TactileEval: A Step Towards Automated Fine-Grained Evaluation and Editing of Tactile Graphics
Pith reviewed 2026-05-10 04:15 UTC · model grok-4.3
The pith
A five-category taxonomy derived from expert comments lets a vision model evaluate tactile graphics at 85.7 percent accuracy and guide targeted edits.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
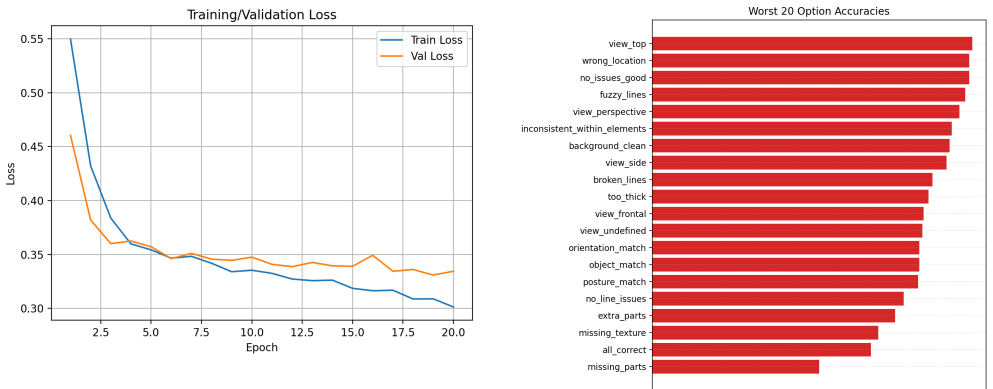
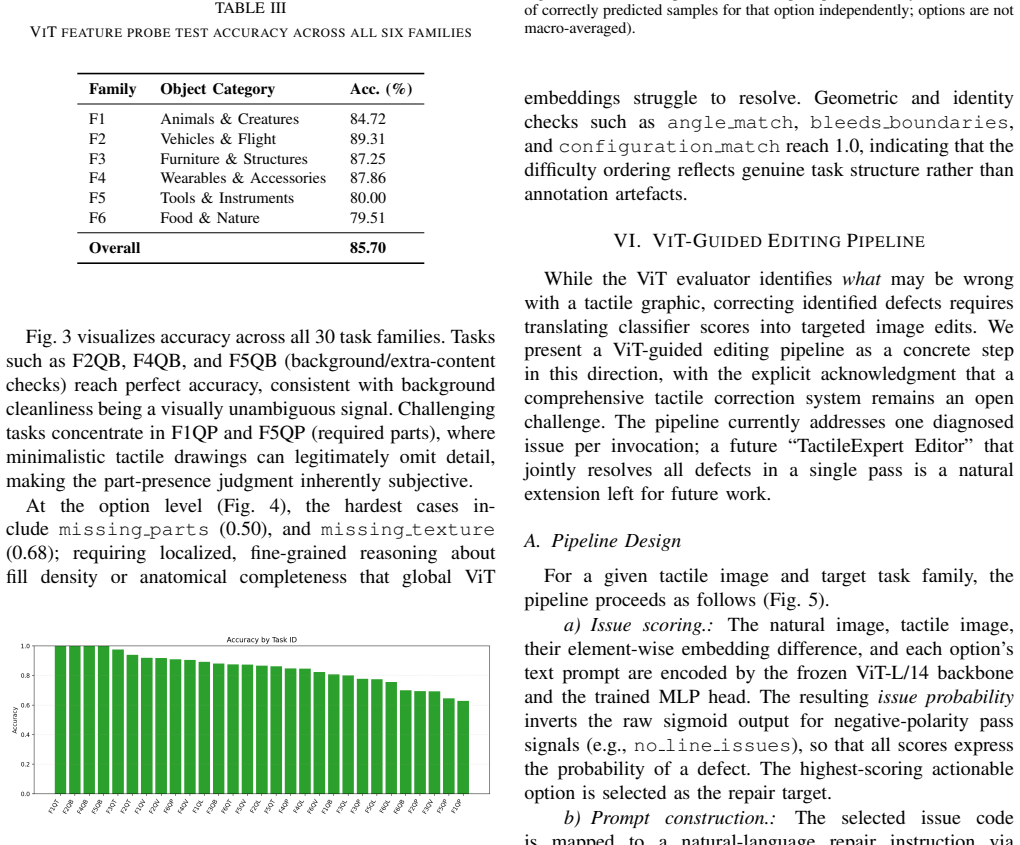
TactileEval is a three-stage pipeline that first extracts a five-category quality taxonomy from expert free-text comments on the TactileNet dataset, then collects 14,095 structured annotations across 66 object classes in six families, trains a reproducible ViT-L/14 feature probe that achieves 85.70 percent overall test accuracy on 30 tasks with consistent difficulty ordering, and finally routes those scores through family-specific prompt templates to produce targeted corrections via an image-editing model.
What carries the argument
The five-category quality taxonomy (view angle, part completeness, background clutter, texture separation, and line quality) aligned with BANA standards, which organizes the annotations, trains the feature probe, and supplies the routing logic for family-specific editing prompts.
If this is right
- The system supplies specific repair signals for individual problems instead of only holistic quality scores.
- Family-specific prompt templates allow the editing stage to address each quality category in a targeted way.
- Consistent difficulty ordering across the thirty tasks indicates the taxonomy reflects real perceptual distinctions.
- Coverage of sixty-six classes in six families suggests the pipeline can apply across a range of common tactile graphic content.
Where Pith is reading between the lines
- The same annotation-and-probe structure could be reused to evaluate other categories of educational diagrams that need fine-grained accessibility checks.
- If the editing stage reliably improves the graphics as judged by the original experts, it could measurably shorten the time required to produce usable tactile materials.
- Adding direct ratings from BVI learners themselves to the training data would test whether the current taxonomy already matches end-user experience.
Load-bearing premise
The taxonomy pulled from expert comments together with the MTurk annotations accurately reflects the perceptual and educational quality standards that BVI learners and BANA guidelines actually require.
What would settle it
A fresh round of ratings collected directly from BVI experts or BANA reviewers that shows low agreement with the model's predictions or reveals quality issues outside the five categories.
Figures




read the original abstract
Tactile graphics require careful expert validation before reaching blind and visually impaired (BVI) learners, yet existing datasets provide only coarse holistic quality ratings that offer no actionable repair signal. We present TactileEval, a three-stage pipeline that takes a first step toward automating this process. Drawing on expert free-text comments from the TactileNet dataset, we establish a five-category quality taxonomy; encompassing view angle, part completeness, background clutter, texture separation, and line quality aligned with BANA standards. We subsequently gathered 14,095 structured annotations via Amazon Mechanical Turk, spanning 66 object classes organized into six distinct families. A reproducible ViT-L/14 feature probe trained on this data achieves 85.70% overall test accuracy across 30 different tasks, with consistent difficulty ordering suggesting the taxonomy suggesting the taxonomy captures meaningful perceptual structure. Building on these evaluations, we present a ViT-guided automated editing pipeline that routes classifier scores through family-specific prompt templates to produce targeted corrections via gpt-image-1 image editing. Code, data, and models are available at https://TactileEval.github.io/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents TactileEval, a three-stage pipeline for automated fine-grained evaluation and editing of tactile graphics. It derives a five-category taxonomy (view angle, part completeness, background clutter, texture separation, line quality) from expert free-text comments in TactileNet, collects 14,095 MTurk annotations over 66 object classes in six families, trains a reproducible ViT-L/14 feature probe that reaches 85.70% overall test accuracy across 30 tasks with consistent difficulty ordering, and routes the resulting scores through family-specific prompts to gpt-image-1 for targeted edits. Code, data, and models are released.
Significance. If the central claims hold, the work supplies the first publicly available, fine-grained, machine-checkable taxonomy and annotation set for tactile-graphics quality, together with a reproducible linear probe and an editing prototype. This moves the field beyond coarse holistic ratings toward actionable, BANA-aligned repair signals and provides a concrete baseline that future BVI-validated studies can build upon.
major comments (2)
- [Abstract and Evaluation] The claim that the taxonomy and 85.70% accuracy demonstrate 'meaningful perceptual structure' for BVI learners rests on MTurk annotations collected from sighted workers and a taxonomy extracted from expert free-text comments. No direct correlation is reported between these labels and either BVI haptic exploration or BANA-expert ratings on the same graphics; therefore the observed accuracy and difficulty ordering could reflect shared visual biases rather than the target standards (Abstract; §4).
- [Abstract and §4] The abstract and evaluation sections report 85.70% overall test accuracy but supply no information on train-test split ratios, class-imbalance handling, inter-annotator agreement statistics, or any quantitative metric for the editing stage. These omissions prevent assessment of whether the probe performance is robust or merely an artifact of the annotation protocol.
minor comments (2)
- [Abstract] The abstract contains a duplicated phrase: 'suggesting the taxonomy suggesting the taxonomy captures'.
- [Abstract] The abstract states '30 different tasks' without enumerating them or indicating how they map onto the five taxonomy categories.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below, acknowledging limitations where the current study lacks direct evidence, and describe the revisions planned for the next version of the manuscript.
read point-by-point responses
-
Referee: [Abstract and Evaluation] The claim that the taxonomy and 85.70% accuracy demonstrate 'meaningful perceptual structure' for BVI learners rests on MTurk annotations collected from sighted workers and a taxonomy extracted from expert free-text comments. No direct correlation is reported between these labels and either BVI haptic exploration or BANA-expert ratings on the same graphics; therefore the observed accuracy and difficulty ordering could reflect shared visual biases rather than the target standards (Abstract; §4).
Authors: We agree that the manuscript does not report direct correlations between the MTurk labels and either BVI haptic exploration data or BANA-expert ratings on the identical graphics. The five-category taxonomy was extracted from expert free-text comments in TactileNet and explicitly aligned with BANA standards, while the 14,095 MTurk annotations supply scalable, reproducible labels from sighted workers. The consistent difficulty ordering across the 30 tasks provides initial evidence that the taxonomy captures structured variation, yet we recognize this ordering could partly reflect visual biases. In the revised manuscript we will add a dedicated Limitations subsection in §4 (and update the abstract claim) that explicitly states the absence of BVI/BANA validation on the annotated set and outlines planned future studies to collect such ratings. We do not claim the current results fully substitute for BVI-validated standards but present them as a reproducible first step. revision: partial
-
Referee: [Abstract and §4] The abstract and evaluation sections report 85.70% overall test accuracy but supply no information on train-test split ratios, class-imbalance handling, inter-annotator agreement statistics, or any quantitative metric for the editing stage. These omissions prevent assessment of whether the probe performance is robust or merely an artifact of the annotation protocol.
Authors: We accept that these protocol details were omitted from the submitted version. In the revised manuscript we will expand §4 (and the abstract if space permits) to report: the train-test split ratios and stratification method, the approach taken to class imbalance, inter-annotator agreement statistics computed over the MTurk annotations, and a quantitative metric for the editing stage (pre-/post-edit classifier score deltas on a held-out subset together with a small-scale human preference study). These additions will allow readers to evaluate the robustness of the reported 85.70% accuracy and the editing pipeline. revision: yes
- Direct correlation between the collected MTurk annotations and BVI haptic exploration or BANA-expert ratings on the same graphics, as no such ratings exist in the current dataset.
Circularity Check
No circularity in derivation or evaluation chain
full rationale
The paper extracts a five-category taxonomy from expert free-text comments on TactileNet, collects 14,095 independent MTurk annotations on held-out graphics, and trains/evaluates a ViT-L/14 probe on a separate test split achieving 85.70% accuracy. The reported performance and difficulty ordering are measured on data disjoint from taxonomy construction; no equations, fitted parameters, or self-citations reduce the accuracy claim to a definitional or statistical tautology. The pipeline is self-contained against external benchmarks with no load-bearing self-citation, ansatz smuggling, or renaming of known results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption MTurk annotations collected under the five-category schema align with the quality judgments of tactile-graphics experts and BANA standards.
invented entities (1)
-
Five-category quality taxonomy (view angle, part completeness, background clutter, texture separation, line quality)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
M. Mukhiddinov and S.-Y . Kim, “A systematic literature review on the automatic creation of tactile graphics for the blind and visually impaired,”Processes, vol. 9, no. 10, p. 1726, 2021
work page 2021
-
[2]
Tactile graphics production and its principles,
P. ˇCervenka, M. Hanouskov ´a, L. M ´asilko, O. Ne ˇcas,et al., “Tactile graphics production and its principles,”Brno: Masaryk University Teiresi´as–Support Centre for Students with Special Needs, 2013
work page 2013
-
[3]
A. Khan, A. Choubineh, M. A. Shaaban, A. Akkasi, and M. Komeili, “Tactilenet: Bridging the accessibility gap with ai-generated tactile graphics for individuals with vision impairment,” in2025 IEEE International Conference on Systems, Man, and Cybernetics (SMC), pp. 569–576, IEEE, 2025
work page 2025
-
[4]
P. Edman,Tactile graphics. American Foundation for the Blind, 1992
work page 1992
-
[5]
Guidelines and stan- dards for tactile graphics,
Braille Authority of North America, “Guidelines and stan- dards for tactile graphics,” 2010. Available athttp://www. brailleauthority.org
work page 2010
-
[6]
Making diagrams acces- sible to blind and partially sighted people,
Royal National Institute of Blind People, “Making diagrams acces- sible to blind and partially sighted people,” 2010. RNIB Technical Guidance
work page 2010
-
[7]
Single-line drawing vectoriza- tion,
T. Magne and O. Sorkine-Hornung, “Single-line drawing vectoriza- tion,” inComputer Graphics Forum, vol. 44, p. e70228, Wiley Online Library, 2025
work page 2025
-
[8]
Text-guided image-to-image translation for tactile map generation,
A. Choubineh, A. Akkasi, A. Khan, and M. Komeili, “Text-guided image-to-image translation for tactile map generation,” in2025 In- ternational Joint Conference on Neural Networks (IJCNN), pp. 1–9, IEEE, 2025
work page 2025
-
[9]
Image database tid2013: Peculiarities, results and perspectives,
N. Ponomarenko, L. Jin, O. Ieremeiev, V . Lukin, K. Egiazarian, J. As- tola, B. V ozel, K. Chehdi, M. Carli, F. Battisti,et al., “Image database tid2013: Peculiarities, results and perspectives,”Signal processing: Image communication, vol. 30, pp. 57–77, 2015
work page 2015
-
[10]
Kadid-10k: A large-scale artificially distorted iqa database,
H. Lin, V . Hosu, and D. Saupe, “Kadid-10k: A large-scale artificially distorted iqa database,” in2019 Eleventh International Conference on Quality of Multimedia Experience (QoMEX), pp. 1–3, IEEE, 2019
work page 2019
-
[11]
Cheap and fast– but is it good? evaluating non-expert annotations for natural language tasks,
R. Snow, B. O’connor, D. Jurafsky, and A. Y . Ng, “Cheap and fast– but is it good? evaluating non-expert annotations for natural language tasks,” inProceedings of the 2008 conference on empirical methods in natural language processing, pp. 254–263, 2008
work page 2008
-
[12]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark,et al., “Learning transferable visual models from natural language supervision,” inInternational conference on machine learning, pp. 8748–8763, PmLR, 2021
work page 2021
-
[13]
Contrastive self-supervised learning: a survey on different architectures,
A. Khan, S. AlBarri, and M. A. Manzoor, “Contrastive self-supervised learning: a survey on different architectures,” in2022 2nd international conference on artificial intelligence (icai), pp. 1–6, IEEE, 2022
work page 2022
-
[14]
J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkat,et al., “Gpt-4 technical report,”arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
H. Liu, C. Li, Q. Wu, and Y . J. Lee, “Visual instruction tuning,”Ad- vances in neural information processing systems, vol. 36, pp. 34892– 34916, 2023
work page 2023
-
[16]
Laion-5b: an open large-scale dataset for training next generation image-text models,
C. Schuhmann, R. Beaumont, R. Vencu, C. Gordon, R. Wight- man, M. Cherti, T. Coombes, A. Katta, C. Mullis, M. Wortsman, P. Schramowski, S. Kundurthy, K. Crowson, L. Schmidt, R. Kacz- marczyk, and J. Jitsev, “Laion-5b: an open large-scale dataset for training next generation image-text models,” inProceedings of the 36th International Conference on Neural I...
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.