Towards Adaptive Continual Model Merging via Manifold-Aware Expert Evolution
Pith reviewed 2026-05-08 12:12 UTC · model grok-4.3
The pith
Continual model merging avoids saturation and redundancy by evolving experts according to their alignments on a manifold.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MADE-IT shows that expert representations can be treated as subspaces on a manifold; a projection-based subspace affinity metric together with a distribution-aware adaptive threshold then drives autonomous expert evolution, while feature-subspace alignment supplies implicit routing that requires neither parameters nor training data.
What carries the argument
Projection-based subspace affinity metric paired with a distribution-aware adaptive threshold that governs expert addition, merging, and pruning; feature-subspace alignment supplies the routing rule.
If this is right
- Task sequences of arbitrary length can be absorbed without parameter saturation or routing overhead.
- Redundant experts are pruned automatically, especially in generic early layers, yielding smaller deployed models.
- Performance remains stable even when task order is randomized, indicating reduced sensitivity to sequence effects.
- No additional training data or optimization is needed for the routing mechanism.
- The same geometric rule can be applied inside both backbone and expert modules.
Where Pith is reading between the lines
- The same subspace-alignment logic could be tested on other modular architectures such as sparse transformers.
- If the manifold assumption holds across modalities, the method might extend to continual merging of vision-language models.
- Measuring how early-layer experts are pruned suggests that generic features stabilize faster than task-specific ones.
- An explicit test on non-classification tasks would check whether the adaptive threshold still balances diversity and parsimony.
Load-bearing premise
The geometric structure of expert representations remains stable enough that measured alignments can decide expert changes without creating new interference or suboptimal selections.
What would settle it
On a new long-horizon benchmark with many overlapping tasks, observe whether the number of active experts stays low while accuracy and robustness exceed strong baselines; a sharp rise in experts or drop in performance would falsify the claim.
Figures



read the original abstract
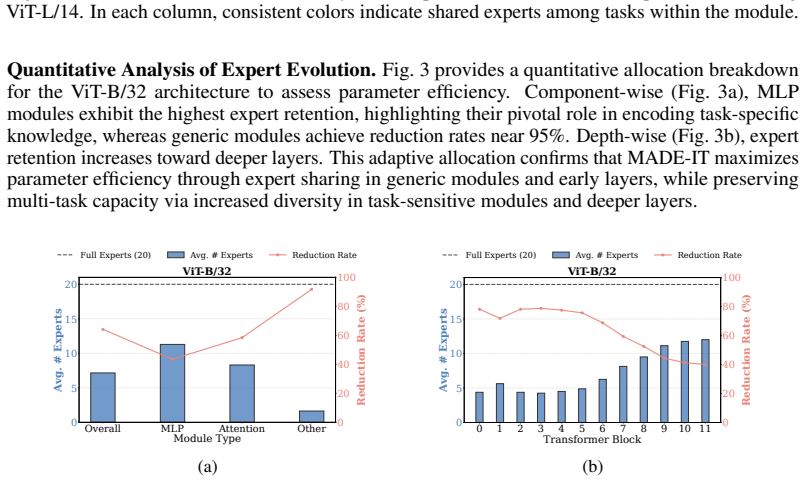
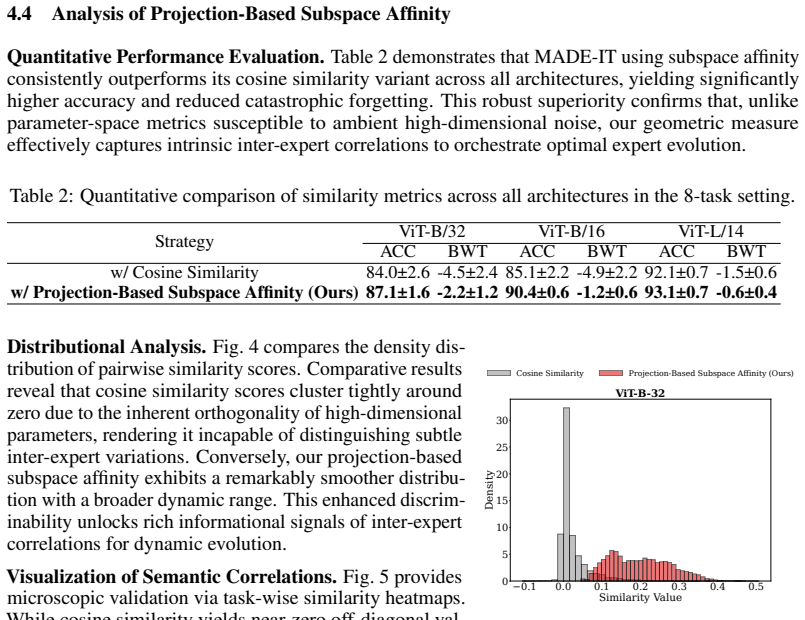
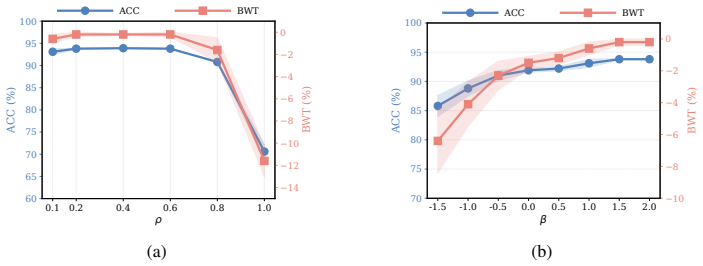
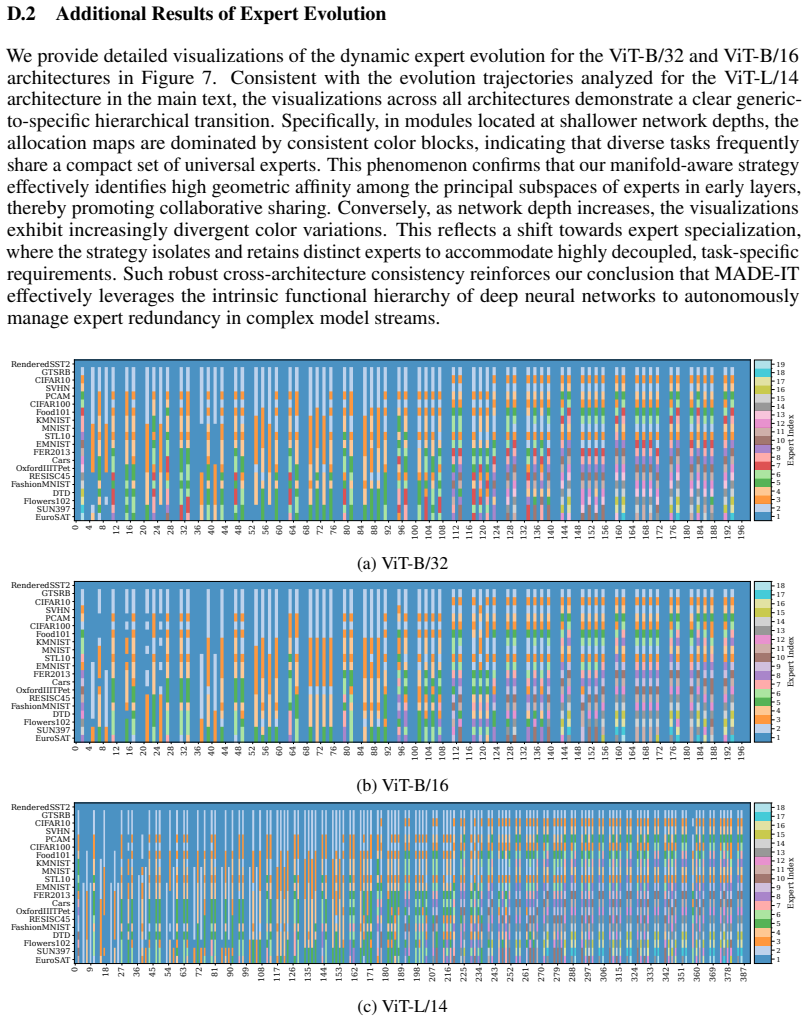
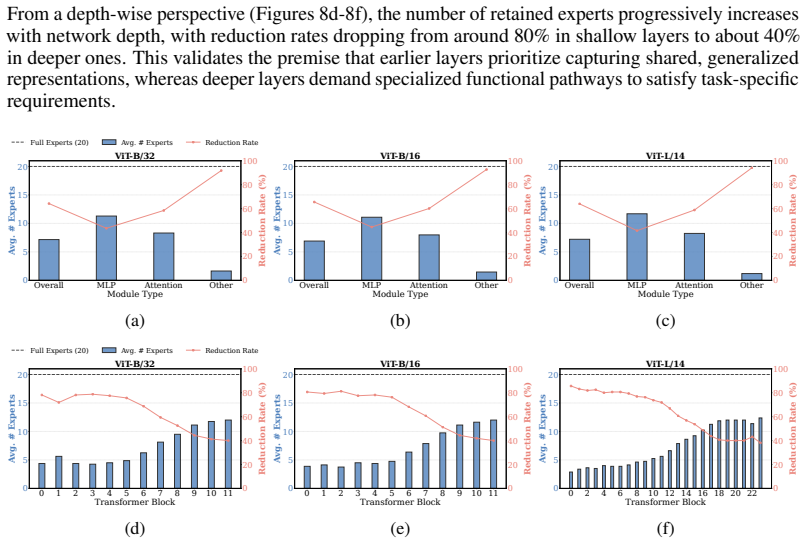
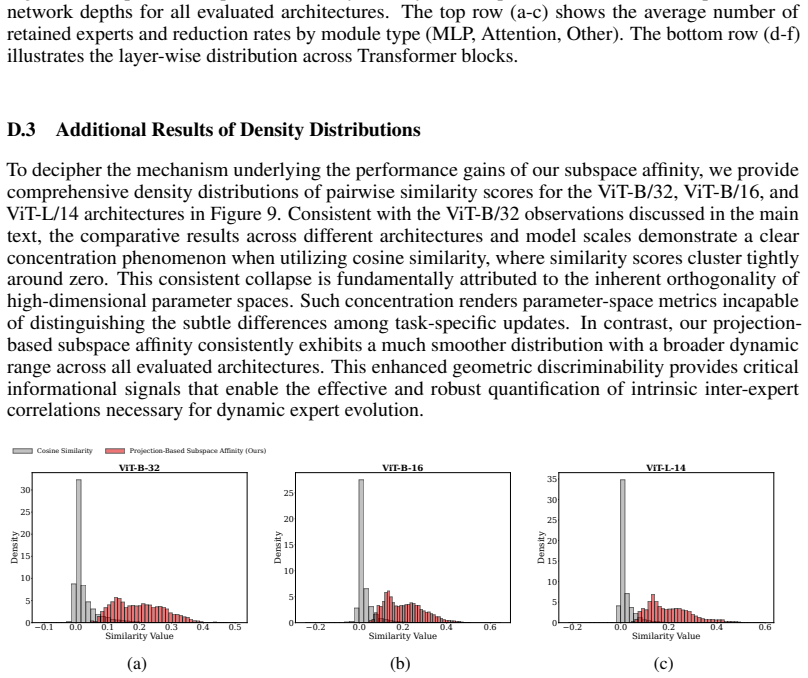
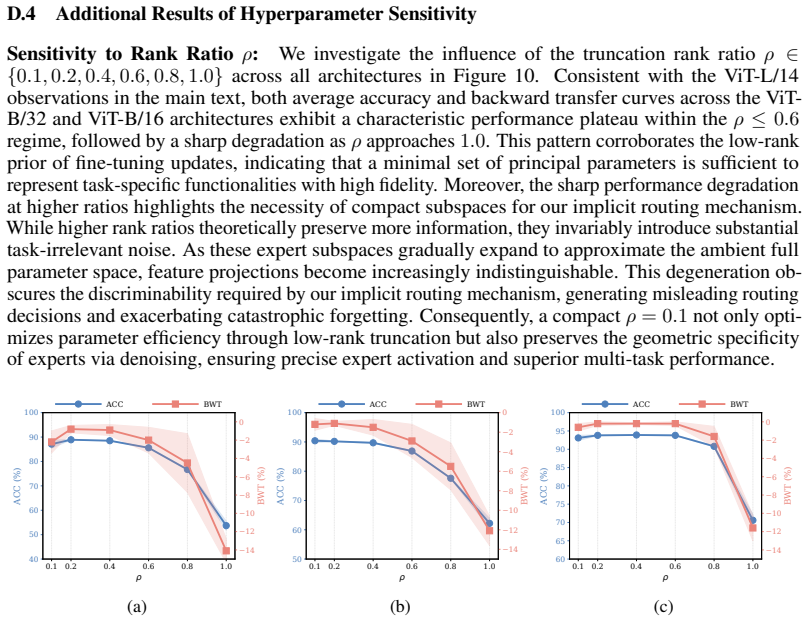
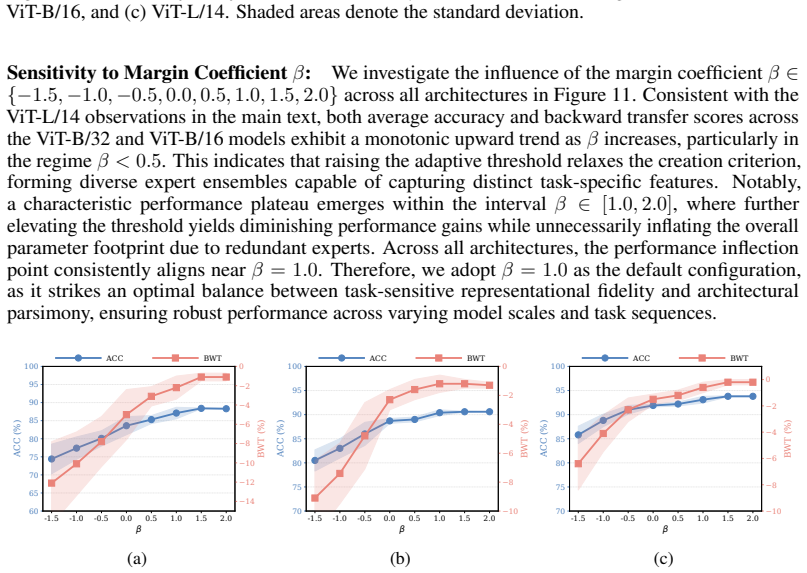
Continual Model Merging (CMM) sequentially integrates task-specific models into a unified architecture without intensive retraining. However, existing CMM methods are hindered by a fundamental saturation-redundancy dilemma: backbone-centric approaches face parameter saturation and representation interference within fixed capacities, whereas Mixture-of-Experts (MoE) variants resort to indiscriminate expansion, incurring expert redundancy and a routing bottleneck reliant on additional data-driven optimization. To resolve these challenges, we propose MADE-IT (Manifold-Aware Dynamic Expert Evolution and Implicit rouTing), an adaptive CMM method that orchestrates expert management and activation by grounding intrinsic expert representations in manifold geometry. We introduce a projection-based subspace affinity metric coupled with a distribution-aware adaptive threshold mechanism to guide autonomous expert evolution, harmonizing diversity with architectural parsimony. Furthermore, to bypass parameterized gating networks, we design a data-free and training-free implicit routing mechanism that activates experts via feature-subspace alignment. Extensive experiments demonstrate that MADE-IT consistently outperforms strong baselines in accuracy and robustness across long-horizon and shuffled task sequences, while significantly pruning redundant experts, particularly within generic modules and early layers.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MADE-IT (Manifold-Aware Dynamic Expert Evolution and Implicit rouTing), a method for Continual Model Merging (CMM) that addresses the saturation-redundancy dilemma in backbone-centric and MoE-based approaches. It grounds expert representations in manifold geometry via a projection-based subspace affinity metric paired with a distribution-aware adaptive threshold to guide autonomous expert evolution, and introduces a data-free, training-free implicit routing mechanism based on feature-subspace alignment. The authors claim that MADE-IT consistently outperforms strong baselines in accuracy and robustness across long-horizon and shuffled task sequences while significantly pruning redundant experts, particularly in generic modules and early layers.
Significance. If the central claims are substantiated with rigorous evidence, the work could meaningfully advance continual learning by providing a geometry-driven, adaptive framework for model merging that harmonizes capacity and performance without retraining or parameterized routing optimization. The implicit routing and manifold-aware pruning represent potentially impactful ideas for efficient deployment of merged models. However, the absence of verifiable quantitative support in the manuscript text limits assessment of real-world significance.
major comments (2)
- Abstract: The central claim that 'extensive experiments demonstrate that MADE-IT consistently outperforms strong baselines in accuracy and robustness... while significantly pruning redundant experts' is presented without any numerical results, error analysis, baseline details, tables, or figures. This is load-bearing for the contribution, as the method's effectiveness cannot be evaluated from the provided text.
- Method (description of projection-based subspace affinity and adaptive threshold): No derivation, bound, or analysis is supplied showing that the subspace affinity metric remains faithful under high-dimensional noise, poorly conditioned manifolds, or gradual task drift, nor when the distribution-aware threshold avoids false merges or retains interfering experts. This directly underpins the implicit routing and the claimed balance of diversity with parsimony.
minor comments (1)
- Abstract: The parenthetical expansion of the MADE-IT acronym is clear but could be repeated on first use in the main text for standalone readability.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript. We address each major comment below and indicate the revisions we will incorporate to improve the clarity and rigor of the presentation.
read point-by-point responses
-
Referee: Abstract: The central claim that 'extensive experiments demonstrate that MADE-IT consistently outperforms strong baselines in accuracy and robustness... while significantly pruning redundant experts' is presented without any numerical results, error analysis, baseline details, tables, or figures. This is load-bearing for the contribution, as the method's effectiveness cannot be evaluated from the provided text.
Authors: We acknowledge that the abstract summarizes the experimental outcomes qualitatively without specific numerical values. While this is common in machine learning abstracts due to length constraints, we agree that including key quantitative highlights would allow readers to immediately assess the strength of the claims. In the revised version, we will update the abstract to report concrete metrics such as average accuracy improvements (e.g., +X% over baselines), pruning ratios, and robustness gains across task sequences, with explicit references to the corresponding tables and figures in the experimental section. revision: yes
-
Referee: Method (description of projection-based subspace affinity and adaptive threshold): No derivation, bound, or analysis is supplied showing that the subspace affinity metric remains faithful under high-dimensional noise, poorly conditioned manifolds, or gradual task drift, nor when the distribution-aware threshold avoids false merges or retains interfering experts. This directly underpins the implicit routing and the claimed balance of diversity with parsimony.
Authors: The referee is correct that the manuscript does not provide a formal derivation, theoretical bounds, or explicit robustness analysis for the projection-based subspace affinity metric and the distribution-aware adaptive threshold under conditions such as high-dimensional noise or task drift. The current work emphasizes the geometric motivation and empirical validation through experiments on long-horizon and shuffled sequences. To address this gap, we will add a dedicated paragraph and supporting synthetic experiments in the revised method section (or appendix) analyzing the metric's behavior under noise and drift, including its ability to avoid false merges. This will strengthen the justification for the implicit routing mechanism while preserving the paper's empirical focus. revision: partial
Circularity Check
No significant circularity; method introduces new mechanisms without self-referential reductions
full rationale
The abstract and method description present MADE-IT as a novel approach grounding expert representations in manifold geometry via a projection-based subspace affinity metric and distribution-aware adaptive threshold for autonomous evolution and implicit routing. No equations, derivations, or self-citations are provided that reduce any claimed prediction or result to fitted inputs or prior author work by construction. The outperformance claims rest on experimental results rather than a closed derivation loop. The derivation chain is self-contained, introducing independent geometric and adaptive components without evident self-definition, fitted-input renaming, or load-bearing self-citation.
Axiom & Free-Parameter Ledger
free parameters (1)
- distribution-aware adaptive threshold
axioms (1)
- domain assumption Intrinsic expert representations lie on a manifold amenable to subspace affinity measurement for guiding evolution.
invented entities (1)
-
Implicit routing via feature-subspace alignment
no independent evidence
Reference graph
Works this paper leans on
-
[1]
”The Biblical Sources of Modern Hebrew Syntax
Fine-tuning pretrained language models: Weight initializations, data orders, and early stopping.arXiv preprint arXiv:2002.06305(2020). 10 Guodong Du, Junlin Lee, Jing Li, Runhua Jiang, Yifei Guo, Shuyang Yu, Hanting Liu, Sim K Goh, Ho-Kin Tang, Daojing He, et al. 2024. Parameter competition balancing for model merging. In Advances in Neural Information Pr...
-
[2]
InConference on Uncertainty in Artificial Intelligence
Averaging weights leads to wider optima and better generalization. InConference on Uncertainty in Artificial Intelligence. Xisen Jin, Xiang Ren, Daniel Preotiuc-Pietro, and Pengxiang Cheng. 2023. Dataless knowledge fusion by merging weights of language models. InInternational Conference on Learning Representations. Sangwon Jung, Hongjoon Ahn, Sungmin Cha,...
work page 2023
-
[3]
Communication-efficient learning of deep networks from decentralized data. InArtificial Intelligence and Statistics. PMLR, 1273–1282. Yuval Netzer, Tao Wang, Adam Coates, Alessandro Bissacco, Baolin Wu, Andrew Y Ng, et al. 2011. Reading digits in natural images with unsupervised feature learning. InNIPS Workshop on Deep Learning and Unsupervised Feature L...
-
[4]
Model merging in LLMs, MLLMs, and beyond: Methods, theories, applications, and opportunities.Comput. Surveys58, 8 (2026), 1–41. Enneng Yang, Anke Tang, Li Shen, Guibing Guo, Xingwei Wang, Xiaochun Cao, and Jie Zhang
work page 2026
-
[5]
InAdvances in Neural Information Processing Systems
Continual model merging without data: dual projections for balancing stability and plasticity. InAdvances in Neural Information Processing Systems. Enneng Yang, Zhenyi Wang, Li Shen, Shiwei Liu, Guibing Guo, Xingwei Wang, and Dacheng Tao
-
[6]
InInternational Conference on Learning Representations
AdaMerging: Adaptive model merging for multi-task learning. InInternational Conference on Learning Representations. 13 Da-Wei Zhou, Hai-Long Sun, Han-Jia Ye, and De-Chuan Zhan. 2024. Expandable subspace en- semble for pre-trained model-based class-incremental learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 23...
work page 2024
-
[7]
This confirms thatA S operates as a scale-invariant metric for subspace proximity
+ Tr(P2 2)−2 Tr(P 1P2)).(17) Utilizing the idempotence (P2 =P) and the property thatTr(P) = rank(P) =r: d2 C = 1 2(r+r−2 Tr(P 1P2)) =r−Tr(P 1P2).(18) By applying the Trace-Frobenius Lemma, we substituteTr(P 1P2) =∥ ˜S⊤ 1 ˜S2∥2 F : d2 C =r− ∥ ˜S⊤ 1 ˜S2∥2 F .(19) Substituting the definition AS = 1 r ∥ ˜S⊤ 1 ˜S2∥2 F , we obtain AS = 1− 1 r d2 C, completing t...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.