Unsupervised Learning of Inter-Object Relationships via Group Homomorphism
Pith reviewed 2026-05-10 00:51 UTC · model grok-4.3
The pith
Group homomorphism constraint lets a neural net segment objects and map relative motions without labels
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By embedding the algebraic requirement that a neural-network mapping preserve group operations, the model factors pixel-level image changes into additive components that correspond to independent object motions and interactions. In the resulting representation, each object occupies its own slot and relative displacements appear as simple additive values along a single latent axis, all learned without any segmentation or motion labels.
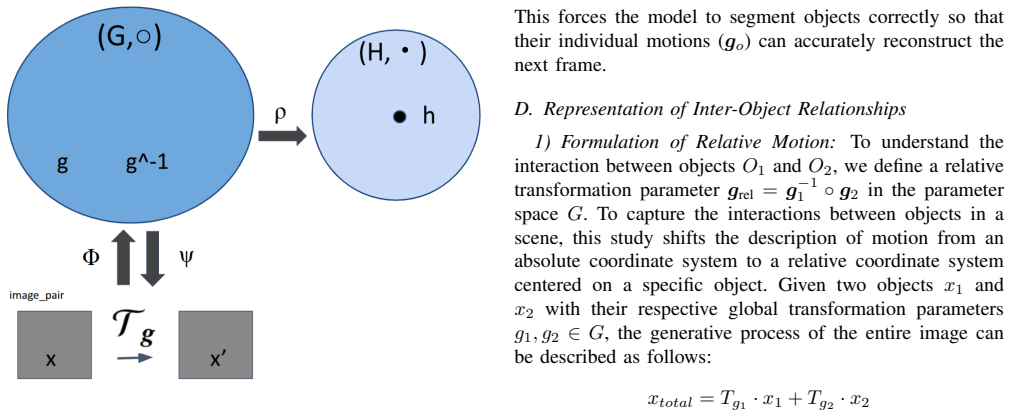
What carries the argument
Group homomorphism constraint: a structural requirement inside the network that forces the learned mapping to preserve the composition of transformations, thereby separating translation, deformation, and inter-object relations into distinct additive factors.
If this is right
- Object segmentation and motion decomposition become possible from raw video alone.
- Relative movements between objects are represented as exact additive quantities in a low-dimensional space.
- The same architecture can be applied to other interaction tasks that obey group-like transformation rules.
Where Pith is reading between the lines
- The same homomorphism constraint might be useful for learning rigid-body dynamics or articulated motion without supervision.
- If the latent additive space is truly one-dimensional, simple arithmetic operations on it could predict future object positions.
- Replacing statistical independence with algebraic preservation could reduce the amount of data needed for learning physical structure.
Load-bearing premise
The hierarchical structure of group operations supplies a useful inductive bias for producing physically meaningful, disentangled representations of object motion in real scenes.
What would settle it
Train the model on a new set of dynamic scenes whose ground-truth object masks and relative-motion values are known; check whether the learned slots match the masks and the latent coordinates recover the true relative displacements to within a small additive error.
Figures





read the original abstract
While current deep learning models achieve high performance by learning statistical correlations from vast datasets,which stands in stark contrast to human learning. They lack the flexibility of humans-particularly preverbal infants-to autonomously acquire the underlying structure of the world from limited experience and adapt to novel situations. In this study, we propose an unsupervised representation learning method based on a hierarchical relationship in group operations, rather than statistical independence, aiming to build a computational model of the cognitive development of infants. The proposed model features an integrated architecture that simultaneously performs object segmentation and the extraction of motion laws from dynamic image sequences. By introducing the Homomorphism from algebra as a structural constraint within a neural network, the model structurally separates pixel-level changes into meaningful, decomposed transformation components, such as translation and deformation. Using interaction scenes (chasing and evading tasks) based on developmental science findings, we experimentally demonstrate that the model can segment multiple objects into individual slots without any ground-truth labels. Furthermore, we confirmed that relative movements between objects, such as approaching or receding, are accurately mapped and structured into a one-dimensional additive latent space. These results suggest that by introducing algebraic geometric constraints rather than relying solely on statistical correlation learning, physically interpretable "disentangled representations" can be acquired. This study contributes to the understanding of the process by which infants internalize environmental laws as structures and provides a new perspective for constructing artificial systems with developmental intelligence.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an unsupervised representation learning method that incorporates a group homomorphism as a structural constraint within a neural network architecture. This enables simultaneous object segmentation from dynamic image sequences and extraction of motion laws, demonstrated on chasing and evading interaction scenes. The model decomposes pixel-level changes into components such as translation and deformation, mapping relative object movements (e.g., approaching or receding) into a strictly one-dimensional additive latent space without ground-truth labels, aiming to model preverbal infant cognitive development via algebraic rather than purely statistical constraints.
Significance. If the homomorphism constraint can be shown to causally drive the claimed decomposition and additivity (beyond what reconstruction or attention losses alone achieve), the work would offer a distinctive algebraic approach to disentangled representations of object interactions. This could inform developmental AI models and provide interpretable alternatives to independence-based methods, with potential for physically grounded latent spaces in dynamic scenes.
major comments (3)
- [Abstract] Abstract: The central claim that the homomorphism 'structurally separates pixel-level changes into meaningful, decomposed transformation components' and enables 'accurate' one-dimensional additive mapping of relative movements lacks any quantitative verification, such as a homomorphism preservation metric (e.g., error on φ(g ∘ h) ≈ φ(g) + φ(h) for composed transformations) or ablation removing the constraint. Without these, it is impossible to confirm the algebraic structure is load-bearing rather than incidental to other losses.
- [Abstract] Abstract and experimental description: No architecture details, loss function formulations, quantitative metrics (e.g., segmentation IoU, latent space additivity error), baselines, or error analysis are provided for the chasing/evading tasks. This omission prevents assessment of whether the reported segmentation into slots and latent mapping hold under standard evaluation, undermining the experimental support for the homomorphism's effectiveness.
- [Abstract] The assumption that the hierarchical group operation provides a suitable constraint for physically interpretable disentanglement is presented without a concrete test (e.g., checking compositionality on successive approach/recede pairs). If the learned φ fails to satisfy the homomorphism property under composition, the segmentation and 1D mapping could arise independently of the group structure.
minor comments (1)
- [Abstract] The abstract contains minor grammatical issues (e.g., missing spaces after commas and inconsistent hyphenation in 'preverbal infants-to') that should be corrected for clarity.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive report. The comments correctly identify gaps in quantitative validation and experimental reporting that weaken the ability to assess the homomorphism constraint's role. We will revise the manuscript to incorporate the requested metrics, ablations, and details while preserving the core contribution.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the homomorphism 'structurally separates pixel-level changes into meaningful, decomposed transformation components' and enables 'accurate' one-dimensional additive mapping of relative movements lacks any quantitative verification, such as a homomorphism preservation metric (e.g., error on φ(g ∘ h) ≈ φ(g) + φ(h) for composed transformations) or ablation removing the constraint. Without these, it is impossible to confirm the algebraic structure is load-bearing rather than incidental to other losses.
Authors: We agree that the abstract and current experiments do not include a direct homomorphism preservation metric or ablation. The manuscript describes the constraint but does not quantify its causal contribution. In revision we will add (i) a homomorphism error metric computed on composed transformations and (ii) an ablation that removes the homomorphism loss while retaining reconstruction and attention terms, reporting the resulting degradation in segmentation and additivity. revision: yes
-
Referee: [Abstract] Abstract and experimental description: No architecture details, loss function formulations, quantitative metrics (e.g., segmentation IoU, latent space additivity error), baselines, or error analysis are provided for the chasing/evading tasks. This omission prevents assessment of whether the reported segmentation into slots and latent mapping hold under standard evaluation, undermining the experimental support for the homomorphism's effectiveness.
Authors: The full manuscript contains architecture diagrams and loss equations in Sections 3 and 4, yet we acknowledge the absence of standard quantitative metrics, baselines, and error bars. We will expand the experimental section to report segmentation IoU against synthetic ground truth, mean additivity error in the latent space, comparisons against reconstruction-only and attention-only baselines, and per-scene error analysis. revision: yes
-
Referee: [Abstract] The assumption that the hierarchical group operation provides a suitable constraint for physically interpretable disentanglement is presented without a concrete test (e.g., checking compositionality on successive approach/recede pairs). If the learned φ fails to satisfy the homomorphism property under composition, the segmentation and 1D mapping could arise independently of the group structure.
Authors: We accept that a direct test of compositionality on successive motion pairs is missing. We will add an experiment that applies two successive approach/recede transformations, measures the deviation of φ(g ∘ h) from φ(g) + φ(h), and shows that the learned mapping remains additive only when the homomorphism loss is active. revision: yes
Circularity Check
No circularity: homomorphism is an externally imposed algebraic constraint, not a self-referential fit or renaming.
full rationale
The paper introduces the group homomorphism explicitly as a structural constraint drawn from algebra to guide the neural network architecture for segmentation and latent mapping. No step reduces a claimed result to a fitted parameter renamed as prediction, a self-citation chain, or a definition that presupposes the output. The experimental claims (object segmentation without labels, additive 1D latent space for relative motions) are presented as outcomes of training under this external constraint rather than tautological consequences of the inputs. The derivation chain remains self-contained against external algebraic structure and empirical validation on interaction scenes.
Axiom & Free-Parameter Ledger
free parameters (1)
- latent space dimensionality
axioms (1)
- domain assumption Hierarchical relationships in group operations can serve as structural constraints to decompose pixel-level changes into transformation components like translation and deformation.
Reference graph
Works this paper leans on
-
[1]
Piaget,The Origins of Intelligence in Children, ser
J. Piaget,The Origins of Intelligence in Children, ser. Norton library. W.W. Norton, 1963. [Online]. Available: https://books.google.co.jp/books?id=3pwoAAAAY AAJ
work page 1963
-
[2]
Auto-encoding variational bayes,
D. P. Kingma, M. Welling,et al., “Auto-encoding variational bayes,” 2013
work page 2013
-
[3]
I. J. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y . Bengio, “Generative adversarial nets,” Advances in neural information processing systems, vol. 27, 2014
work page 2014
-
[4]
Mental causation in a physical world: A self-causation model of downward causation,
Y . Ohmura and Y . Kuniyoshi, “Mental causation in a physical world: A self-causation model of downward causation,” 2024. [Online]. Available: https://arxiv.org/abs/2310.10005
-
[5]
Considering a generative mechanism of consciousness from the perspective of inter-level causation
——, “Why consciousness should explain physical phenomena: Toward a testable theory,” 2025. [Online]. Available: https://arxiv.org/abs/2511.04047
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
A mathematical formalization of self-determining agency,
Y . Ohmura, E. K. Carr, and Y . Kuniyoshi, “A mathematical formalization of self-determining agency,” 2026. [Online]. Available: https://arxiv.org/abs/2601.02885
-
[7]
beta-vae: Learning basic visual concepts with a constrained variational framework,
I. Higgins, L. Matthey, A. Pal, C. Burgess, X. Glorot, M. Botvinick, S. Mohamed, and A. Lerchner, “beta-vae: Learning basic visual concepts with a constrained variational framework,” inInternational conference on learning representations, 2017
work page 2017
-
[8]
Object-centric learning with slot attention
F. Locatello, D. Weissenborn, T. Unterthiner, A. Mahendran, G. Heigold, J. Uszkoreit, A. Dosovitskiy, and T. Kipf, “Object- centric learning with slot attention,” 2020. [Online]. Available: https://arxiv.org/abs/2006.15055
-
[9]
T. Kipf, G. F. Elsayed, A. Mahendran, A. Stone, S. Sabour, G. Heigold, R. Jonschkowski, A. Dosovitskiy, and K. Greff, “Conditional object-centric learning from video,” 2022. [Online]. Available: https://arxiv.org/abs/2111.12594
-
[10]
Intuitive physics learning in a deep-learning model inspired by developmental psychology,
L. S. Piloto, A. Weinstein, P. Battaglia, and M. Botvinick, “Intuitive physics learning in a deep-learning model inspired by developmental psychology,”Nature human behaviour, vol. 6, no. 9, pp. 1257–1267, 2022
work page 2022
-
[11]
An algebraic theory to discriminate qualia in the brain,
Y . Ohmura, W. Shimaya, and Y . Kuniyoshi, “An algebraic theory to discriminate qualia in the brain,” 2023. [Online]. Available: https://arxiv.org/abs/2306.00239
-
[12]
Learning conditionally independent transformations using normal subgroups in group theory,
K. Nishitsunoi, Y . Ohmura, T. Komatsu, and Y . Kuniyoshi, “Learning conditionally independent transformations using normal subgroups in group theory,”arXiv preprint arXiv:2504.04490, 2025
-
[13]
Transformation cat- egorization based on group decomposition theory using parameter division,
T. Komatsu, Y . Ohmura, and Y . Kuniyoshi, “Transformation cat- egorization based on group decomposition theory using parameter division,”ICDL2026 under review, 2026
work page 2026
-
[14]
U-net: Convolutional networks for biomedical image segmentation,
O. Ronneberger, P. Fischer, and T. Brox, “U-net: Convolutional networks for biomedical image segmentation,” inInternational Confer- ence on Medical image computing and computer-assisted intervention. Springer, 2015, pp. 234–241
work page 2015
-
[15]
Third-party punishment by preverbal infants,
Y . Kanakogi, M. Miyazaki, H. Takahashi, H. Yamamoto, T. Kobayashi, and K. Hiraki, “Third-party punishment by preverbal infants,”Nature Human Behaviour, vol. 6, no. 9, pp. 1234–1242, 2022
work page 2022
-
[16]
Feature- based lie group transformer for real-world applications,
T. Komatsu, Y . Ohmura, K. Nishitsunoi, and Y . Kuniyoshi, “Feature- based lie group transformer for real-world applications,” 2025. [Online]. Available: https://arxiv.org/abs/2506.04668
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.