Model in Distress: Sentiment Analysis on French Synthetic Social Media
Pith reviewed 2026-05-10 04:15 UTC · model grok-4.3
The pith
Backtranslation from a small seed corpus generates 1.7 million synthetic French tweets that train 600M-parameter models to detect customer distress at 77-79% accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Synthetic data generated by backtranslation from a limited seed corpus, augmented with reasoning traces, is sufficient to train 600M-parameter reasoners that achieve 77-79% accuracy on human-annotated French social-media distress detection, matching or exceeding state-of-the-art proprietary models while preserving privacy.
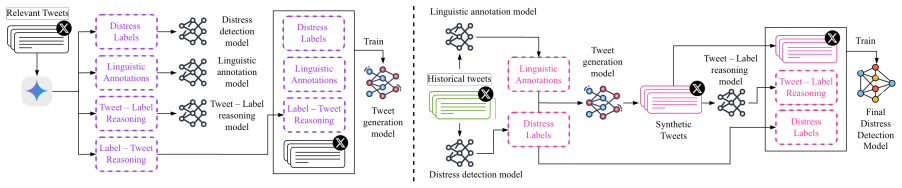
What carries the argument
The backtranslation pipeline that uses fine-tuned models to expand a small seed corpus into 1.7 million labeled synthetic tweets together with synthetic reasoning traces.
If this is right
- Annotation budgets can be redirected from labeling real posts to creating and validating small seed sets.
- Research groups can share and reproduce results without exchanging sensitive user data.
- The same pipeline can be applied to other languages and distress-related domains with minimal new annotation.
- Models gain explicit reasoning supervision that may improve interpretability of distress predictions.
Where Pith is reading between the lines
- If backtranslation quality degrades for languages farther from the pivot language, performance gains may shrink.
- Deployment tests on live social-media streams would reveal whether the synthetic distribution matches evolving real-world language.
- Adding more diverse seed examples or iterative refinement of the backtranslation models could further close any remaining gap to real data.
Load-bearing premise
Tweets produced by backtranslation from a small seed corpus are representative enough of real French social-media language about customer distress that models trained on them will generalize to actual user posts.
What would settle it
Running the trained models on a new collection of real, non-synthetic French tweets about public-transportation complaints and measuring whether accuracy remains near 77-79 percent or falls sharply.
Figures






read the original abstract
Automated analysis of customer feedback on social media is hindered by three challenges: the high cost of annotated training data, the scarcity of evaluation sets, especially in multilingual settings, and privacy concerns that prevent data sharing and reproducibility. We address these issues by developing a generalizable synthetic data generation pipeline applied to a case study on customer distress detection in French public transportation. Our approach utilizes backtranslation with fine-tuned models to generate 1.7 million synthetic tweets from a small seed corpus, complemented by synthetic reasoning traces. We train 600M-parameter reasoners with English and French reasoning that achieve 77-79% accuracy on human-annotated evaluation data, matching or exceeding SOTA proprietary LLMs and specialized encoders. Beyond reducing annotation costs, our pipeline preserves privacy by eliminating the exposure of sensitive user data. Our methodology can be adopted for other use cases and languages.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a synthetic data generation pipeline based on backtranslation to produce 1.7 million synthetic French tweets from a small seed corpus, along with synthetic reasoning traces. Using this data, the authors train 600M-parameter reasoners supporting English and French reasoning, reporting accuracies of 77-79% on human-annotated evaluation data for customer distress detection in French public transportation social media. This performance is claimed to match or exceed state-of-the-art proprietary LLMs and specialized encoders, while mitigating annotation costs and privacy issues.
Significance. Should the synthetic data be demonstrated to faithfully represent the distribution of real social media posts, the work would provide an important contribution to low-resource multilingual sentiment analysis by enabling scalable, privacy-preserving dataset creation. The reported results suggest that such pipelines can yield models competitive with much larger or proprietary systems, with potential applications in other languages and domains facing similar data scarcity challenges.
major comments (2)
- Abstract: The abstract claims that the trained models reach 77-79% accuracy on human-annotated data and match SOTA systems, yet provides no information on how synthetic-data quality was validated, whether the evaluation set was held out properly, or what error patterns remain; this leaves the central performance claim difficult to assess.
- Abstract: The approach relies on the assumption that backtranslation from a small seed corpus produces synthetic tweets representative of real French social-media language (including abbreviations, code-switching, and complaint-specific phrasing). No quantitative validation of distributional match (e.g., n-gram overlap, embedding divergence, or stratified error analysis) is described, which is load-bearing for the generalization claim to actual user posts.
minor comments (1)
- Abstract: The term 'reasoners' is used without definition or clarification of how these models incorporate reasoning traces differently from standard fine-tuned classifiers.
Simulated Author's Rebuttal
We thank the referee for their insightful comments, which highlight important aspects of our synthetic data pipeline and evaluation. We provide point-by-point responses below and indicate where revisions will be made to address the concerns.
read point-by-point responses
-
Referee: Abstract: The abstract claims that the trained models reach 77-79% accuracy on human-annotated data and match SOTA systems, yet provides no information on how synthetic-data quality was validated, whether the evaluation set was held out properly, or what error patterns remain; this leaves the central performance claim difficult to assess.
Authors: We agree that the abstract, due to its brevity, does not detail these aspects. In the full manuscript, the evaluation set is described as a held-out human-annotated dataset separate from the seed corpus used for synthetic generation. Synthetic data quality is validated through the models' performance on this real data. To make this clearer, we will revise the abstract to include a brief mention of the held-out evaluation and add a dedicated subsection in the methods or results on validation of synthetic data and error analysis. revision: yes
-
Referee: Abstract: The approach relies on the assumption that backtranslation from a small seed corpus produces synthetic tweets representative of real French social-media language (including abbreviations, code-switching, and complaint-specific phrasing). No quantitative validation of distributional match (e.g., n-gram overlap, embedding divergence, or stratified error analysis) is described, which is load-bearing for the generalization claim to actual user posts.
Authors: The referee correctly identifies that our manuscript does not provide quantitative distributional comparisons between the synthetic tweets and real social media posts. While the downstream task performance on human-annotated data provides evidence of utility, we acknowledge the value of direct validation. In the revised manuscript, we will include quantitative analyses such as n-gram overlap statistics, cosine similarities in embedding space between synthetic and real tweet distributions, and a stratified error analysis on the evaluation set to better demonstrate the representativeness of the synthetic data. revision: yes
Circularity Check
No circularity detected in derivation chain
full rationale
The paper's core pipeline generates 1.7M synthetic tweets via backtranslation from a small seed corpus, augments them with synthetic reasoning traces, and trains 600M-parameter models on this data. Performance is then measured as 77-79% accuracy on a separate human-annotated evaluation set that is not derived from the synthetic data or its generation process. No equations, fitted parameters, or self-citations reduce the reported accuracy to a quantity defined by the inputs; the result is an empirical measurement against an external benchmark. None of the enumerated circularity patterns (self-definitional, fitted-input-as-prediction, load-bearing self-citation, etc.) appear in the abstract or described methodology.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Backtranslation with fine-tuned models yields synthetic French tweets whose distribution is close enough to real social-media text for effective model training
Reference graph
Works this paper leans on
-
[1]
Evaluating sentiment analysis models: A comparative analysis of vaccination tweets during the COVID-19 phase leveraging DistilBERT for en- hanced insights.MethodsX, 14:103407. Kanwal Ahmed, Muhammad Imran Nadeem, Guanghui Wang, Fang Zuo, and Zhijie Han. 2026. LLM- infused multi-module transformer for emotion-aware sentiment analysis in few-shot scenarios....
-
[2]
InProceedings of The 12th International Workshop on Semantic Evaluation, pages 24–33
Semeval 2018 task 2: Multilingual emoji pre- diction. InProceedings of The 12th International Workshop on Semantic Evaluation, pages 24–33. Valerio Basile, Cristina Bosco, Elisabetta Fersini, Debora Nozza, Viviana Patti, Francisco Manuel Rangel Pardo, Paolo Rosso, and Manuela Sanguinetti
work page 2018
-
[3]
SemEval-2019 Task 5: Multilingual Detection of Hate Speech Against Immigrants and Women in Twitter. InProceedings of the 13th International Workshop on Semantic Evaluation, pages 54–63, Min- neapolis, Minnesota, USA. Association for Compu- tational Linguistics. Jo Causon. 2023. Social media as a review channel. Accessed: 2025-12-02. Gheorghe Comanici, Eri...
work page 2019
-
[4]
Gemini 2.5: Pushing the Frontier with Ad- vanced Reasoning, Multimodality, Long Context, and Next Generation Agentic Capabilities.Preprint, arXiv:2507.06261. Nastaran Dadashi, David Golightly, and Sarah Sharples
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Modelling decision-making within rail main- tenance control rooms.Cogn. Technol. Work, 23(2):255–271. Rohan Doshi. 2025. Gemini 3 Pro: the frontier of vision AI. Accessed: 2025-12-30. Sherif Elmitwalli, John Mehegan, Allen Gallagher, and Raouf Alebshehy. 2024. Enhancing sentiment and intent analysis in public health via fine-tuned large language models on...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Sentiment Analysis of Tweets Before the 2024 Elections in Indonesia Using BERT Language Mod- els.Jurnal Ilmiah Teknik Elektro Komputer dan In- formatika (JITEKI), 9(3):746–757. Md. Nesarul Hoque, Umme Salma, Md. Jamal Uddin, Md. Martuza Ahamad, and Sakifa Aktar. 2024. Ex- ploring transformer models in the sentiment analysis task for the under-resource Ben...
work page internal anchor Pith review arXiv 2024
-
[7]
AfriSenti: A Twitter Sentiment Analysis Benchmark for African Languages. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 13968–13981, Singapore. Association for Computational Linguis- tics. Qwen Team. 2026. Qwen3.5: Towards native multi- modal agents. https://qwen.ai/blog?id=qwen3
work page 2023
-
[8]
Sara Rosenthal, Noura Farra, and Preslav Nakov
Accessed: 2026-04-17. Sara Rosenthal, Noura Farra, and Preslav Nakov. 2017. SemEval-2017 task 4: Sentiment analysis in Twitter. InProceedings of the 11th international workshop on semantic evaluation (SemEval-2017), pages 502– 518. Salim Sazzed. 2020. Cross-lingual sentiment classifica- tion in low-resource Bengali language. InProceed- ings of the Sixth W...
work page 2026
-
[9]
Social media: Where customers air their troubles—How to respond to them?Journal of Innovation & Knowledge, 6(4):257–267. SocialMediaToday. 2014. The Impact of Online Re- views and Your Business: Positive Only vs. Respond- ing to Negative Reviews. Accessed: 2025-12-02. Sidney Suen, Ranjan Satapathy, Kenneth Kwok, and Erik Cambria. 2025. Multi-Layered Promp...
work page 2014
-
[10]
M2SA: Multimodal and Multilingual Model for Sentiment Analysis of Tweets. InProceedings of the 2024 Joint International Conference on Compu- tational Linguistics, Language Resources and Evalu- ation (LREC-COLING 2024), pages 10833–10845, Torino, Italia. ELRA and ICCL. Cynthia Van Hee, Els Lefever, and Véronique Hoste
work page 2024
-
[11]
Semeval-2018 task 3: Irony detection in En- glish tweets. InProceedings of The 12th Interna- tional Workshop on Semantic Evaluation, pages 39– 50. Benjamin Warner, Antoine Chaffin, Benjamin Clavié, Orion Weller, Oskar Hallström, Said Taghadouini, Alexis Gallagher, Raja Biswas, Faisal Ladhak, Tom Aarsen, Griffin Thomas Adams, Jeremy Howard, and Iacopo Poli...
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[12]
Please select ‘Yes’ for this item
SemEval-2019 Task 6: Identifying and Cat- egorizing Offensive Language in Social Media (Of- fensEval). InProceedings of the 13th International Workshop on Semantic Evaluation, pages 75–86. A Data In the first collection period between 2012 and 2023, the volume of tweets increased steadily over the years despite an invariable collection scheme, reflecting ...
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.