Recognition: unknown
Does Self-Consistency Improve the Recall of Encyclopedic Knowledge?
Pith reviewed 2026-05-10 02:20 UTC · model grok-4.3
The pith
Self-consistency improves both symbolic reasoning and encyclopedic knowledge recall on MMLU.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By partitioning MMLU into validated knowledge-recall and symbolic-reasoning subsets, the authors establish that self-consistency applied to chain-of-thought prompting improves accuracy on knowledge-recall questions even though chain-of-thought alone mainly helps reasoning. The result is an overall accuracy of 89 percent on MMLU using GPT-4o.
What carries the argument
A data-driven heuristic that partitions MMLU questions into knowledge-recall and symbolic-reasoning subsets to isolate the effect of self-consistency on each.
If this is right
- Self-consistency becomes applicable to a wider range of tasks that mix knowledge recall with reasoning.
- An overall accuracy of 89 percent on MMLU is reached with GPT-4o without further training.
- Sampling multiple reasoning paths helps retrieve correct facts even when explicit reasoning is not required.
- The gap between reasoning and pure recall capabilities in models narrows when consistency is enforced.
Where Pith is reading between the lines
- Multiple model generations may function as an internal check that surfaces stored facts more reliably.
- The same self-consistency procedure could be applied to other factual benchmarks to measure generalization.
- The benefit may stem from ensemble effects on how the model retrieves information from its parameters rather than from explicit reasoning alone.
Load-bearing premise
The data-driven heuristic from prior work accurately separates MMLU questions into knowledge-recall versus symbolic-reasoning subsets.
What would settle it
If self-consistency produces no accuracy gain on the knowledge-recall subset or if that subset's performance patterns fail to match those of MedMCQA, the central claim would not hold.
Figures



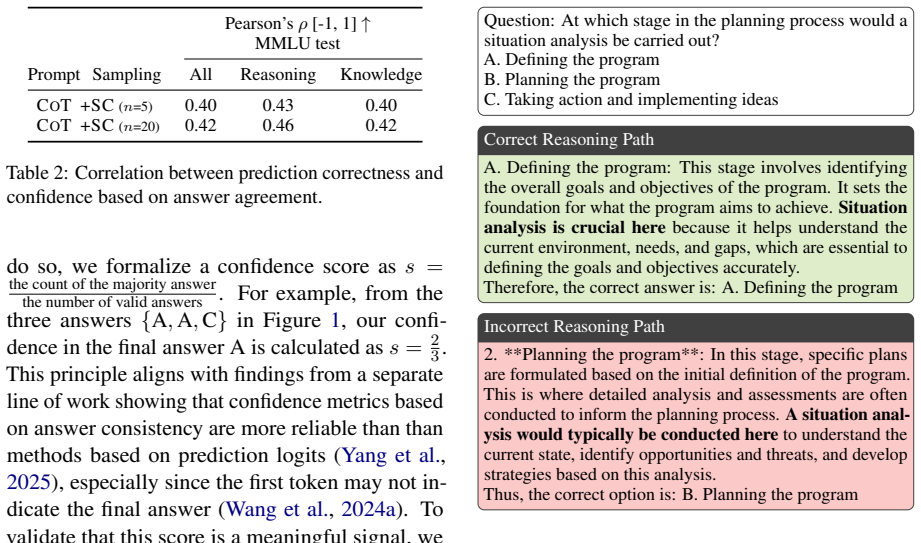

read the original abstract
While self-consistency is known to improve performance on symbolic reasoning, its effect on the recall of encyclopedic knowledge is unclear due to a lack of targeted evaluation grounds. To address this, we establish such a knowledge recall split for the popular MMLU benchmark by applying a data-driven heuristic from prior work. We validate this split by showing that the performance patterns on the symbolic reasoning and knowledge recall subsets mirror those of GSM8K and MedMCQA, respectively. Using this solid ground, we find that self-consistency consistently improves performance across both symbolic reasoning and knowledge recall, even though its underlying CoT prompting is primarily effective for symbolic reasoning. As a result, we achieve an 89\% accuracy on MMLU, the best performance to date with the use of GPT-4o.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper investigates whether self-consistency improves recall of encyclopedic knowledge, which is unclear due to lack of targeted evaluations. It creates a split of MMLU into symbolic-reasoning and knowledge-recall subsets via a data-driven heuristic from prior work, validates the split by showing performance patterns mirror GSM8K and MedMCQA respectively, demonstrates that self-consistency improves both subsets (though CoT is mainly for symbolic), and reports 89% accuracy on MMLU with GPT-4o as the best to date.
Significance. If the split is valid, the result would be significant by showing self-consistency has utility beyond symbolic reasoning into knowledge recall, where CoT prompting is less effective. The 89% MMLU score is a strong empirical outcome. The validation strategy using independent external benchmarks (GSM8K, MedMCQA) is a positive aspect that helps ground the analysis and lowers circularity risk.
major comments (2)
- [§4] §4 (Validation of the MMLU split): The split is validated only by showing that performance patterns on the subsets mirror those of GSM8K (symbolic) and MedMCQA (knowledge). This indirect approach does not include direct evidence such as human annotation of question types or qualitative examples confirming the subsets isolate encyclopedic knowledge. Since the central claim that self-consistency aids knowledge recall depends on this distinction, the validation needs strengthening to support the conclusion.
- [§5] §5 (Results on MMLU): The 89% accuracy is claimed as the best to date, but the exact experimental configuration (e.g., number of self-consistency paths, sampling temperature, prompt templates, and whether the full MMLU or a subset was used) requires more explicit reporting to assess reproducibility and the magnitude of the improvement.
minor comments (3)
- [Abstract] Abstract: The statement 'the best performance to date with the use of GPT-4o' should include a citation to the prior best result for proper context and comparison.
- [§2] §2 (Related Work): Additional details on the data-driven heuristic from prior work, such as its exact decision criteria, would improve accessibility without requiring readers to consult the reference.
- [Figures] Figures: Performance plots should include error bars or confidence intervals to convey variability across runs or seeds.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help clarify how to strengthen the presentation of our results. We address each major comment below and commit to revisions that improve the manuscript without altering its core claims or methodology.
read point-by-point responses
-
Referee: [§4] §4 (Validation of the MMLU split): The split is validated only by showing that performance patterns on the subsets mirror those of GSM8K (symbolic) and MedMCQA (knowledge). This indirect approach does not include direct evidence such as human annotation of question types or qualitative examples confirming the subsets isolate encyclopedic knowledge. Since the central claim that self-consistency aids knowledge recall depends on this distinction, the validation needs strengthening to support the conclusion.
Authors: We agree that the current validation is indirect and that adding direct evidence would strengthen the paper. In the revision we will include a new appendix with representative qualitative examples from both the symbolic-reasoning and knowledge-recall subsets, chosen to illustrate the heuristic's output. These examples will make the distinction between question types explicit and provide the direct evidence requested. While a full human annotation study of the entire split would be valuable, it lies outside the scope and resources of the present work; the added examples directly address the concern while preserving the data-driven, non-circular validation strategy already employed. revision: yes
-
Referee: [§5] §5 (Results on MMLU): The 89% accuracy is claimed as the best to date, but the exact experimental configuration (e.g., number of self-consistency paths, sampling temperature, prompt templates, and whether the full MMLU or a subset was used) requires more explicit reporting to assess reproducibility and the magnitude of the improvement.
Authors: We fully agree that reproducibility requires explicit reporting of these details. In the revised manuscript we will add a dedicated subsection (and accompanying table) that specifies the number of self-consistency paths sampled, the sampling temperature, the complete prompt templates, and confirmation that the full MMLU benchmark (not a subset) was used. This information will allow readers to replicate the 89% result and evaluate the improvement magnitude precisely. revision: yes
Circularity Check
No significant circularity; empirical validation relies on independent benchmarks
full rationale
The paper applies a data-driven heuristic from prior work to create MMLU subsets and validates the split by observing that performance patterns on the subsets mirror those on the external, independent benchmarks GSM8K (symbolic) and MedMCQA (knowledge recall). This mirroring serves as confirmatory evidence rather than a definitional or fitted tautology. No equations, self-definitional parameters, or load-bearing self-citations reduce the central experimental claims to the inputs by construction. The findings on self-consistency effects are grounded in direct model evaluations across the subsets.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The data-driven heuristic from prior work correctly partitions MMLU questions into knowledge-recall and symbolic-reasoning subsets.
Reference graph
Works this paper leans on
-
[1]
2022 , volume =
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , author =. 2022 , volume =
2022
-
[2]
2022 , volume =
Large Language Models are Zero-Shot Reasoners , author =. 2022 , volume =
2022
-
[3]
Yubo Wang and Xueguang Ma and Ge Zhang and Yuansheng Ni and Abhranil Chandra and Shiguang Guo and Weiming Ren and Aaran Arulraj and Xuan He and Ziyan Jiang and Tianle Li and Max Ku and Kai Wang and Alex Zhuang and Rongqi Fan and Xiang Yue and Wenhu Chen , journal=NeurIPS, year=
-
[4]
Note on regression and inheritance in the case of two parents
Pearson, Karl. Note on regression and inheritance in the case of two parents. Proceedings of the Royal Society of London. 1895
-
[5]
Chi and Jeff Dean and Jacob Devlin and Adam Roberts and Denny Zhou and Quoc V
Hyung Won Chung and Le Hou and Shayne Longpre and Barret Zoph and Yi Tay and William Fedus and Yunxuan Li and Xuezhi Wang and Mostafa Dehghani and Siddhartha Brahma and Albert Webson and Shixiang Shane Gu and Zhuyun Dai and Mirac Suzgun and Xinyun Chen and Aakanksha Chowdhery and Alex Castro-Ros and Marie Pellat and Kevin Robinson and Dasha Valter and Sha...
-
[6]
Pattern Recognition Letters , year =
Tom Fawcett , title =. Pattern Recognition Letters , year =
-
[7]
Show Your Work: Scratchpads for Intermediate Computation with Language Models , author=. 2022
2022
-
[8]
Self-Consistency Improves Chain of Thought Reasoning in Language Models , author=
-
[9]
2021 , url=
Measuring Massive Multitask Language Understanding , author=. 2021 , url=
2021
-
[10]
`` My Answer is C '' : First-Token Probabilities Do Not Match Text Answers in Instruction-Tuned Language Models
Wang, Xinpeng and Ma, Bolei and Hu, Chengzhi and Weber-Genzel, Leon and R. `` My Answer is C '' : First-Token Probabilities Do Not Match Text Answers in Instruction-Tuned Language Models. Findings of the Association for Computational Linguistics: ACL 2024. 2024
2024
-
[11]
Answering Questions by Meta-Reasoning over Multiple Chains of Thought
Yoran, Ori and Wolfson, Tomer and Bogin, Ben and Katz, Uri and Deutch, Daniel and Berant, Jonathan. Answering Questions by Meta-Reasoning over Multiple Chains of Thought. 2023
2023
-
[12]
MedMCQA : A Large-scale Multi-Subject Multi-Choice Dataset for Medical domain Question Answering
Pal, Ankit and Umapathi, Logesh Kumar and Sankarasubbu, Malaikannan. MedMCQA : A Large-scale Multi-Subject Multi-Choice Dataset for Medical domain Question Answering. Proceedings of the 5th AHLI Conference on Health, Inference, and Learning. 2022
2022
-
[13]
Are We Done with MMLU ?
Gema, Aryo Pradipta and Leang, Joshua Ong Jun and Hong, Giwon and Devoto, Alessio and Mancino, Alberto Carlo Maria and Saxena, Rohit and He, Xuanli and Zhao, Yu and Du, Xiaotang and Ghasemi Madani, Mohammad Reza and Barale, Claire and McHardy, Robert and Harris, Joshua and Kaddour, Jean and Van Krieken, Emile and Minervini, Pasquale. Are We Done with MMLU ?. 2025
2025
-
[14]
Zayne Rea Sprague and Fangcong Yin and Juan Diego Rodriguez and Dongwei Jiang and Manya Wadhwa and Prasann Singhal and Xinyu Zhao and Xi Ye and Kyle Mahowald and Greg Durrett , booktitle=ICLR2025, year=. To
-
[15]
MAQA : Evaluating Uncertainty Quantification in LLM s Regarding Data Uncertainty
Yang, Yongjin and Yoo, Haneul and Lee, Hwaran. MAQA : Evaluating Uncertainty Quantification in LLM s Regarding Data Uncertainty. Findings of the Association for Computational Linguistics: NAACL 2025. 2025
2025
-
[16]
Which of These Best Describes Multiple Choice Evaluation with LLM s? A ) Forced B ) Flawed C ) Fixable D ) All of the Above
Balepur, Nishant and Rudinger, Rachel and Boyd-Graber, Jordan Lee. Which of These Best Describes Multiple Choice Evaluation with LLM s? A ) Forced B ) Flawed C ) Fixable D ) All of the Above. 2025
2025
-
[17]
MMLU - CF : A Contamination-free Multi-task Language Understanding Benchmark
Zhao, Qihao and Huang, Yangyu and Lv, Tengchao and Cui, Lei and Sun, Qinzheng and Mao, Shaoguang and Zhang, Xin and Xin, Ying and Yin, Qiufeng and Li, Scarlett and Wei, Furu. MMLU - CF : A Contamination-free Multi-task Language Understanding Benchmark. 2025
2025
-
[18]
ICML 2024 Workshop on In-Context Learning , year=
Universal Self-Consistency for Large Language Models , author=. ICML 2024 Workshop on In-Context Learning , year=
2024
-
[19]
and Neubig, Graham
Robinson, Nathaniel and Ogayo, Perez and Mortensen, David R. and Neubig, Graham. C hat GPT MT : Competitive for High- (but Not Low-) Resource Languages. Proceedings of the Eighth Conference on Machine Translation. 2023
2023
-
[20]
2020 , url=
The Curious Case of Neural Text Degeneration , author=. 2020 , url=
2020
-
[21]
Statistical Significance Tests for Machine Translation Evaluation
Koehn, Philipp. Statistical Significance Tests for Machine Translation Evaluation. 2004
2004
-
[22]
Tairan Fu and Javier Conde and Gonzalo Martínez and María Grandury and Pedro Reviriego , year=. Multiple Choice Questions: Reasoning Makes Large Language Models (. 2501.09775 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
2021 , eprint=
Training Verifiers to Solve Math Word Problems , author=. 2021 , eprint=
2021
-
[24]
OpenAI and Josh Achiam and Steven Adler and Sandhini Agarwal and Lama Ahmad and Ilge Akkaya and Florencia Leoni Aleman and Diogo Almeida and Janko Altenschmidt and Sam Altman and Shyamal Anadkat and Red Avila and Igor Babuschkin and Suchir Balaji and Valerie Balcom and Paul Baltescu and Haiming Bao and Mohammad Bavarian and Jeff Belgum and Irwan Bello and...
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
2024 , eprint=
Gemini: A Family of Highly Capable Multimodal Models , author=. 2024 , eprint=
2024
-
[26]
2025 , eprint=
Qwen2.5 Technical Report , author=. 2025 , eprint=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.