Recognition: unknown
MAGRPO: Accelerated MARL Training for Fluid Antenna-Assisted Wireless Network Optimization
Pith reviewed 2026-05-10 06:05 UTC · model grok-4.3
The pith
MAGRPO trains multi-agent reinforcement learning for fluid antenna wireless networks 30-40% faster than MAPPO while matching its sum-rate performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that the multi-agent group relative policy optimization (MAGRPO) algorithm, obtained by replacing the critic network with group relative advantage estimation, solves the decentralized POMDP formulation of fluid-antenna network optimization at nearly half the critic cost of MAPPO, attaining equivalent test-time sum rates with 30-40 percent less training time.
What carries the argument
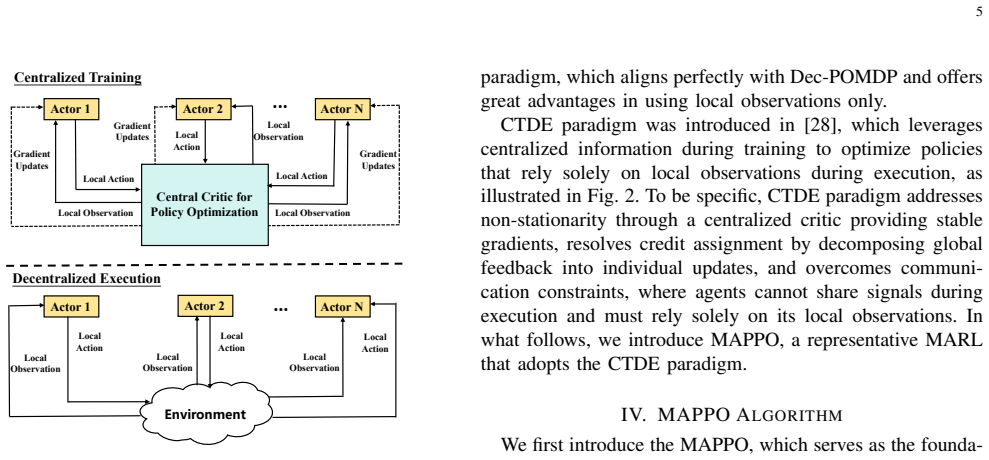
Group relative advantage estimation, which replaces the critic network in the MAPPO framework under the CTDE paradigm and thereby reduces computational complexity by nearly half when parameters are shared across agents.
If this is right
- Fluid-antenna-assisted networks achieve multiple-fold sum-rate enhancement compared with fixed-antenna baselines.
- MAGRPO delivers sum rates statistically indistinguishable from MAPPO while cutting training time by 30 to 40 percent.
- The variance of the cumulative reward remains bounded by a quantity linear in the number of base stations, users, and fluid antennas.
- Base stations can execute learned policies independently after centralized training without further coordination.
Where Pith is reading between the lines
- The halved critic size may allow training on larger numbers of base stations or users before memory limits are reached.
- The same group-relative substitution could be inserted into other multi-agent wireless problems that already use parameter sharing.
- The derived variance bound supplies a concrete scaling law that could guide hyper-parameter schedules when network size increases.
Load-bearing premise
The non-convex optimization of fluid antenna positions, beamforming, and power allocation can be effectively cast as a decentralized POMDP whose solution via group relative advantage estimation preserves performance while halving critic complexity.
What would settle it
A direct head-to-head run of MAGRPO and MAPPO on the same fluid-antenna network scenario that shows either a training-time reduction below 20 percent or a test sum-rate gap larger than 5 percent would falsify the performance-preservation claim.
Figures








read the original abstract
Fluid antenna system (FAS) becomes a promising paradigm for next-generation wireless networks, which enables position-flexible antenna elements that can dynamically adjust to more favorable channel conditions. However, the optimization of fluid antenna (FA) positions, beamforming, and power allocation in FA-assisted wireless networks is challenging, due to the non-convexity and the lack of base station (BS) coordination. In this paper, we first formulate this challenging optimization problem as a decentralized partially observable Markov decision process, and then propose a multi-agent group relative policy optimization (MAGRPO) algorithm under the centralized training decentralized execution (CTDE) paradigm. Compared with multi-agent proximal policy optimization (MAPPO), MAGRPO replaces the critic network with group relative advantage estimation. This design reduces computational complexity by nearly half under parameter sharing. Furthermore, we derive a variance upper bound of the cumulative reward, which scales with network parameters, e.g., the number of BSs, users, and FAs. Simulation results show that compared with wireless networks with fixed antenna positions, FA-assisted wireless networks achieve multiple-fold sum-rate enhancement. Moreover, the proposed MAGRPO attains sum-rates comparable to those of MAPPO in testing, while reducing training time by $30\% \sim 40\%$.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript formulates the joint optimization of fluid antenna positions, beamforming, and power allocation as a decentralized POMDP and proposes MAGRPO under CTDE, which replaces the critic network with group relative advantage estimation to reduce critic complexity by nearly half under parameter sharing. It derives a variance upper bound on the cumulative reward that scales with network parameters (number of BSs, users, FAs). Simulations claim that FA-assisted networks yield multiple-fold sum-rate gains over fixed-antenna baselines, while MAGRPO achieves sum-rates comparable to MAPPO with 30-40% lower training time.
Significance. If the group relative advantage estimator produces policy gradients sufficiently close to MAPPO's, the method could accelerate MARL training for non-convex wireless resource allocation problems while preserving performance. The variance bound provides a useful scalability analysis, and the empirical FA gains supply concrete motivation for position-flexible antennas. These elements would strengthen the case for reduced-complexity CTDE methods in communications.
major comments (2)
- [§III and §IV] §III (MAGRPO algorithm) and §IV (variance bound derivation): the group relative advantage estimation is introduced to replace the critic while halving complexity, yet no derivation or analysis establishes that the estimator is unbiased (i.e., its expectation equals the true advantage function). The provided variance upper bound addresses only variance and does not rule out bias; if biased, the learned policies optimize a different objective, undermining the claim that comparable sum-rates are a general property rather than scenario-specific.
- [§V] Simulation section (likely §V, Figs. 3-5): the central performance claim (sum-rates comparable to MAPPO with 30-40% training-time reduction) rests on empirical results, but the manuscript provides no error bars, number of independent seeds, or statistical significance tests. This weakens verification of whether the speedup and comparability hold beyond the reported runs, especially given the unproven unbiasedness of the estimator.
minor comments (3)
- [Abstract] Abstract: the phrase 'multiple-fold sum-rate enhancement' is imprecise; specific numerical gains (e.g., 2x or 3x) from the simulations should be stated.
- [§II] Notation and POMDP formulation: a compact table listing states, actions, observations, and reward components would aid readability.
- [§V] Figures showing training curves: include multiple-run statistics or shaded confidence regions to support the reported time reductions.
Simulated Author's Rebuttal
We thank the referee for the constructive and insightful comments, which have helped us identify areas for improvement in the manuscript. We address each major comment point by point below, providing our responses and indicating the revisions we will incorporate.
read point-by-point responses
-
Referee: [§III and §IV] §III (MAGRPO algorithm) and §IV (variance bound derivation): the group relative advantage estimation is introduced to replace the critic while halving complexity, yet no derivation or analysis establishes that the estimator is unbiased (i.e., its expectation equals the true advantage function). The provided variance upper bound addresses only variance and does not rule out bias; if biased, the learned policies optimize a different objective, undermining the claim that comparable sum-rates are a general property rather than scenario-specific.
Authors: We appreciate the referee's observation regarding the potential bias in the group relative advantage estimator. While the original submission emphasized the complexity reduction and variance properties, we recognize the need for a formal unbiasedness analysis. In the revised version, we will include a derivation in §III demonstrating that the group relative advantage estimation is an unbiased estimator of the advantage function under the parameter-sharing and group structure assumptions. This derivation will show that the expectation of the estimator equals the true advantage, ensuring that the policy optimization targets the correct objective. Consequently, the comparable sum-rate performance is expected to hold generally, not just in specific scenarios. We will also reference this in the discussion of the variance bound in §IV. revision: yes
-
Referee: [§V] Simulation section (likely §V, Figs. 3-5): the central performance claim (sum-rates comparable to MAPPO with 30-40% training-time reduction) rests on empirical results, but the manuscript provides no error bars, number of independent seeds, or statistical significance tests. This weakens verification of whether the speedup and comparability hold beyond the reported runs, especially given the unproven unbiasedness of the estimator.
Authors: We agree that additional statistical details are necessary to strengthen the empirical validation. In the revised manuscript, we will augment §V with the number of independent random seeds used (10 seeds for the reported results), include error bars in Figs. 3-5 indicating the mean and standard deviation across these runs, and add statistical significance tests (e.g., paired t-tests) to verify that the sum-rate differences between MAGRPO and MAPPO are not statistically significant. This will confirm the reliability of the 30-40% training time reduction while maintaining comparable performance. We believe these additions will address the concern and provide stronger evidence for the claims. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper formulates the FA position/beamforming/power problem as a decentralized POMDP, introduces MAGRPO by replacing the critic with group-relative advantage estimation (reducing complexity under parameter sharing), derives a variance upper bound on cumulative reward that scales explicitly with observable parameters (number of BSs/users/FAs), and validates via simulation that sum-rates remain comparable to MAPPO while training time drops 30-40%. No equation reduces a claimed prediction or result to a fitted input by construction; the variance bound is an independent derivation rather than a renaming or self-referential fit; no load-bearing self-citation chain or uniqueness theorem is invoked to force the central claim. The performance equivalence is presented as empirical, not mathematically forced.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The joint optimization of FA positions, beamforming, and power allocation can be formulated as a decentralized POMDP.
Reference graph
Works this paper leans on
-
[1]
A speculative study on 6G,
F. Tariq, M. R. A. Khandaker, K.-K. Wong, et. al., “A speculative study on 6G,”IEEE Wireless Commun., vol. 27, no. 4, pp. 118–125, 2020
2020
-
[2]
Integrated sensing and communi- cation with massive MIMO: A unified tensor approach for channel and target parameter estimation,
R. Zhang, L. Cheng, S. Wang, et. al., “Integrated sensing and communi- cation with massive MIMO: A unified tensor approach for channel and target parameter estimation,”IEEE Trans. Wireless Commun., vol. 23, no. 8, pp. 8571–8587, 2024
2024
-
[3]
Orthogonal projection-based channel esti- mation for multi-panel millimeter wave MIMO,
W. Wang and W. Zhang, “Orthogonal projection-based channel esti- mation for multi-panel millimeter wave MIMO,”IEEE Trans. Wireless Commun., vol. 68, no. 4, pp. 2173–2187, 2020
2020
-
[4]
Fluid antenna systems,
K.-K. Wong, A. Shojaeifard, et. al., “Fluid antenna systems,”IEEE Trans. Wireless Commun., vol. 20, no. 3, pp. 1950–1962, 2021
1950
-
[5]
Fluid antenna multiple access,
K.-K. Wong and K.-F. Tong, “Fluid antenna multiple access,”IEEE Trans. Wireless Commun., vol. 21, no. 7, pp. 4801–4815, 2022
2022
-
[6]
A tutorial on fluid antenna system for 6G networks: Encompassing communication theory, opti- mization methods and hardware designs,
W. K. New, K.-K. Wong, H. Xu, et. al., “A tutorial on fluid antenna system for 6G networks: Encompassing communication theory, opti- mization methods and hardware designs,”IEEE Commun. Surveys & Tutorials, vol. 27, no. 4, pp. 2325–2377, 2025
2025
-
[7]
Fluid antennas: Reshaping intrinsic properties for flexible radiation characteristics in intelligent wireless networks,
W.-J. Lu, C.-X. He, Y . Zhu, et. al., “Fluid antennas: Reshaping intrinsic properties for flexible radiation characteristics in intelligent wireless networks,”IEEE Commun. Mag., vol. 63, no. 5, pp. 40-45, May 2025
2025
-
[8]
A contemporary survey on fluid antenna systems: Fundamentals and networking perspectives,
H. Hong, K. K. Wong, H. Xu, et. al., “A contemporary survey on fluid antenna systems: Fundamentals and networking perspectives,”IEEE Trans. Netw. Sci. Eng., vol. 13, pp. 2305-2328, 2026
2026
-
[9]
Fluid antenna systems: Redefining recon- figurable wireless communications,
W. K. New et al., “Fluid antenna systems: Redefining reconfigurable wireless communications,”IEEE J. Sel. Areas Commun., vol. 44, pp. 1013-1044, 2026, doi: 10.1109/JSAC.2025.3632097
-
[10]
Fluid antenna systems enabling 6G: Principles, applica- tions, and research directions,
T. Wu et al., “Fluid antenna systems enabling 6G: Principles, ap- plications, and research directions,”IEEE Wireless Commun., doi: 10.1109/MWC.2025.3629597
-
[11]
Transmit and receive antenna port selection for channel capacity maximization in fluid-MIMO systems,
C. N. Efrem and I. Krikidis, “Transmit and receive antenna port selection for channel capacity maximization in fluid-MIMO systems,” IEEE Wireless Commun. Lett., vol. 13, no. 11, pp. 3202–3206, Nov. 2024
2024
-
[12]
BER performance optimization for fluid antenna-aided wireless communications,
S. Yang, Y . Xiao, Y . L. Guan, et. al., “BER performance optimization for fluid antenna-aided wireless communications,”IEEE J. Sel. Areas Commun., vol. 44, pp. 1177–1192, 2026
2026
-
[13]
Capacity maximization of uplink with fluid antenna system at both ends,
B. Tang, H. Xu, K. -K. Wong, et. al., “Capacity maximization of uplink with fluid antenna system at both ends,”IEEE Trans. Wireless Commun., vol. 24, no. 12, pp. 10578–10593, Dec. 2025
2025
-
[14]
Joint beamforming and antenna position optimization for fluid antenna-assisted MU-MIMO networks,
T. Liao, W. Guo, H. He, et. al., “Joint beamforming and antenna position optimization for fluid antenna-assisted MU-MIMO networks,”IEEE J. Sel. Areas Commun., vol. 44, pp. 1209–1226, 2026
2026
-
[15]
Analysis and optimization for low-latency communications in slow fluid antenna multiple access systems,
Y . Chen, B. Xu, S. Li, et. al., “Analysis and optimization for low-latency communications in slow fluid antenna multiple access systems,”IEEE J. Sel. Areas Commun., vol. 44, no. 4, pp. 1290–1306, 2026
2026
-
[16]
An efficient sum-rate maximiza- tion algorithm for fluid antenna-assisted ISAC system,
Q. Zhang, M. Shao, T. Zhang, et. al., “An efficient sum-rate maximiza- tion algorithm for fluid antenna-assisted ISAC system,”IEEE Commun. Lett., vol. 29, no. 1, pp. 200–204, 2025
2025
-
[17]
Proximal policy optimiza- tion for latency minimization in FL-assisted fluid antenna systems with MC-NOMA,
M. C. Ho, T. D. T. Tam, T. S. Do, and S. Cho, “Proximal policy optimiza- tion for latency minimization in FL-assisted fluid antenna systems with MC-NOMA,” inProc. 2025 30th Asia-Pacific Conf. Commun. (APCC), pp. 1–6, 2025
2025
-
[18]
Indoor fluid antenna systems enabled by layout-specific modeling and group relative policy optimization,
T. Zhang, Q. Li, S. Wang, et. al., “Indoor fluid antenna systems enabled by layout-specific modeling and group relative policy optimization,” IEEE Trans. Wireless Commun., vol. 25, pp. 9312–9330, Jan. 2026
2026
-
[19]
Opportunistic fluid antenna multiple access via team-inspired reinforcement learning,
N. Waqar, K.-K. Wong, C.-B. Chae, et. al., “Opportunistic fluid antenna multiple access via team-inspired reinforcement learning,”IEEE Trans. Wireless Commun., vol. 23, pp. 12068–12083, Sept. 2024
2024
-
[20]
Learning-based joint beam- forming and antenna movement design for movable antenna systems,
C. Weng, Y . Chen, L. Zhu, and Y . Wang, “Learning-based joint beam- forming and antenna movement design for movable antenna systems,” IEEE Wireless Commun. Lett., vol. 13, pp. 2120–2124, Aug. 2024
2024
-
[21]
Fluid antenna system liberating multiuser MIMO for ISAC via deep reinforcement learning,
C. Wang, G. Li, H. Zhang, et. al., “Fluid antenna system liberating multiuser MIMO for ISAC via deep reinforcement learning,”IEEE Trans. Wireless Commun., vol. 23, pp. 10879–10894, Sept. 2024
2024
-
[22]
Movable-antenna enabled cell-free networks,
H. Wei, W. Wang, W. Ni, et. al., “Movable-antenna enabled cell-free networks,”IEEE Trans. Veh. Technol., vol. 74, no. 10, pp. 16533–16537, 2025
2025
-
[23]
Joint beamforming, user association, and antenna position optimization in movable antenna-assisted cell-free massive MIMO,
J. Zhu, L. Feng, X. Wang, et. al., “Joint beamforming, user association, and antenna position optimization in movable antenna-assisted cell-free massive MIMO,”IEEE Trans. Netw. Sci. Eng., vol. 13, pp. 4153–4169, 2026
2026
-
[24]
Fluid antenna multiple access with simultaneous non-unique decoding in strong interference channel,
F. R. Ghadi, et al., “Fluid antenna multiple access with simultaneous non-unique decoding in strong interference channel,”IEEE Trans. Wire- less Commun., vol. 24, no. 12, pp. 10183–10195, Dec. 2025
2025
-
[25]
SWIPT optimization design for multi- RIS-aided cell-free IoT networks with fluid antenna,
X. Li, Q. Cui, B. Zhao, et al., “SWIPT optimization design for multi- RIS-aided cell-free IoT networks with fluid antenna,”IEEE Trans. Wireless Commun., vol. 25, pp. 10484–10497, 2026
2026
-
[26]
Deep reinforcement learning for movable antenna-assisted cell-free networks,
Q. Li, W. Wang, Y . Li, F. Yu, C. Zhang, and Y . Huang, “Deep reinforcement learning for movable antenna-assisted cell-free networks,” IEEE Wireless Commun. Lett., vol. 14, pp. 2783–2787, Sept. 2025
2025
-
[27]
CD-MAPPO: Centralized- decentralized multi-agent proximal policy optimization in multi-cell networks,
C. Su, R. Wu, Y . Zhu, and Q. Hu, “CD-MAPPO: Centralized- decentralized multi-agent proximal policy optimization in multi-cell networks,” inProc. IEEE/CIC Int. Conf. Commun. China (ICCC) Workshops, pp. 1–6, 2024
2024
-
[28]
Multi-agent actor-critic for mixed cooperative-competitive environments,
R. Lowe, Y . I. Wu, A. Tamar, et. al., “Multi-agent actor-critic for mixed cooperative-competitive environments,” inProc. Advances in Neural Information Processing Systems (NeurIPS), vol. 30, 2017
2017
-
[29]
The surprising effectiveness of PPO in cooperative multi-agent games,
C. Yu, A. Velu, E. Vinitsky, et. al., “The surprising effectiveness of PPO in cooperative multi-agent games,” inProc. Advances in Neural Information Processing Systems (NeurIPS), vol. 35, pp. 24611–24624, 2022
2022
-
[30]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Z. Shao, P. Wang, Q. Zhu, et. al., “Deepseekmath: Pushing the limits of mathematical reasoning in open language models,”arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
Adam: A Method for Stochastic Optimization
D. P. Kingma and J. Ba, “ADAM: A method for stochastic optimization,” arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[32]
GRADPS: Resolving futile neurons in parameter sharing network for multi-agent reinforcement learning,
H. Qin, Z. Liu, C. Lin, et. al., “GRADPS: Resolving futile neurons in parameter sharing network for multi-agent reinforcement learning,” in Proc. International Conference on Machine Learning (ICML), 2025
2025
-
[33]
Low variance trust region optimization with independent actors and sequential updates in cooperative multi-agent reinforcement learning,
B. G. Le and V . C. Ta, “Low variance trust region optimization with independent actors and sequential updates in cooperative multi-agent reinforcement learning,”Autonomous Agents and Multi-Agent Systems, vol. 39, no. 1, p. 12, 2025
2025
-
[34]
S. M. Kay,Fundamentals of Statistical Signal Processing: Estimation Theory. Englewood Cliffs, NJ: Prentice Hall, 1993
1993
-
[35]
Multi-agent reinforcement learning for multi-cell spectrum and power allocation,
Y . Zhang and D. Guo, “Multi-agent reinforcement learning for multi-cell spectrum and power allocation,”IEEE Trans. Commun., vol. 73, no. 8, pp. 5980–5992, Aug. 2025
2025
-
[36]
An iteratively weighted MMSE approach to distributed sum-utility maximization for a MIMO interfering broadcast channel,
Q. Shi, M. Razaviyayn, Z. -Q. Luo, and C. He, “An iteratively weighted MMSE approach to distributed sum-utility maximization for a MIMO interfering broadcast channel,”IEEE Trans. Signal Process., vol. 59, no. 9, pp. 4331–4340, Sept. 2011
2011
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.