Reasoning-Aware AIGC Detection via Alignment and Reinforcement
Pith reviewed 2026-05-10 03:14 UTC · model grok-4.3
The pith
REVEAL detects AI-generated text by first producing an interpretable reasoning chain before classification.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
REVEAL generates interpretable reasoning chains before classification and trains them through supervised fine-tuning followed by reinforcement learning, achieving state-of-the-art performance across multiple benchmarks while improving logical consistency and reducing hallucinations.
What carries the argument
The REVEAL framework that produces an explicit reasoning chain about text authorship prior to binary classification, trained via a two-stage process of supervised fine-tuning then reinforcement learning.
If this is right
- Detection performance reaches state-of-the-art levels on multiple existing benchmarks.
- Decisions become transparent because each classification is preceded by an explicit reasoning trace.
- Logical consistency of explanations rises while hallucinations in the reasoning drop.
- The approach handles texts from diverse domains and multiple LLM sources within the introduced dataset.
- The two-stage training produces a detector that remains usable as new LLMs appear.
Where Pith is reading between the lines
- The same reasoning-chain approach could be adapted to detect AI-generated code or images by replacing the text-specific reasoning prompts.
- Users could inspect the generated reasoning traces to understand and correct occasional false positives in real deployments.
- The method might serve as a training signal for future LLMs themselves, teaching them to avoid detectable patterns in their own outputs.
Load-bearing premise
That requiring the model to output interpretable reasoning chains and training it with supervised fine-tuning followed by reinforcement learning will raise detection accuracy and consistency without introducing new biases or overfitting to the AIGC-text-bank dataset.
What would settle it
A controlled experiment that removes the reinforcement-learning stage and measures whether accuracy on held-out benchmarks falls and whether the remaining reasoning chains show more inconsistencies or hallucinations.
Figures








read the original abstract
The rapid advancement and widespread adoption of Large Language Models (LLMs) have elevated the need for reliable AI-generated content (AIGC) detection, which remains challenging as models evolve. We introduce AIGC-text-bank, a comprehensive multi-domain dataset with diverse LLM sources and authorship scenarios, and propose REVEAL, a detection framework that generates interpretable reasoning chains before classification. Our approach uses a two-stage training strategy: supervised fine-tuning to establish reasoning capabilities, followed by reinforcement learning to improve accuracy, improve logical consistency, and reduce hallucinations. Extensive experiments show that REVEAL achieves state-of-the-art performance across multiple benchmarks, offering a robust and transparent solution for AIGC detection. The project is open-source at https://aka.ms/reveal
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces AIGC-text-bank, a multi-domain dataset spanning diverse LLM sources and authorship scenarios, and proposes REVEAL, a detection framework that first generates interpretable reasoning chains before performing binary classification. Training proceeds in two stages: supervised fine-tuning to instill reasoning capabilities, followed by reinforcement learning to boost accuracy, logical consistency, and reduce hallucinations. The central claim is that REVEAL attains state-of-the-art performance across multiple benchmarks while providing a transparent solution for AIGC detection; the project is released open-source.
Significance. If the reported performance gains and ablation results hold under rigorous scrutiny, the work could meaningfully advance AIGC detection by demonstrating that explicit reasoning chains plus RL alignment yield both higher accuracy and greater interpretability than prior black-box classifiers. The open-source release and the construction of a new multi-domain benchmark constitute concrete contributions that facilitate reproducibility and follow-on research.
major comments (2)
- [Experiments section] Experiments section (assumed §4), Table 2 or equivalent results table: the SOTA claim is not accompanied by per-benchmark numerical scores, standard deviations across runs, or statistical significance tests against the strongest baselines; without these, the central performance assertion cannot be evaluated as load-bearing evidence.
- [Method section] Method section (§3.2), reward model description: the RL stage is asserted to improve logical consistency without new biases, yet no explicit formulation of the reward components (e.g., consistency term, hallucination penalty) or ablation isolating their effect is supplied, leaving the weakest assumption untested.
minor comments (2)
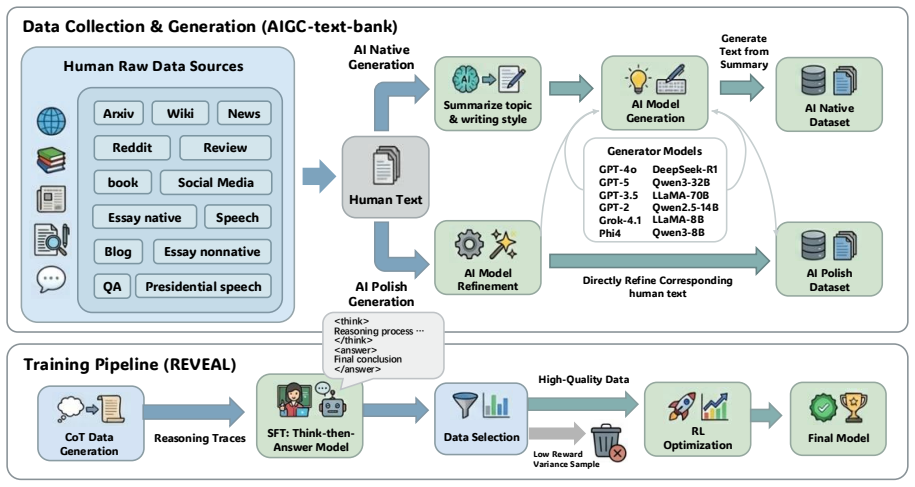
- [Figure 1] Figure 1 (framework diagram): the transition arrow from SFT to RL stage is visually ambiguous regarding whether the reasoning chain is frozen or further optimized during RL.
- [Related Work] Related Work: several recent LLM-based detection papers (post-2023) are cited only in passing; a more systematic comparison table would clarify the precise novelty of the reasoning-chain component.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and describe the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Experiments section] Experiments section (assumed §4), Table 2 or equivalent results table: the SOTA claim is not accompanied by per-benchmark numerical scores, standard deviations across runs, or statistical significance tests against the strongest baselines; without these, the central performance assertion cannot be evaluated as load-bearing evidence.
Authors: We acknowledge that the current results presentation, while showing comparative performance across benchmarks, does not report standard deviations from multiple runs or statistical significance tests. In the revised manuscript we will expand the experiments section and Table 2 to include per-benchmark mean scores with standard deviations computed over at least three independent runs, together with paired statistical tests (e.g., t-tests with p-values) against the strongest baselines. These additions will make the SOTA claims quantitatively verifiable. revision: yes
-
Referee: [Method section] Method section (§3.2), reward model description: the RL stage is asserted to improve logical consistency without new biases, yet no explicit formulation of the reward components (e.g., consistency term, hallucination penalty) or ablation isolating their effect is supplied, leaving the weakest assumption untested.
Authors: We agree that §3.2 currently describes the intended benefits of the RL stage at a high level without the explicit reward formulation or isolating ablations. In the revision we will add the precise mathematical definition of the composite reward function, explicitly stating the consistency term, hallucination penalty, and any other components. We will also include a dedicated ablation study that removes or scales each term individually and reports the resulting changes in accuracy, consistency, and bias metrics, thereby testing the claim that no new biases are introduced. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces a dataset and a two-stage empirical training pipeline (SFT for reasoning followed by RL for accuracy and consistency) whose performance claims rest entirely on benchmark experiments rather than any mathematical derivation or first-principles result. No equations, uniqueness theorems, fitted parameters renamed as predictions, or self-citation load-bearing steps appear in the provided text. The approach follows standard LLM alignment practices without reducing any claimed outcome to a self-referential definition or input by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Spotting llms with binoculars: zero-shot detection of machine-generated text. InProceedings of the 41st International Conference on Machine Learning, ICML’24. JMLR.org. Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, and 1 others. 2024. Gpt-4o system card.arXiv prepr...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Detecting fake content with relative entropy scoring.Pan, 8(27-31):4. Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Man- dar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. Roberta: A robustly optimized bert pretraining ap- proach.Preprint, arXiv:1907.11692. Eric Mitchell, Yoonho Lee, Alexander Khazatsky, Christoph...
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[3]
Qwen3 technical report.arXiv preprint arXiv:2505.09388. Junyan Ye, Baichuan Zhou, Zilong Huang, Junan Zhang, Tianyi Bai, Hengrui Kang, Jun He, Honglin Lin, Zi- hao Wang, Tong Wu, and 1 others. 2025. Loki: A comprehensive synthetic data detection benchmark using large multimodal models.ICLR. Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Analyze the text step by step
-
[5]
Identify concrete evidence that supports the given label
-
[6]
Contrast it with why the opposite label is less likely
-
[7]
Write your reasoning in natural language inside <think> tags
- [8]
-
[9]
Do not use any other tags or formatting
-
[10]
Assume you do not yet know the label
Do not explicitly mention the ground truth label in your reasoning. Assume you do not yet know the label. Always ground your analysis in specific stylistic, structural, or semantic features of the text. Avoid generic summaries or descriptions. Text:{input_text} Ground Truth Label:{label} <think> Table 12: The Hindsight Prompt used for generating reasoning...
-
[11]
Answer–Reasoning Alignment: Does the reasoning logically support the final answer? This should be binary (1.0 or 0.0) based on whether the reasoning is consistent with the final classification
-
[12]
Groundedness: Is the reasoning grounded in the input text and internally coherent?
-
[13]
Specificity (Genericness): How specific, informative, and non-generic is the reasoning? Respond strictly with a Python-style list of floats in this format: [alignment_score, groundedness_score, genericness] Do not include any explanations, comments, or extra output. Examples:{2 examples} Text:{original_text} Model Output:{model_output} Table 13: The Rewar...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.