352–1374, 2024
Bencheng Liao, Shaoyu Chen, Yunchi Zhang, Bo Jiang, Qian Zhang, Wenyu Liu, Chang Huang, and Xinggang Wang. Maptrv2: An end-to-end framework for online vectorized hd map construction.International Journal of Computer Vision (IJCV), pages 1352–1374, 2024. 1, 2, 3, 6, 7
2024
-
[10]
Mgmap: Mask-guided learning for online vectorized hd map construction
Xiaolu Liu, Song Wang, Wentong Li, Ruizi Yang, Junbo Chen, and Jianke Zhu. Mgmap: Mask-guided learning for online vectorized hd map construction. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024. 7
2024
-
[11]
Vectormapnet: End-to-end vectorized hd map learning
Yicheng Liu, Tianyuan Yuan, Yue Wang, Yilun Wang, and Hang Zhao. Vectormapnet: End-to-end vectorized hd map learning. InProceedings of the International Conference on Machine Learning (ICML), 2023. 2, 3, 7
2023
-
[12]
Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unproject- ing to 3d
Jonah Philion and Sanja Fidler. Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unproject- ing to 3d. InProceedings of the European Conference on Computer Vision (ECCV), 2020. 5
2020
-
[13]
End- to-end vectorized hd-map construction with piecewise bezier curve
Limeng Qiao, Wenjie Ding, Xi Qiu, and Chi Zhang. End- to-end vectorized hd-map construction with piecewise bezier curve. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR), 2023. 7
2023
-
[14]
Lego-loam: Lightweight and ground-optimized lidar odometry and mapping on vari- able terrain
Tixiao Shan and Brendan Englot. Lego-loam: Lightweight and ground-optimized lidar odometry and mapping on vari- able terrain. InProceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2018. 3
2018
-
[15]
Lio-sam: Tightly-coupled lidar inertial odometry via smoothing and mapping
Tixiao Shan, Brendan Englot, Drew Meyers, Wei Wang, Carlo Ratti, and Daniela Rus. Lio-sam: Tightly-coupled lidar inertial odometry via smoothing and mapping. InProceed- ings of the IEEE/RSJ international conference on intelligent robots and systems (IROS), 2020. 3
2020
-
[16]
Internim- age: Exploring large-scale vision foundation models with deformable convolutions
Wenhai Wang, Jifeng Dai, Zhe Chen, Zhenhang Huang, Zhiqi Li, Xizhou Zhu, Xiaowei Hu, Tong Lu, Lewei Lu, Hongsheng Li, Xiaogang Wang, and Yu Qiao. Internim- age: Exploring large-scale vision foundation models with deformable convolutions. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023. 1
2023
-
[17]
Lanediffusion: Im- proving centerline graph learning via prior injected bev fea- ture generation
Zijie Wang, Weiming Zhang, Wei Zhang, Xiao Tan, Hongx- ing Liu, Yaowei Wang, and Guanbin Li. Lanediffusion: Im- proving centerline graph learning via prior injected bev fea- ture generation. InProceedings of the IEEE/CVF Interna- tional Conference on Computer Vision (ICCV), 2025. 3
2025
-
[18]
Argoverse 2: Next generation datasets for self-driving perception and fore- casting
Benjamin Wilson, William Qi, Tanmay Agarwal, John Lam- bert, Jagjeet Singh, Siddhesh Khandelwal, Bowen Pan, Rat- nesh Kumar, Andrew Hartnett, Jhony Kaesemodel Pontes, Deva Ramanan, Peter Carr, and James Hays. Argoverse 2: Next generation datasets for self-driving perception and fore- casting. InProceedings of the Conference on Neural Infor- mation Process...
2023
-
[19]
Interactionmap: Improving online vectorized hdmap construction with in- teraction
Kuang Wu, Chuan Yang, and Zhanbin Li. Interactionmap: Improving online vectorized hdmap construction with in- teraction. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025. 7
2025
-
[20]
DuMapNet: An end-to-end vectorization system for city-scale lane-level map generation
Deguo Xia, Weiming Zhang, Xiyan Liu, Wei Zhang, Chent- ing Gong, Jizhou Huang, Mengmeng Yang, and Diange Yang. DuMapNet: An end-to-end vectorization system for city-scale lane-level map generation. InProceedings of the ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD), 2024. 1, 3
2024
-
[21]
Ldmapnet-u: An end-to-end system for city- scale lane-level map updating
Deguo Xia, Weiming Zhang, Xiyan Liu, Wei Zhang, Chent- ing Gong, Xiao Tan, Jizhou Huang, Mengmeng Yang, and Diange Yang. Ldmapnet-u: An end-to-end system for city- scale lane-level map updating. InProceedings of the ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD), 2025. 3
2025
-
[22]
Mv-map: Off- board hd-map generation with multi-view consistency
Ziyang Xie, Ziqi Pang, and Yu-Xiong Wang. Mv-map: Off- board hd-map generation with multi-view consistency. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023. 2, 3, 7
2023
-
[23]
Fusion4dal: Offline multi-modal 3d object detection for 4d auto-labeling.International Journal of Computer Vision, 133 (7):3951–3969, 2025
Zhiyuan Yang, Xuekuan Wang, Wei Zhang, Xiao Tan, Jincheng Lu, Jingdong Wang, Errui Ding, and Cairong Zhao. Fusion4dal: Offline multi-modal 3d object detection for 4d auto-labeling.International Journal of Computer Vision, 133 (7):3951–3969, 2025. 1
2025
-
[24]
Streammapnet: Streaming mapping network for vectorized online hd-map construction
Tianyuan Yuan, Yicheng Liu, Yue Wang, Yilun Wang, and Hang Zhao. Streammapnet: Streaming mapping network for vectorized online hd-map construction. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2024. 2, 3, 7
2024
-
[25]
Mapexpert: Online hd map construction with simple and efficient sparse map element expert
Dapeng Zhang, Dayu Chen, Peng Zhi, Yinda Chen, Zhen- long Yuan, Chenyang Li, Sunjing, Rui Zhou, and Qingguo Zhou. Mapexpert: Online hd map construction with simple and efficient sparse map element expert. InProceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2025. 7
2025
-
[26]
Online map vec- torization for autonomous driving: A rasterization perspec- tive
Gongjie Zhang, Jiahao Lin, Shuang Wu, Zhipeng Luo, Yang Xue, Shijian Lu, Zuoguan Wang, et al. Online map vec- torization for autonomous driving: A rasterization perspec- tive. InProceedings of the Conference on Neural Informa- tion Processing Systems (NeurIPS), 2024. 1, 7
2024
-
[27]
Enhancing vectorized map perception with historical rasterized maps
Xiaoyu Zhang, Guangwei Liu, Zihao Liu, Ningyi Xu, Yun- hui Liu, and Ji Zhao. Enhancing vectorized map perception with historical rasterized maps. InProceedings of the Euro- pean Conference on Computer Vision (ECCV), 2024. 2, 3, 7
2024
-
[28]
Online vectorized hd map construction using geometry
Zhixin Zhang, Yiyuan Zhang, Xiaohan Ding, Fusheng Jin, and Xiangyu Yue. Online vectorized hd map construction using geometry. InProceedings of the European Conference on Computer Vision (ECCV), 2024. 1, 3
2024
-
[29]
Himap: Hybrid represen- tation learning for end-to-end vectorized hd map construc- tion
Yi Zhou, Hui Zhang, Jiaqian Yu, Yifan Yang, Sangil Jung, Seung-In Park, and ByungIn Yoo. Himap: Hybrid represen- tation learning for end-to-end vectorized hd map construc- tion. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR), 2024. 7
2024
-
[30]
Ic-mapper: Instance-centric spatio-temporal modeling for online vectorized map construction
Jiangtong Zhu, Zhao Yang, Yinan Shi, Jianwu Fang, and Jianru Xue. Ic-mapper: Instance-centric spatio-temporal modeling for online vectorized map construction. InPro- ceedings of the ACM International Conference on Multime- dia (ACMMM), 2024. 2, 3
2024
-
[31]
Deformable detr: Deformable transformers for end-to-end object detection
Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, and Jifeng Dai. Deformable detr: Deformable transformers for end-to-end object detection. InProceedings of the In- ternational Conference on Learning Representations (ICLR),
-
[32]
Xi Zhu, Xiya Cao, Zhiwei Dong, Caifa Zhou, Qiangbo Liu, Wei Li, and Yongliang Wang. Nemo: Neural map growing system for spatiotemporal fusion in bird’s-eye-view and bdd- map benchmark.arXiv preprint arXiv:2306.04540, 2023. 1
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.