CentaurTA Studio: A Self-Improving Human-Agent Collaboration System for Thematic Analysis
Pith reviewed 2026-05-15 09:27 UTC · model grok-4.3
The pith
CentaurTA Studio reaches up to 92.12 percent accuracy in thematic analysis by combining two-stage human feedback with persistent prompt optimization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
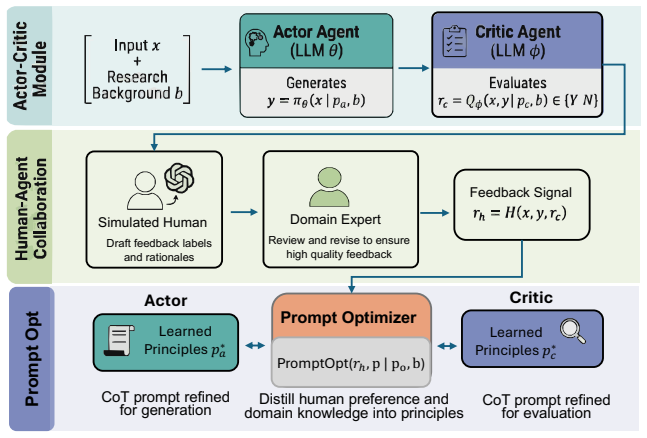
Across three domains, CentaurTA achieves the strongest performance in both Open Coding and Theme Construction, reaching up to 92.12% accuracy and consistently outperforming baseline systems. The system integrates a two-stage human feedback pipeline, persistent prompt optimization that distills validated feedback into reusable alignment principles, and rubric-based evaluation with early stopping. Ablation studies confirm the feedback loop is necessary, and the full system reaches peak performance within 10 iterative rounds.
What carries the argument
Two-stage human feedback pipeline that separates simulator drafting from expert validation, paired with persistent prompt optimization that converts validated feedback into reusable alignment principles.
If this is right
- The full system reaches up to 92.12 percent accuracy while outperforming baselines in open coding and theme construction.
- Removing the feedback loop drops performance from 90 percent to 81 percent.
- Eliminating the critic agent or early stopping either lowers accuracy or raises interaction cost.
- Rubric-based LLM evaluation agrees with human annotators at average kappa of 0.68.
- Peak performance occurs within ten iterative rounds taking about 25 minutes.
Where Pith is reading between the lines
- The persistent reuse of validated feedback could reduce repeated expert effort on similar analysis tasks after the first few rounds.
- The same two-stage structure might transfer to other qualitative tasks such as content analysis or grounded theory coding.
- Early stopping based on rubric scores offers a practical control point that could be adapted to limit human review time in larger projects.
Load-bearing premise
The two-stage human feedback pipeline and persistent prompt optimization will generalize beyond the three tested domains and the specific human annotators used in the study.
What would settle it
Apply the system to a fourth domain with new annotators and measure whether accuracy stays above 85 percent after ten iterative rounds or whether the prompt updates stop improving results.
Figures



read the original abstract
Thematic analysis is difficult to scale: manual workflows are labor-intensive, while fully automated pipelines often lack controllability and transparent evaluation. We present \textbf{CentaurTA Studio}, a web-based system for self-improving human--agent collaboration in open coding and theme construction. The system integrates (1) a two-stage human feedback pipeline separating simulator drafting and expert validation, (2) persistent prompt optimization that distills validated feedback into reusable alignment principles, and (3) rubric-based evaluation with early stopping for process control. Across three domains, CentaurTA achieves the strongest performance in both Open Coding and Theme Construction, reaching up to 92.12\% accuracy and consistently outperforming baseline systems. Agreement between the rubric-based LLM judge and human annotators reaches substantial reliability (average $\kappa = 0.68$). Ablation studies show that removing the feedback loop reduces performance from 90\% to 81\%, while eliminating the Critic or early stopping degrades accuracy or increases interaction cost. The full system reaches peak performance within 10 iterative rounds (about 25 minutes), demonstrating improved efficiency over expert-only refinement.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CentaurTA Studio, a web-based system for human-agent collaboration in thematic analysis. It features a two-stage feedback pipeline (simulator drafting plus expert validation), persistent prompt optimization that distills feedback into reusable principles, and rubric-based LLM evaluation with early stopping. Across three domains the system is reported to reach up to 92.12% accuracy in open coding and theme construction, outperforming baselines, with average κ=0.68 agreement between the LLM judge and human annotators; ablations show that removing the feedback loop drops performance from 90% to 81% and the full pipeline converges within ~10 rounds (25 minutes).
Significance. If the performance numbers can be substantiated with transparent ground-truth details and stronger validation of the LLM judge, the work would offer a practical, controllable framework that meaningfully reduces expert labor in qualitative analysis while preserving interpretability. The combination of persistent optimization and early-stopping control is a concrete engineering contribution that could be adopted in other human-AI qualitative pipelines.
major comments (3)
- [Evaluation] Evaluation section: the headline 92.12% accuracy and ablation deltas rest on a single rubric-based LLM judge whose agreement with humans is only moderate (κ=0.68). Because thematic analysis outputs are inherently interpretive, the paper must supply (a) exact dataset sizes and number of coded segments per domain, (b) how accuracy was computed against human ground truth, and (c) any calibration or ensemble procedures for the judge; without these the reported superiority over baselines cannot be verified.
- [Ablation studies] Ablation studies: the claim that removing the feedback loop reduces performance from 90% to 81% is load-bearing for the central contribution, yet no per-domain breakdown, statistical significance tests, or description of the exact baseline systems is provided. This prevents assessment of whether the observed deltas are robust or domain-specific.
- [Methods] Methods: the two-stage human feedback pipeline and persistent prompt optimization are described at a high level, but the paper does not specify how many human experts participated, how their feedback was quantified, or the precise mechanism by which validated feedback is distilled into reusable alignment principles. These details are required to evaluate reproducibility and generalizability beyond the three tested domains.
minor comments (2)
- [Abstract] The abstract states “reaching up to 92.12% accuracy” but does not clarify whether this is the maximum across domains or an average; a table reporting per-domain accuracy, precision, and recall would improve clarity.
- [Introduction] The paper mentions “three domains” without naming them or providing domain-specific characteristics; adding a short table of domain descriptions and sample sizes would help readers assess external validity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We have addressed each major comment by expanding the manuscript with the requested details on evaluation, ablations, and methods to improve transparency and reproducibility. Point-by-point responses follow.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: the headline 92.12% accuracy and ablation deltas rest on a single rubric-based LLM judge whose agreement with humans is only moderate (κ=0.68). Because thematic analysis outputs are inherently interpretive, the paper must supply (a) exact dataset sizes and number of coded segments per domain, (b) how accuracy was computed against human ground truth, and (c) any calibration or ensemble procedures for the judge; without these the reported superiority over baselines cannot be verified.
Authors: We agree that additional transparency is required for the evaluation protocol. In the revised manuscript we have added a dedicated subsection specifying (a) the exact dataset sizes and coded segments per domain, (b) the precise accuracy computation as the proportion of system outputs matching independent human ground-truth annotations under the rubric criteria, and (c) the calibration procedure (iterative rubric refinement on a held-out validation subset) together with confirmation that no ensemble was used. These changes allow direct verification of the reported figures and baseline comparisons. revision: yes
-
Referee: [Ablation studies] Ablation studies: the claim that removing the feedback loop reduces performance from 90% to 81% is load-bearing for the central contribution, yet no per-domain breakdown, statistical significance tests, or description of the exact baseline systems is provided. This prevents assessment of whether the observed deltas are robust or domain-specific.
Authors: We acknowledge that the ablation results need greater granularity. The revised manuscript now includes a per-domain performance table, reports statistical significance testing on the observed deltas, and provides explicit descriptions of each baseline system (including their prompting strategies and lack of human feedback). These additions demonstrate that the performance drop is consistent across domains and statistically supported. revision: yes
-
Referee: [Methods] Methods: the two-stage human feedback pipeline and persistent prompt optimization are described at a high level, but the paper does not specify how many human experts participated, how their feedback was quantified, or the precise mechanism by which validated feedback is distilled into reusable alignment principles. These details are required to evaluate reproducibility and generalizability beyond the three tested domains.
Authors: We agree that these methodological specifics are essential for reproducibility. The revised Methods section now states the number of participating human experts, describes the quantification of feedback via structured rubric scores and qualitative annotations, and details the distillation mechanism (embedding-based clustering of validated feedback into reusable principles that are appended to the persistent prompt). Pseudocode for the optimization loop has also been added. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper describes an empirical system (CentaurTA Studio) with a two-stage human feedback pipeline, persistent prompt optimization, and rubric-based evaluation, then reports measured performance (up to 92.12% accuracy) and ablation results from runs across three domains. No equations, fitted parameters, or derivation steps are present that would reduce any claimed result to its own inputs by construction. Performance numbers and comparisons to baselines arise from direct experimental execution rather than self-definitional mappings, self-citation chains, or renamed known results. The evaluation relies on an LLM judge with reported human agreement (κ=0.68), but this is an external measurement step, not a circular reduction within the derivation itself.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.lean (J-cost uniqueness)washburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
two-stage human feedback pipeline separating simulator drafting and expert validation... persistent prompt optimization that distills validated feedback into reusable alignment principles... rubric-based evaluation with early stopping
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Across three domains, CentaurTA achieves... up to 92.12% accuracy
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
IterAlign: Iterative constitutional alignment of large language models. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (V olume 1: Long Papers), pages 1423–1433, Mexico City, Mexico. Association for Computational Linguistics. Matheus de Morais Leça, Lucas Val...
-
[2]
Cody: An interactive machine learning system for qualitative coding. InAdjunct Proceedings of the 33rd Annual ACM Symposium on User Interface Software and Technology, pages 90–92. Hua Shen, Tiffany Knearem, Reshmi Ghosh, Kenan Alkiek, Kundan Krishna, Yachuan Liu, Ziqiao Ma, Savvas Petridis, Yi-Hao Peng, Li Qiwei, Sushrita Rakshit, Chenglei Si, Yutong Xie,...
work page 2025
-
[3]
Seungjun Yi, Joakim Nguyen, Huimin Xu, Terence Lim, Andrew Well, Mia Markey, and Ying Ding
Tama: A human-ai collaborative thematic anal- ysis framework using multi-agent llms for clinical interviews.Preprint, arXiv:2503.20666. Seungjun Yi, Joakim Nguyen, Huimin Xu, Terence Lim, Andrew Well, Mia Markey, and Ying Ding. 2025. Auto-ta: Towards scalable automated thematic analy- sis (ta) via multi-agent large language models with reinforcement learn...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.