HumorRank: A Tournament-Based Leaderboard for Evaluating Humor Generation in Large Language Models
Pith reviewed 2026-05-13 23:01 UTC · model grok-4.3
The pith
HumorRank ranks language models on humor generation through automated joke tournaments that reveal skill in comedic mechanisms over model size.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
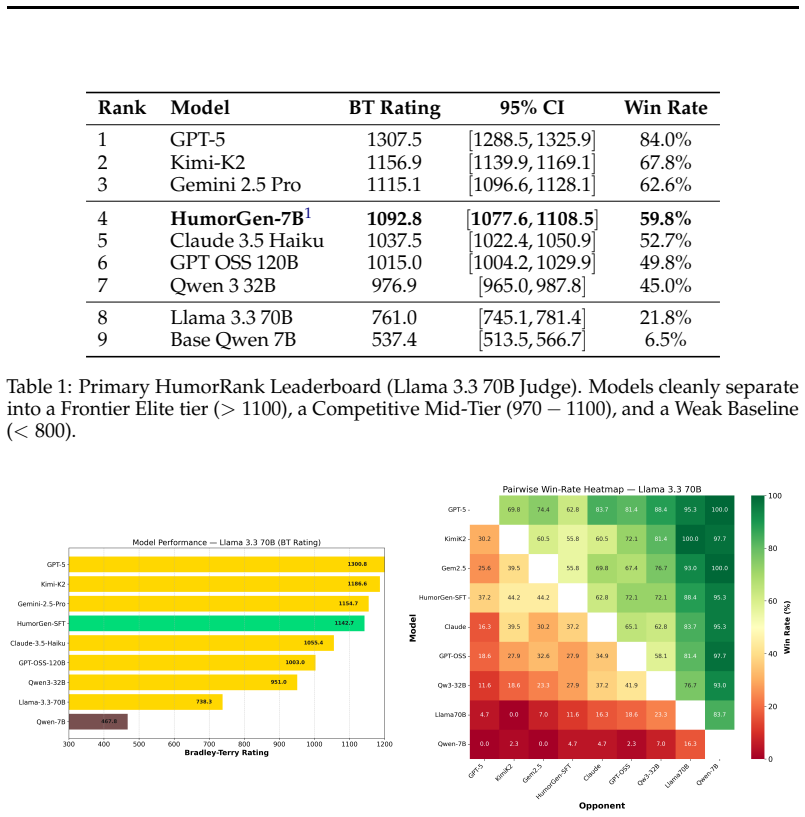
HumorRank is a tournament-based evaluation framework and leaderboard that performs automated pairwise comparisons of LLM-generated humor using judgments grounded in the General Theory of Verbal Humor, aggregates those results via an Adaptive Swiss tournament, and derives globally consistent rankings through Bradley-Terry Maximum Likelihood Estimation, yielding statistically grounded model stratifications that show humor quality depends on mastery of comedic mechanisms rather than model scale.
What carries the argument
HumorRank tournament system that converts GTVH-grounded pairwise judgments into global rankings through Adaptive Swiss scheduling and Bradley-Terry MLE.
Load-bearing premise
Automated pairwise judgments based on the General Theory of Verbal Humor accurately capture true humor quality without systematic bias.
What would settle it
A direct comparison study in which human raters evaluate the same model outputs and produce model rankings that differ substantially from those generated by HumorRank.
Figures









read the original abstract
Humor remains difficult to evaluate in large language models (LLMs) because what makes a response funny is subjective, comparative, and shaped by interacting comedic mechanisms rather than a single scalar property. Existing humor evaluation protocols therefore tend to produce isolated scores or task-specific judgments that are difficult to compare across models. We introduce HumorRank, a tournament-based framework for ranking textual humor generation through theory-grounded pairwise preference judgments. Across SemEval-2026 MWAHAHA and Humor Transfer Bench, HumorRank evaluates nine proprietary, open-weight, and specialized models using LLM-based comparative judgments informed by the General Theory of Verbal Humor (GTVH), with tournament aggregation yielding global rankings via Bradley-Terry estimation. The resulting rankings are cross-judge stable: independent Llama and Qwen LLM judges achieve Kendall {\tau} = 0.889 on both benchmarks. The leaderboard reveals clear model stratification, showing that strong humor generation depends not only on scale but on mastery of comedic mechanisms such as incongruity, conciseness, escalation, and absurdity. HumorRank provides a scalable and interpretable methodology for benchmarking LLM-generated humor without relying solely on isolated automatic metrics or limited human evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces HumorRank, a tournament-based evaluation framework and leaderboard for textual humor generation in LLMs. Using the SemEval-2026 MWAHAHA test dataset, it conducts automated pairwise judgments grounded in the General Theory of Verbal Humor (GTVH) across nine models, aggregates outcomes via an Adaptive Swiss tournament, and applies Bradley-Terry MLE to produce globally consistent rankings. The central claim is that these rankings yield statistically grounded stratifications demonstrating that humor quality is driven by mastery of comedic mechanisms rather than model scale alone.
Significance. If the automated judgments prove reliable, HumorRank would provide a valuable, scalable methodology for unified benchmarking of LLM humor generation, replacing isolated incomparable metrics with interpretable global rankings. The GTVH grounding and Bradley-Terry aggregation offer a theoretically motivated and reproducible approach that could help track progress and identify key drivers of humor capability.
major comments (2)
- [Evaluation pipeline] Evaluation pipeline (abstract and methods): The automated GTVH-based pairwise judgments lack any reported human validation, inter-annotator agreement metrics, or bias audit. This is load-bearing for the headline claim that the stratifications show mechanism mastery (not scale) drives humor quality, as systematic bias in the LLM judge correlated with model family or size could artifactually produce the observed inversion.
- [Results section] Results section: No statistical significance tests for the scale-vs-mechanism finding, confidence intervals on the Bradley-Terry parameters, or sensitivity analysis to Adaptive Swiss tournament parameters are reported, leaving the assertion of 'statistically grounded model stratifications' under-supported.
Simulated Author's Rebuttal
We thank the referee for their insightful comments, which highlight important areas for strengthening the manuscript. We address each major point below and commit to revisions that enhance the rigor and transparency of our evaluation framework.
read point-by-point responses
-
Referee: Evaluation pipeline (abstract and methods): The automated GTVH-based pairwise judgments lack any reported human validation, inter-annotator agreement metrics, or bias audit. This is load-bearing for the headline claim that the stratifications show mechanism mastery (not scale) drives humor quality, as systematic bias in the LLM judge correlated with model family or size could artifactually produce the observed inversion.
Authors: We agree that human validation is essential to substantiate the reliability of the automated GTVH judgments and rule out potential biases. In the revised manuscript, we will add a dedicated validation subsection reporting results from a human study on a stratified sample of 300 pairwise comparisons. This will include inter-annotator agreement metrics (Cohen's kappa and Fleiss' kappa), a bias audit examining correlations between judgment errors and model family/size, and qualitative analysis of disagreement cases. These additions will directly support the claim that observed stratifications reflect genuine differences in comedic mechanism mastery rather than judge artifacts. revision: yes
-
Referee: Results section: No statistical significance tests for the scale-vs-mechanism finding, confidence intervals on the Bradley-Terry parameters, or sensitivity analysis to Adaptive Swiss tournament parameters are reported, leaving the assertion of 'statistically grounded model stratifications' under-supported.
Authors: We acknowledge that the current results section would be strengthened by explicit statistical support. In the revision, we will expand the results to include: bootstrap 95% confidence intervals on all Bradley-Terry parameters; statistical significance tests (Mann-Whitney U and permutation tests) comparing the mechanism-mastery group against scale-based groupings; and sensitivity analyses varying Adaptive Swiss parameters (e.g., round count from 4-12 and reporting Kendall tau rank stability across configurations). These will be presented with tables and figures to rigorously ground the reported stratifications. revision: yes
Circularity Check
No circularity: HumorRank rankings derive from external GTVH judgments aggregated by standard MLE without self-referential reduction
full rationale
The paper's derivation chain consists of (1) applying the external General Theory of Verbal Humor to generate automated pairwise judgments on the SemEval-2026 dataset, followed by (2) aggregation via Adaptive Swiss tournament and Bradley-Terry MLE to produce global rankings. No equations, self-citations, or ansatzes reduce the final stratifications or the claim that mechanism mastery (not scale) drives quality to the inputs by construction. The MLE step is a standard statistical aggregation of independent judgment data; GTVH supplies an external theoretical basis rather than a self-defined loop. Absence of human validation is a correctness risk but does not match any enumerated circularity pattern.
Axiom & Free-Parameter Ledger
free parameters (1)
- Bradley-Terry strength parameters
axioms (1)
- domain assumption General Theory of Verbal Humor provides valid, automatable criteria for judging relative humor quality
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Pairwise judgments grounded in the General Theory of Verbal Humor (GTVH) are aggregated via an Adaptive Swiss tournament, with Bradley-Terry Maximum Likelihood Estimation (MLE) producing globally consistent humor generation capability rankings.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.