2L-LSH: A Locality-Sensitive Hash Function-Based Method For Rapid Point Cloud Indexing
Pith reviewed 2026-05-09 22:07 UTC · model grok-4.3
The pith
A two-step locality-sensitive hash divides bounding boxes and builds table structures to accelerate neighbor searches in large 3D point clouds.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
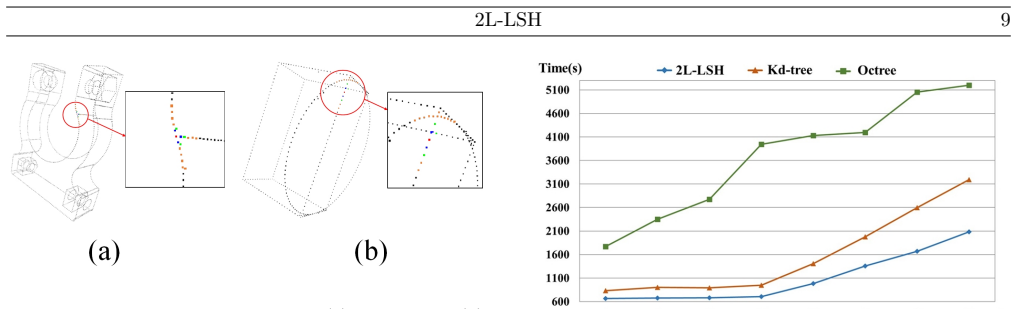
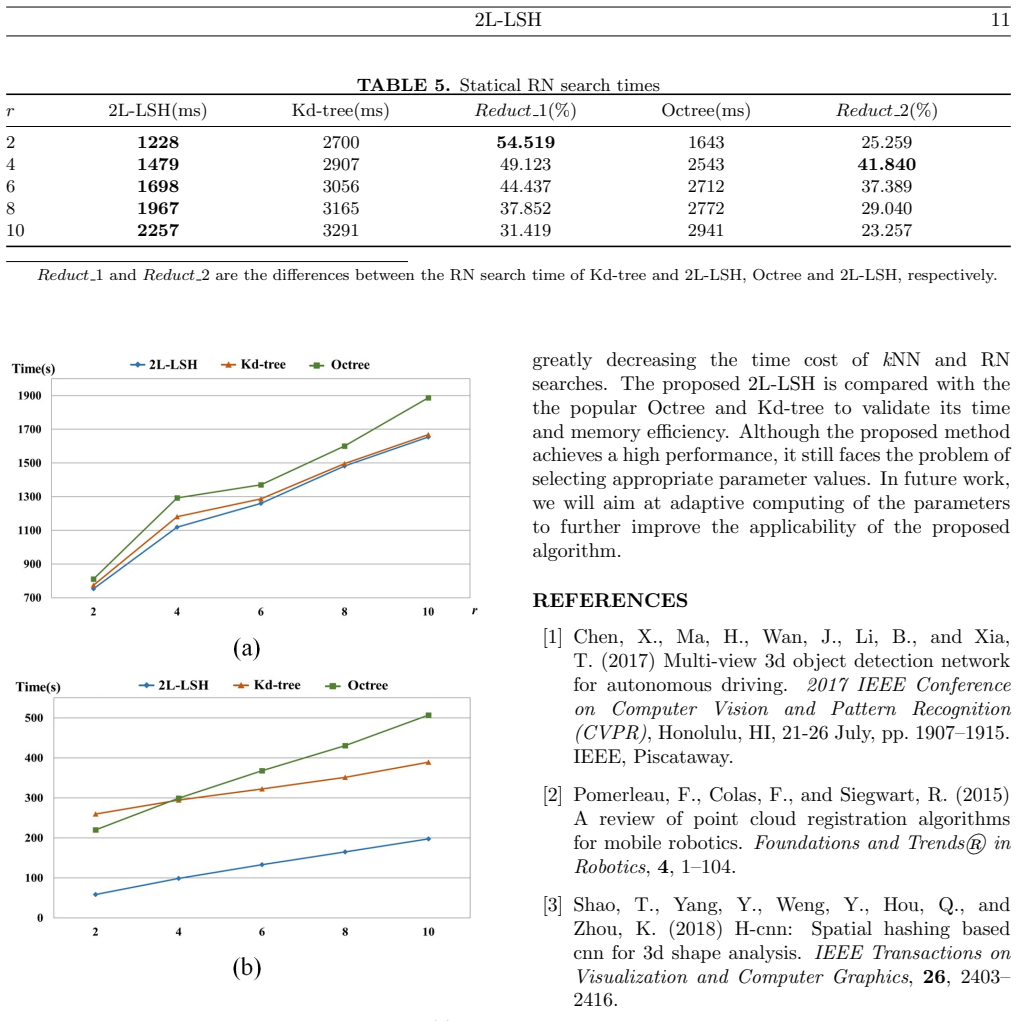
The 2L-LSH algorithm adopts a two-step hash function strategy, in which the first step divides the bounding box of the point cloud model and the second step constructs a generalized table-based data structure. The proposed 2L-LSH offers a highly efficient and accurate solution for fast neighboring points search in large-scale 3D point cloud models. When compared with Kd-tree and Octree, the time consumption of kNN search is 51.111% and 94.159% lower, respectively, while range-neighbor search time is 54.519% and 41.840% lower.
What carries the argument
The two-step hash function, with the first step partitioning the point-cloud bounding box and the second step populating a generalized table-based lookup structure.
If this is right
- kNN queries finish with 51% less time than Kd-tree and 94% less time than Octree on the tested models.
- Range-neighbor queries finish with 55% less time than Kd-tree and 42% less time than Octree.
- The same hash table supports both k-nearest-neighbor and fixed-radius neighbor retrieval without separate data structures.
- The method targets the common bottleneck of repeated local neighborhood access in point-cloud reconstruction, classification, and visualization.
Where Pith is reading between the lines
- The table-based second stage may lend itself to GPU parallelization more readily than recursive tree traversals.
- If the bounding-box division is made adaptive to local density, the same framework could handle streaming or time-varying point clouds.
- Because the structure is built from simple hash operations, it could be combined with approximate nearest-neighbor techniques already used in high-dimensional feature spaces.
Load-bearing premise
The two-step hashing preserves neighbor accuracy and works across point clouds of different densities and sizes without extra tuning that would erase the reported speed advantage.
What would settle it
Run 2L-LSH and the two baseline trees on a fresh, large, non-uniform point-cloud dataset while recording both wall-clock search time and the fraction of correct neighbors returned; if accuracy falls below the trees while the claimed time savings disappear, the central claim does not hold.
Figures








read the original abstract
The development of 3D scanning technology has enabled the acquisition of massive point cloud models with diverse structures and large scales, thereby presenting significant challenges in point cloud processing. Fast neighboring points search is one of the most common problems, which is frequently used in model reconstruction, classification, retrieval and feature visualization. Hash function is well known for its high-speed and accurate performance in searching high-dimensional data, which is also the core of the proposed 2L-LSH. Specifically, the 2L-LSH algorithm adopts a two-step hash function strategy, in which the popular step divides the bounding box of the point cloud model and the second step constructs a generalized table-based data structure. The proposed 2L-LSH offers a highly efficient and accurate solution for fast neighboring points search in large-scale 3D point cloud models, making it a promising technique for various applications in the field. The proposed algorithm is compared with the well-known methods including Kd-tree and Octree; the obtained results demonstrated that the proposed method outperforms Kd-tree and Octree in terms of speed, i.e. the time consumption of kNN search can be 51.111% and 94.159% lower than Kd-tree and Octree, respectively. And the RN search time can be 54.519% and 41.840% lower than Kd-tree and Octree, respectively.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes 2L-LSH, a two-level locality-sensitive hashing method for rapid point cloud indexing and neighbor search. The first hashing step partitions the bounding box of the input point cloud while the second step constructs a generalized table-based structure; the abstract reports that this yields 51.111% and 94.159% lower kNN search times than Kd-tree and Octree, respectively, together with 54.519% and 41.840% lower RN search times.
Significance. If the reported wall-clock reductions can be shown to hold while preserving search accuracy on standard benchmarks, the two-step LSH construction would supply a practical, hash-table-based alternative to tree-based spatial indexes for large-scale 3D data. The approach extends classical LSH ideas to point clouds but currently supplies no theoretical analysis or controlled experiments that would allow its contribution to be quantified.
major comments (3)
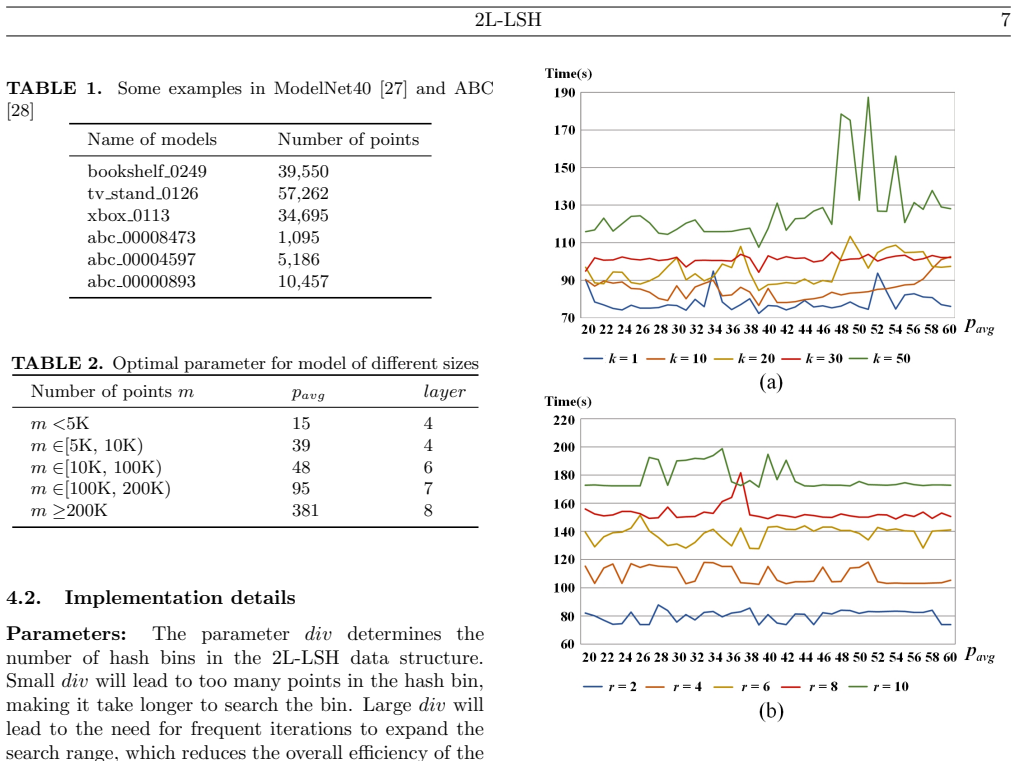
- [Abstract] Abstract: the headline performance figures (51.111% kNN reduction vs. Kd-tree, 94.159% vs. Octree, etc.) are stated without any accompanying accuracy metrics (recall, precision, or Hausdorff distance), dataset descriptions, query-set sizes, or implementation details, so the central claim that 2L-LSH is both faster and accurate cannot be evaluated from the manuscript.
- [Method] Method description (2L-LSH algorithm): the two-step hashing strategy is described only at the level of “partitions the bounding box” and “constructs a generalized table-based data structure”; no hash-function definitions, collision-probability analysis, bucket-size parameters, or pseudocode are supplied, preventing assessment of approximation quality or reproducibility.
- [Experiments] Experimental comparison: no tables, figures, or text report side-by-side accuracy results, timing distributions, error bars, or statistical tests against the Kd-tree and Octree baselines on identical point clouds and query workloads; without these the speed claims remain unverified and could reflect accuracy trade-offs or unequal tuning.
minor comments (2)
- [Abstract] Abstract: the phrase “the popular step” is unclear and appears to be a typographical error for “the first step” or “the partitioning step.”
- [Method] The manuscript would benefit from a diagram or pseudocode illustrating the two-level hash-table construction and from explicit statements of the hash-function family and parameter settings used.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We agree that the current manuscript requires additional details on accuracy, method specifics, and experimental results to fully support the claims. We will revise the manuscript to address these points.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline performance figures (51.111% kNN reduction vs. Kd-tree, 94.159% vs. Octree, etc.) are stated without any accompanying accuracy metrics (recall, precision, or Hausdorff distance), dataset descriptions, query-set sizes, or implementation details, so the central claim that 2L-LSH is both faster and accurate cannot be evaluated from the manuscript.
Authors: We agree that the abstract should provide context for evaluating both speed and accuracy. In the revised version, we will include dataset descriptions, query-set sizes, implementation details, and report accuracy metrics such as recall and precision alongside the performance figures. revision: yes
-
Referee: [Method] Method description (2L-LSH algorithm): the two-step hashing strategy is described only at the level of “partitions the bounding box” and “constructs a generalized table-based data structure”; no hash-function definitions, collision-probability analysis, bucket-size parameters, or pseudocode are supplied, preventing assessment of approximation quality or reproducibility.
Authors: We acknowledge that the method description is high-level. We will expand the method section in the revision to include the specific hash function definitions for each level, collision probability analysis, bucket-size parameters, and pseudocode for the 2L-LSH algorithm to support reproducibility and evaluation of approximation quality. revision: yes
-
Referee: [Experiments] Experimental comparison: no tables, figures, or text report side-by-side accuracy results, timing distributions, error bars, or statistical tests against the Kd-tree and Octree baselines on identical point clouds and query workloads; without these the speed claims remain unverified and could reflect accuracy trade-offs or unequal tuning.
Authors: We agree that side-by-side accuracy and timing results are needed for verification. The revised manuscript will add tables and figures showing accuracy metrics (recall, precision) together with timing results on the same point clouds and query workloads, including timing distributions with error bars and details on the experimental setup. revision: yes
Circularity Check
No circularity; algorithmic proposal with empirical timing results only.
full rationale
The manuscript presents a two-step LSH construction (bounding-box partition followed by table-based indexing) and reports wall-clock speedups versus Kd-tree/Octree on unspecified point clouds. No equations, parameter-fitting steps, or self-citations appear in the supplied text that would make any claimed result equivalent to its inputs by construction. The speed figures are direct experimental measurements, not predictions derived from fitted quantities or prior self-referential theorems. The derivation chain is therefore self-contained and non-circular.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Chen, X., Ma, H., Wan, J., Li, B., and Xia, T. (2017) Multi-view 3d object detection network for autonomous driving.2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, 21-26 July, pp. 1907–1915. IEEE, Piscataway
work page 2017
-
[2]
Pomerleau, F., Colas, F., and Siegwart, R. (2015) A review of point cloud registration algorithms for mobile robotics.Foundations and Trends®in Robotics,4, 1–104
work page 2015
-
[3]
Shao, T., Yang, Y., Weng, Y., Hou, Q., and Zhou, K. (2018) H-cnn: Spatial hashing based cnn for 3d shape analysis.IEEE Transactions on Visualization and Computer Graphics,26, 2403– 2416
work page 2018
-
[4]
Ji, C., Li, Y., Fan, J., and Lan, S. (2019) A novel simplification method for 3d geometric point cloud based on the importance of point.IEEE Access,7, 129029–129042
work page 2019
-
[5]
Cattai, T., Scarano, G., Corsi, M.-C., Bassett, D. S., Fallani, F. D. V., and Colonnese, S. (2021) Improving j-divergence of brain connectivity states by graph laplacian denoising.IEEE transactions on Signal and Information Processing over Networks,7, 493–508
work page 2021
-
[6]
Gao, J., Zhang, Y., Liu, Z., and Li, S. (2023) HDRNet: High-Dimensional Regression Network for Point Cloud Registration.Computer Graphics Forum,42, 33–46
work page 2023
-
[7]
S., Tan, Y., Kumar, R., Huber, D., and Hebert, M
Matei, B., Shan, Y., Sawhney, H. S., Tan, Y., Kumar, R., Huber, D., and Hebert, M. (2006) The Computer Journal, Vol. ??, No. ??, ???? 12S.R. W ang Rapid object indexing using locality sensitive hashing and joint 3d-signature space estimation. IEEE Transactions on Pattern Analysis and Machine Intelligence,28, 1111–1126
work page 2006
-
[8]
V., Truong-Hong, L., Laefer, D
Vo, A. V., Truong-Hong, L., Laefer, D. F., and Bertolotto, M. (2015) Octree-based region growing for point cloud segmentation.ISPRS Journal of Photogrammetry and Remote Sensing,104, 88– 100
work page 2015
-
[9]
Pinkham, R., Zeng, S., and Zhang, Z. (2020) Quicknn: Memory and performance optimization of kd tree based nearest neighbor search for 3d point clouds.2020 IEEE International Symposium on High Performance Computer Architecture (HPCA), San Diego, CA, 22-26 February, pp. 180–
work page 2020
-
[10]
Tarmissi, K. and Hamza, A. B. (2009) Information- theoretic hashing of 3d objects using spectral graph theory.Expert Systems with Applications,36, 9409–9414
work page 2009
-
[11]
Moura, P., Laber, E., Lopes, H., Mesejo, D., Pavanelli, L., Jardim, J., Thiesen, F., and Pujol, G. (2017) Lshsim: a locality sensitive hashing based method for multiple-point geostatistics.Computers & Geosciences,107, 49–60
work page 2017
-
[12]
Zheng, B., Zhao, X., Weng, L., Hung, N. Q. V., Liu, H., and Jensen, C. S. (2020) Pm-lsh: A fast and accurate lsh framework for high-dimensional approximate nn search.Proceedings of the VLDB Endowment,13, 643–655
work page 2020
-
[13]
Ahmed, F., Siyal, M. Y., and Abbas, V. U. (2010) A secure and robust hash-based scheme for image authentication.Signal Processing,90, 1456–1470
work page 2010
-
[14]
Lee, S. and Yoo, C. D. (2008) Robust video fin- gerprinting for content-based video identification. IEEE Transactions on Circuits and Systems for Video Technology,18, 983–988
work page 2008
-
[15]
Lee, S. H. and Kwon, K. R. (2012) Robust 3d mesh model hashing based on feature object.Digital Signal Processing,22, 744–759
work page 2012
-
[16]
Indyk, P. and Motwani, R. (1998) Approximate nearest neighbors: towards removing the curse of dimensionality.Proceedings of the thirtieth annual ACM symposium on Theory of computing, Dallas, TX, 24-26 May, pp. 604–613. ACM, New York
work page 1998
-
[17]
Dasgupta, A., Kumar, R., and Sarl´ os, T. (2011) Fast locality-sensitive hashing.Proceedings of the 17th ACM SIGKDD international conference on Knowledge discovery and data mining, San Diego, CA, 21-24 August, pp. 1073–1081. ACM, New York
work page 2011
-
[18]
(2019) Fast locality-sensitive hashing frameworks for approximate near neighbor search
Christiani, T. (2019) Fast locality-sensitive hashing frameworks for approximate near neighbor search. Similarity Search and Applications: 12th Interna- tional Conference, SISAP 2019, Newark, NJ, 2-4 October, pp. 3–17. Springer, Berlin
work page 2019
-
[19]
Dahlgaard, S., Knudsen, M., and Thorup, M. (2017) Fast similarity sketching.2017 IEEE 58th Annual Symposium on Foundations of Computer Science (FOCS), Berkeley, CA, 15-17 October, pp. 663–671. IEEE, Piscataway
work page 2017
-
[20]
Indyk, P. and Motwani, R. (2012) Approximate nearest neighbor: Towards removing the curse of dimensionality.Theory of Computing,8, 321–350
work page 2012
-
[21]
Pan, J. and Manocha, D. (2012) Bi-level locality sensitive hashing for k-nearest neighbor computation.2012 IEEE 28th International Conference on Data Engineering, Arlington, VA, 01-05 April, pp. 378–389. IEEE, Piscataway
work page 2012
-
[22]
(2016) Dynamic multidimensional index for large- scale cloud data.Journal of Cloud Computing,5, 1–11
He, J., Wu, Y., Dong, Y., Zhang, Y., and Zhou, W. (2016) Dynamic multidimensional index for large- scale cloud data.Journal of Cloud Computing,5, 1–11
work page 2016
-
[23]
Ming, Y. and Ruan, Q. (2012) Robust sparse bounding sphere for 3d face recognition.Image and Vision Computing,30, 524–534
work page 2012
-
[24]
Wang, H., Zhang, X., Zhou, L., Lu, X., and Wang, C. (2020) Intersection detection algorithm based on hybrid bounding box for geological modeling with faults.IEEE Access,8, 29538–29546
work page 2020
-
[25]
Kalman, D. (1996) A singularly valuable decompo- sition: the svd of a matrix.The college mathemat- ics journal,27, 2–23
work page 1996
-
[26]
Behley, J., Steinhage, V., and Cremers, A. B. (2015) Efficient radius neighbor search in three- dimensional point clouds.2015 IEEE International Conference on Robotics and Automation (ICRA), Seattle, WA, 26-30 May, pp. 3625–3630. IEEE, Piscataway
work page 2015
-
[27]
Wu, Z., Song, S., Khosla, A., Yu, F., Zhang, L., Tang, X., and Xiao, J. (2015) 3d shapenets: A deep representation for volumetric shapes.Proceedings of the IEEE conference on computer vision and pattern recognition, Boston, MA, 07-12 June, pp. 1912–1920. IEEE, Piscataway
work page 2015
-
[28]
Koch, S., Matveev, A., Jiang, Z., Williams, F., Artemov, A., Burnaev, E., Alexa, M., Zorin, D., and Panozzo, D. (2019) Abc: A big cad model dataset for geometric deep learning.Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, 15-20 June, pp. 9601–9611. IEEE, Piscataway. The Computer Journal, Vol. ??, No. ??...
work page 2019
-
[29]
H., Kim, C., Yu, K., and Heo, J
Han, S., Kim, S., Jung, J. H., Kim, C., Yu, K., and Heo, J. (2012) Development of a hashing-based data structure for the fast retrieval of 3d terrestrial laser scanned data.Computers & Geosciences,39, 1–10. The Computer Journal, Vol. ??, No. ??, ????
work page 2012
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.