Score-Repellent Monte Carlo: Toward Efficient Non-Markovian Sampler with Constant Memory in General State Spaces
Pith reviewed 2026-05-08 12:06 UTC · model grok-4.3
The pith
Score-Repellent Monte Carlo reduces asymptotic sampling variance as O(1/α) using constant-memory history summaries in general state spaces.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
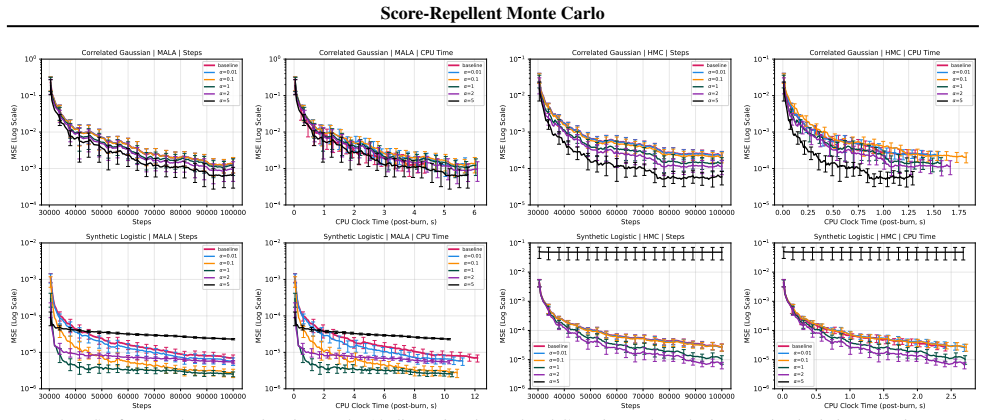
Score-Repellent Monte Carlo (SRMC) summarizes trajectory history by a running average of score evaluations, which is converted into a surrogate target through an exponential score tilt controlled by parameter α. Any base kernel targeting the original distribution can be applied to the current surrogate, while the history is updated online. Using stochastic approximation with controlled Markovian noise, the coupled system is shown to converge almost surely with a joint central limit theorem. In identified regimes, the asymptotic covariance of the Monte Carlo estimators decreases with increasing α at a rate of O(1/α), extending near-zero-variance properties from finite-state cases to general 0
What carries the argument
The exponential score tilt applied to a running average of score evaluations, which generates a normalization-free surrogate target distribution that repels the sampler from previously visited regions.
Load-bearing premise
The assumptions required for the stochastic approximation analysis with controlled Markovian noise hold for the chosen base kernel and target distribution, allowing the coupled history recursion and estimators to converge as claimed.
What would settle it
Simulations that track the asymptotic variance of estimators while varying α and checking whether it scales as O(1/α) in the regimes claimed; observing no such decrease or an increase instead would falsify the variance reduction claim.
Figures









read the original abstract
History-dependent sampling can reduce long-run Monte Carlo variance by discouraging redundant revisits, but existing schemes typically encode history through empirical measure on finite state spaces, which is infeasible in high-dimensional discrete configuration spaces or ill-posed in continuous domains. We propose Score-Repellent Monte Carlo (SRMC) framework that summarizes trajectory history by a running average of score evaluations in $\mathbb{R}^d$, where $d$ is the dimension of the score and state representation. This history is converted into a surrogate target through an exponential score tilt, indexed with $\alpha$ that represents the strength of repellence in controlling the magnitude of the history-based repulsion. The surrogate family is normalization-free in the standard MCMC sense, yielding a generic wrapper: at each iteration, any base kernel targeting $\pi$ can instead be run on the current surrogate $\pi_{\theta_n}$ while the history is updated online. We analyze the coupled evolution of the history recursion and Monte Carlo estimators using stochastic approximation with controlled Markovian noise, establishing almost sure convergence and a joint central limit theorem. We further identify regimes in which the asymptotic covariance decreases as $\alpha$ increases, with scaling $O(1/\alpha)$, extending the near-zero-variance effect of finite-state history-dependent samplers to general state spaces with constant memory. Experiments on continuous targets and discrete energy-based models demonstrate improved estimator variance and mode coverage, while retaining $O(d)$ memory usage and modest per-iteration overhead.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Score-Repellent Monte Carlo (SRMC), a constant-memory non-Markovian sampler for general state spaces. History is summarized by a running average θ_n of score evaluations; this is used to form a normalization-free surrogate target π_θn via an exponential tilt of strength α. Any base kernel targeting the original π is instead applied to the current surrogate, with θ_n updated online. The coupled (θ_n, Monte Carlo estimator) recursion is analyzed via stochastic approximation with controlled Markovian noise, yielding almost-sure convergence and a joint central limit theorem. Regimes are identified in which the asymptotic covariance of the estimator decays as O(1/α). Experiments on continuous targets and discrete energy-based models report improved estimator variance and mode coverage while retaining O(d) memory.
Significance. If the stochastic-approximation analysis and the O(1/α) covariance scaling hold under the stated conditions, the work supplies a concrete mechanism for extending finite-state history-dependent variance reduction to general (including continuous) spaces with fixed memory cost. The joint CLT for the coupled recursion and the normalization-free surrogate construction are technically useful; the former enables rigorous asymptotic analysis of the non-Markovian scheme, while the latter permits any existing base kernel to be wrapped without redesign.
major comments (2)
- [Stochastic approximation analysis] The O(1/α) decay of asymptotic covariance (abstract and analysis section) is obtained by showing that the α-dependent tilt perturbation vanishes at the required rate inside the controlled-noise CLT. This step presupposes that the base kernel satisfies uniform ergodicity and moment bounds on the score that are independent of both α and the current θ_n. These conditions are not automatically inherited from a generic kernel targeting π and may fail when the score is unbounded or the target has heavy tails; explicit verification (or additional assumptions) for the kernels used in the experiments is therefore load-bearing for the central scaling claim.
- [Analysis of coupled recursion] The joint central limit theorem for the coupled recursion (analysis section) relies on the controlled Markovian noise framework applying to the history update and the Monte Carlo estimator. Without a self-contained statement of the precise ergodicity and moment conditions that guarantee the CLT (or a reference to a theorem that directly covers the α-dependent surrogate), it is difficult to confirm that the O(1/α) regime is attained for the targets and kernels considered.
minor comments (2)
- [Abstract] The abstract states that the surrogate family is 'normalization-free in the standard MCMC sense'; a brief sentence clarifying that the normalizing constant of π_θn need not be evaluated (because the base kernel is only required to target it up to proportionality) would help readers unfamiliar with the construction.
- [Introduction / Notation] Notation for the score dimension versus state dimension is introduced as 'd is the dimension of the score and state representation.' Consistent use of a single symbol (or explicit distinction) throughout the text would avoid ambiguity when memory cost is stated as O(d).
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments. The recognition of the technical contributions of the normalization-free surrogate and the joint CLT analysis is appreciated. We address each major comment below and indicate the revisions that will be incorporated.
read point-by-point responses
-
Referee: [Stochastic approximation analysis] The O(1/α) decay of asymptotic covariance (abstract and analysis section) is obtained by showing that the α-dependent tilt perturbation vanishes at the required rate inside the controlled-noise CLT. This step presupposes that the base kernel satisfies uniform ergodicity and moment bounds on the score that are independent of both α and the current θ_n. These conditions are not automatically inherited from a generic kernel targeting π and may fail when the score is unbounded or the target has heavy tails; explicit verification (or additional assumptions) for the kernels used in the experiments is therefore load-bearing for the central scaling claim.
Authors: We agree that uniform ergodicity and α-independent moment bounds on the score are load-bearing assumptions for the O(1/α) covariance claim. The manuscript states these as part of the controlled Markovian noise framework applied to the base kernel. For the reported experiments, MALA is used on continuous targets satisfying standard smoothness and strong log-concavity conditions that guarantee geometric ergodicity, while the discrete energy-based models employ local Gibbs kernels that are ergodic on finite spaces. We will add a dedicated paragraph in the analysis section that explicitly lists the required kernel conditions, supplies references or brief verification for the experimental kernels, and discusses the additional restrictions needed for heavy-tailed targets. This will make the assumptions transparent without altering the main results. revision: yes
-
Referee: [Analysis of coupled recursion] The joint central limit theorem for the coupled recursion (analysis section) relies on the controlled Markovian noise framework applying to the history update and the Monte Carlo estimator. Without a self-contained statement of the precise ergodicity and moment conditions that guarantee the CLT (or a reference to a theorem that directly covers the α-dependent surrogate), it is difficult to confirm that the O(1/α) regime is attained for the targets and kernels considered.
Authors: The joint CLT is obtained by embedding the α-dependent surrogate within the controlled Markovian noise setting, where the perturbation induced by θ_n is shown to vanish at the appropriate rate. We will revise the analysis section to include a self-contained statement of the precise ergodicity and moment conditions (uniform geometric ergodicity of the base kernel together with bounded second moments of the score that are uniform in θ_n over a compact set containing the limit). We will also cite the specific theorem from the controlled-noise literature that is applied and briefly verify that the α-dependent tilt satisfies the required Lipschitz and boundedness conditions. These additions will allow direct confirmation that the O(1/α) regime holds under the stated assumptions for the targets considered. revision: yes
Circularity Check
No significant circularity; derivation is self-contained stochastic approximation analysis
full rationale
The paper defines SRMC via a running score average θ_n converted to an α-indexed exponential tilt surrogate π_θn, runs any base kernel on the surrogate, and analyzes the coupled (θ_n, estimator) recursion via stochastic approximation with controlled Markovian noise to obtain a.s. convergence and a joint CLT. The O(1/α) asymptotic covariance scaling is identified as a consequence of that CLT under stated regimes and assumptions on the base kernel (uniform ergodicity, moment bounds independent of α and θ_n). No step reduces by the paper's own equations to a fitted parameter renamed as prediction, a self-definitional construct, or a load-bearing self-citation chain; the central claims remain independent of the experimental data used for illustration. The derivation therefore does not collapse to its inputs by construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- alpha
axioms (2)
- domain assumption Any base kernel targeting the original distribution pi can be run on the current surrogate pi_theta_n
- domain assumption Stochastic approximation with controlled Markovian noise applies to the joint evolution of history recursion and Monte Carlo estimators
invented entities (1)
-
surrogate target pi_theta_n
no independent evidence
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.